
Does vibe coding risk destroying the Open Source ecosystem? According to a pre-print paper by a number of high-profile researchers, this might indeed be the case based on observed patterns and some modelling. Their warnings mostly center around the way that user interaction is pulled away from OSS projects, while also making starting a new OSS project significantly harder.
“Vibe coding” here is defined as software development that is assisted by an LLM-backed chatbot, where the developer asks the chatbot to effectively write the code for them. Arguably this turns the developer into more of a customer/client of the chatbot, with no requirement for the former to understand what the latter’s code does, just that what is generated does the thing that the chatbot was asked to create.
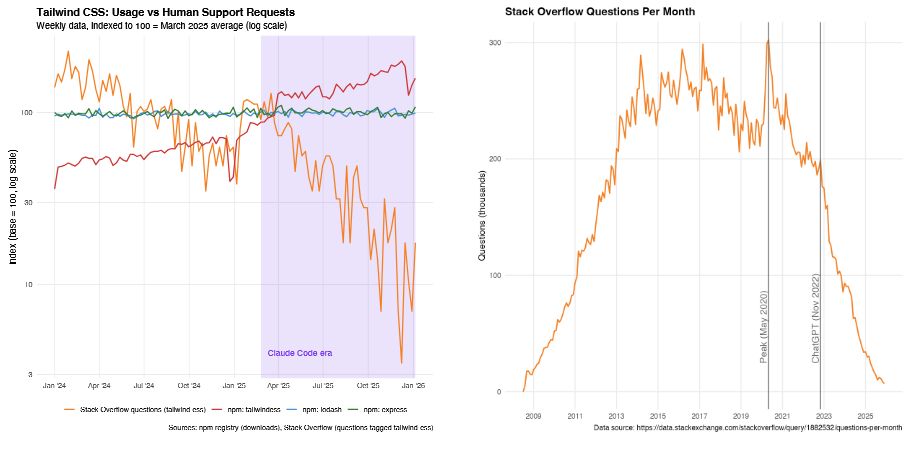
This also removes the typical more organic selection process of libraries and tooling, replacing it with whatever was most prevalent in the LLM’s training data. Even for popular projects visits to their website decrease as downloads and documentation are replaced by LLM chatbot interactions, reducing the possibility of promoting commercial plans, sponsorships, and community forums. Much of this is also reflected in the plummet in usage of community forums like Stack Overflow.
If we consider this effect of ‘AI-assisted’ software development to be effectively the delegating of the actual engineering and development to the statistical model of an LLM, then it’s easy to see the problems here. The LLM will not interact with the developers of a library or tool, nor submit usable bug reports, or be aware of any potential issues no matter how well-documented.
Although the authors of this paper are still proponents of ‘AI technology’, their worries seem well-warranted, even if it’s unclear at this point how big the impact is going to be. Software ecosystems like those involving JavaScript, Python, and web technologies are likely to suffer the impact from vibe coding first, as their audiences appear to be more into such vibes, and the training sets were largest.
It’s also a topic that is highly controversial, ever since Microsoft launched GitHub Copilot in 2021. Since then we saw reports in 2024 that ‘vibe coding’ using Copilot and similar chatbots offered no real benefits unless adding 41% more bugs is a measure of success.
By the time we hit 2025, we can observe an even more negative mood, with LLM chatbots in general being accused of degrading the cognitive skills of those using them, vibe coding chatbots reducing productivity by 19%, and experienced developers who gave them a whirl subsequently burning them to the ground in scathing reviews.
All of which reinforces the notion that perhaps this ‘AI revolution’ is more of a stress test for human intelligence than an actual boost to productivity or code quality. Despite the authors pitching the idea that OpenAI or Google could toss a few cents the way of OSS projects when their code is being used, the comparison with Spotify is painfully apt, since about 80% of artists on Spotify rarely have their tracks played and thus receive basically no money for their efforts.
With an LLM statistical model we know with extremely high likelihood that only the dependencies that are most prevalent in the training data set will realistically be used for the output, and we expect that we’ll see something similar happen with this vibe coding compensation scheme.
Even today we can already observe many negative effects from ‘AI slop’ in software development. Whether it’ll be something that’ll choke the life out of the entire OSS ecosystem remains to be seen, but it is hard to envision a bright vibe coding future.














I have been programming since i was 13. QBASIC, VB6, C, python, java, javascript, shell/batch script i learned them all. Then i gradually got into embedded systems, programming microcontrollers and eventually designing hardware itself. After i got employed, i starting programming less and less.
All my life i thought I enjoyed programming, but ever since LLMs released and got good enough to write code for me i have realised that i didn’t really enjoy coding much, it was always what the code could do for me, that was enjoyable. Making code draw pixels on the screen or making it output an exact pwm to drive a FET in a switching converter. That’s what is enjoyable. Not the syntax or worrying about the bitmask or anything else.
This is also why i never really enjoyed high level software too much. A lot of it was always about babysitting the framework/library instead of actually doing things. So much boilerplate, so many “let’s make this into a module in case we need to swap the implementation). I could never tolerate working in overly object oriented (enterprise “quality” code, if you will) codebases.
Still i will not lie, a part of me hates LLMs for taking away programming from me. It was a peaceful and soliditary activity that i could enjoy on the weekends. Something that reminded me “the process matters too, not just the product in the end” and use my brain. Now I get a sad feeling when I’m writing code telling me “you could just make the LLM do this, do you enjoy wasting time?”. You can’t enjoy when you’re mind is telling you that.
PS: ask LLMs to write any kind of close to the metal code with a lot of interrupts…. Yeah it’ll fail spectacularly. Kinda fun to see
I started coding on a TRS-80 and later a Commodore 64. When I got my first “real job” I did a lot of coding in C and really enjoyed it. But somewhere in the late 90’s and early 2000’s my job transitioned to mostly just gluing together other people’s code and libraries. Then it was mostly using Google to find specific solutions to using some API or another. LLMs for me have just replaced Google to get specific answers without having to search through a lot of Stackoverflow posts.
I’d like to get back into doing more of a “full stack” type of development, even if it was for personal projects. But I really don’t have time for it. And I’m lazy. So I think I’m going to try writing up detailed specs for what I want and turn Claude Code loose on it to see what happens.
I have asked agent implement a game which I sketched 12 years ago. Emits the most boring part and save a lot of time for me.
Just remember that efficiency itself is evil, and the most efficient world is probably hell. Wasting time is therefore a moral good. Never optimize yourself unless you intend to lose your humanity.
Efficiency isn’t evil, it’s just fragile. Chasing efficiency rarely works or lasts, because it results in unintended consequences and systems that break down as soon as you let them run free as they would. Efficient systems tend to be high maintenance, which defeats their point.
I think he meant “trying to be an efficient HUMAN being”, while you’re talking about efficient machine. Trying to be an efficient human is like try to be a machine, that’s why he said unless you intend to lose your humanity
Trying to be an efficient human begs the question about what humans are supposed to do. I find myself most efficient at doing exactly nothing of importance.
An efficient system will break if any detail of it departs from the script. Every part must be 100% perfect, even though its builder almost certainly wasn’t. What could possibly go wrong? Give me a sloppy, inefficient system any day.
The sloppier system would be no computer aided systems at all, humans doing the work. As we are demonstrably worse than a computer. I highly doubt you really want that.
But if you want a sloppy computer system then vibe coded slop is exactly what you seek it seems?
Then we can focus on efficiency operations on the DC side treating it like an electrical system and streamline from hardware up.
Avoiding the extensive resource mess created by endless production of consumer crap gadgets for hobbyists to eventually just dispose of
We should start making computers powered by vacuum tubes again.
Fragility and efficiency aren’t the same thing.
Complexity is mostly not the result of seeking efficiency.
Given human nature, it’s more often about preventing efficiency, to keep money flowing in the ‘right’ directions.
Which isn’t to say the case you reference doesn’t exist (adding complexity to get efficiency, e.g. Blown engines), just that something that straightforward is the exception in human related things.
You do want efficiency in your life, in many respects, it gets useless ‘drags’ of people out of your life.
KISS is never truer.
IIRC you’re on a campus.
Can’t be done, the drags have tenure.
I grew up on a campus, can’t get me near one now.
The BS I saw as a kid.
That’s not the normal world.
Tenured sociopaths dominate academia.
The idea that humans loose their humanity as they strive for efficiency is absurd. Evolution strives for efficiency, always. It’s not perfect but efficient systems win, biological or synthetic, just ask thermodynamics.
@Danny Grogan
Yes, evolution is real and it is evil, even on a molecular level. It is the violence at the heart of the universe.
Complexity can be the result of seeking efficiency.
* Solving a local problem efficiently at the expense of the whole
* A programmers ego, experience, or need for job security
* Restricting a problem too early or too late
* Using an incorrect measure of efficiency for the problem.
A weird one that happens with groups is that removing efficiency, can be at the expense of reducing connection and purpose – no need to have group discussions means people don’t appreciate what others are doing or know them which can reduce friction.
Tenured sociopaths … Maybe tenured narcissists but the amount of tenured staff I think is reducing
Complexity is the result of refinement, where refinement is seeking some optimum by deliberate incremental improvements that add finer and finer details to complete many simultaneous and often conflicting goals, which leads to fragility.
Like replacing the mechanical distributor of a car engine with completely electronic ignition. It’s cheaper, more efficient, less maintenance – but it has no “failure mode”. It either works or it stops entirely. It’s fragile.
With complexity, you have to remember the difference between noise and complexity. Both look very detailed, but complexity means intricate interdependence of the parts of the system directed at some goal. Noise on the other hand is an uncorrelated mess that looks complicated but reveals no pattern, where you can remove or add more noise as you wish and the fundamental operation or outcome doesn’t change.
Your example of a college environment is more an example of noise: the system has evolved to avoid collaboration of parts because that makes it better at absorbing money. You can add or remove people from the system and its operation doesn’t change. It’s actually an example of a sloppy system that is very good and robust at doing what it’s doing because it doesn’t care about seeking efficiency or defining goals. What it’s doing is simply the result of the necessary goal of any system, which is to sustain itself.
Nope. Evolution seeks all possible outcomes because it has no set goal. What remains is what can remain, which creates the “illusion” of efficiency, because the apparent goal is defined after the fact.
It’s like watching a river flow down a valley and thinking how efficient water is because it found the precise optimal path through the landscape – forgetting that it was the water that carved the valley into the hills in the first place.
The only efficient code is self-sustaining code. Beyond additive features or shifts in industry standards, code should never require an update. In responsive design and software, if it isn’t autonomous, it’s an architectural failure.
What kind of pseudo-philosophical nonsense is this? I hope this is some poorly thought out trolling, as humans surely can’t be this lost and confused
There is nothing “lost and confused” about hating the fundamental mechanism of violence. I am not obligated to accept the nature of the universe as it is. Optimization is a meat grinder and this place is evil. Hope that helps.
you can’t just conflate efficiency and violence; “the nature of the universe” is being gravitating rocks and nebulae, and optimization is only in favor of a chosen aspect, there is nothing inherently evil in optimization, whereas unrestrained productivism is only a possible use of it
@synonymous
https://en.wikipedia.org/wiki/Maximum_power_principle
It is the actual nature of the universe, though.
Anything that exists is the nature of the universe, though. Efficient or not.
Idle hands make the devil’s work.
I have used llm to aid in traditional coding and vibe coding. I think the problem with using it without knowledge or background knowledge is the problem. AI used as an assistive tool in a knowledgeable programmers hands is a good thing. But… Much like the early visual programming space that opened up development to the unknowledgeable fiddlers we get garbage coding. It might be obvious garbage code that does not run or it might be logic bomb garbage code that appears just fine until you look at the output. I’m thinking financial reports and the like. Same problem new tool. You have to be smarter than the tools you use.
We are barely in the version 1.5 of LLMs that are coding. So what if the next Gen LLMs learn to code that bit that they are failing today as well.
We always made a machine do things the way we wanted and here comes the machines that can do the same with our intentions. Pretty cool evolution worth for 21st century indeed.
Now it’s time to move on to solving real problems.
Exactly. Ten years from now, the capability of these AI generated programs will be much better than they are now. Right now, AI will make up things (or pick a bet guess) that may or may not be true (or work, in the case of code) .. rather than return nothing. That will not always be the case.
You sound very very confident…
A floating ‘90% done’ status on a project is not a good thing.
(LLM ‘AI’/Full Autodrive/Autocoder) has been hanging at a claimed 90% for a solid decade now.
Which means its at a local maximum…
No, it hasn’t. What an absurd statement to make, as though you have no knowledge at all of AI development, yet are so confidently incorrect. You throw out BS like the best LLM.
Invest all your money in AI stocks Frink.
All of it.
“Much of this is also reflected in the plummet in usage of community forums like Stack Overflow.”
Hmmm…do I want to post a question to stack overflow and be publicly ridiculed or critiqued? Or do I want to ask an LLM instead? Stack Overflow did it to itself.
I agree. Stack Overflow is troll city for geeks. The AIs I ask for tech help tend to be the opposite — a little sycophantic — but I prefer that to being snarled at.
Those aren’t the options.
You can search stack overflow for the question you are asking and read the answer already there or you can ask the ‘AI’ and it will tell you muddled up versions of the answers on stack overflow and other sources.
The fact you skipped searching for the question before posting is why you deserved the abuse.
The fact the you are lying a apparent toxicity as a ‘pointing out skipping search’ is why you deserve the blame.
You’re what’s wrong with people, and “winners” like you are who ruined the Internet. Current LLMs are better humans than you and that’s saying a lot
No signal, only noise from Frink.
And he thinks that makes him a good person.
There is the usual mix of people on SO, I don’t have an account as I don’t provide consulting services for FREE.
I use SO as a backup quick ref for unfamiliar libraries.
If the official docs suck, sometimes SO has the information.
If an unskilled coder gets flamed there, it’s for one reason, they think the site is there to spoon feed them their homework and are too stupid to find the available solution.
Respond to a link to available answer w complaints that show they don’t really understand their own question.
You can’t fix stupid, SO will do what it takes to make it go away.
Replying because of how much I related to what you wrote. It describes my programming depression from last months x)I keep trying to implement at least some. Things by myself for fun, to make sure I don’t lose he skill, to feed my ego (?), but my brain just can’t handle it because another thread is thinking about how useless I’m using my time. On the other hand, I’m now able to put all the ideas I had throughout the years that I didn’t because I lacked motivation. Specially in learning programming it self. Even though I idealize liking programming. I’m not sure if I like it or not honestly. But I definitely enjoy the results and the theory behind programming. The thing is there are always so much ways to design the architecture at every level that it overwhelms me and I don’t try. I guess I lack programming theory.
It’s the old programming addage. You scope the whole problem to solve then spend time breaking it down into solvable parts. The problem with current AI is the scope document does not give enough details for the solution. It defines the problem and the end goal; not the methods to solve that goal. There are good methods well thought out and then there are the ones AI derived.
It’s up to you if want the AI to give you enough details…..you just need to work more on your prompt.
Well, presently the context scope is too small for a complete software project. After the hundredth prompt, the AI no longer remembers the first one. Howerver, als for that, Moore’s law will apply.
Tools like Google Antigravity address that. It will provide an implementation plan you can annotate which is sufficient for most changes. Like any software project, the more time you spend upfront planning the faster the code goes together. There is another Google project I haven’t used ( cursor?) which creates markdown files with, I believe, descriptions of the overall architecture to help the AI navigate the project. Right now you should use one AI to create the plan and a second to implement it, but tooling is getting better and better at it.
It’s not like you just ask the AI for the program, it spits it out and you go off and use it.
I’m finding that for the simple, mundane, repetitive stuff.. “ex, go through all these many options in a switch statement and do something following the same pattern for each..” it takes away a lot of the stuff that really puts me to sleep.
I have recently started using AI for more complex tasks where I would have to do significant research. Maybe it’s just the way I phrase my questions but for that sort of thing I find the result is usually more instructive, teaching me what I needed to know than it is a black box that I would use without understanding. Also… it usually takes significant troubleshooting, several tries to get things working and I am going through the troubleshooting with it, interjecting my own thoughts and knowledge.
Library bugs certainly do still crop up during that process and I can still submit a bug report.
I do see where AI could result in one being steered towards libraries that are more prominent in the AI’s training data. But isn’t it just skimming that data off the internet anyway? Doing it myself I would end up favoring whatever libraries show up most prominent in Google. I’m guessing the training data is probably built the same way.
I find that it’s the simple repetitive stuff that the AI cannot really be trusted for, because it tends to slip in random variations. The more you ask of it, the more likely it will introduce an error that requires you to go through the whole thing, line by line, to make sure that it does what you asked for.
The very worst thing you can do with an LLM is to say “Take this code and clean it up, but don’t change any functionality or logic.”; it will absolutely do the opposite.
In my experience, if I tell the LLM not to make any changes besides X, it will follow my instructions perfectly. This is sometimes dependent on the length of the chat and the context window, and when it last saw the iteration of the code I want modified. Anytime you want something very specific done to some code, you should provide a fresh reference by pasting the code. This way it stays in the context window and doesn’t get summarized or hand-waved away. Gemini under some situations is supposed to have a 1 million token context window. I haven’t tried it yet, but if it works as advertised, that would do away with all the copying and pasting of the same code over and over.
Oh yah. I could never just let it generate pages of code and then trust that to just work. Sadly, we are a MickySoft shop here, coding in Visual Studio. No, not a MickySoft fan but I am warming up to Copilot. Mine is currently set to use GPT-5. Anyway, I’ll start something which is going to be a long monotonous pattern and it suggests the completion of the pattern. Often it gets it right. Sometimes it doesn’t but is close enough that it is less annoying of a task to fix the errors than to type it out manually. I still do have to read it to be sure.
I’ve wanted to write a puzzle solving program for several decades now. (E.g. fitting tetris shapes into a specific shape). Recently i managed to finally get it working. I wrote the move piece left and up routines and then ai did the boring typing of move right and down. It now solves one specific puzzle, but i’ll generalize it when i get around to it again…(in a decade or so by the looks of it.)
It is also good for promoting you to fill in the blanks in your design. Then both you and the agent knows what is going to be built.
Those are already a solved problem.
C++ templates!
Great feature or Greatest feature?
100% agree. It’s just like AI code assist is the next level to macros and code completion which were the next level to syntax highlighting, which was the next level to text editors… all the way down to punch cards
Having said that, it is getting more and more capable. But I like that. But I will review everything it does!
I don’t know… AI helped me make my FIRST open source project. I know several current and forgotten languages (been a programmer for over 30 years, that’s my career), but the depth required to do the full-blown app have never been worth it to me, and what I specialize in would not serve the purpose. Now, I was able to make a soup-to-nuts app, with testing, etc. I know what an app should be like, I know how it should work, I know how to design. Now I’m the boss, the client…. the AI does my bidding.
And honestly, it helps me solve bug reports in my “real job” programming WAY faster than I can. I give it a hint like “might be in this handler or this js file, here’s a screen shot, you can login with Chrome MCP and see for yourself, just do a, b and c”. I’ve solved about 30 bugs this way so far that have gotten reported to me.
I think the data is flawed. I use AI while coding to filter through the information available and cut out reading dozens and dozens of requests on Stack Overflow and other sites for appropriate resolutions. So the usage might be down, but how much of that is using AI chatbots to screen through the throngs of data to get you a useful answer.
I know it helps me with that kind of thing, but if I have it write any code for me it’s code that I adapt after the fact and I do not allow it to use just anything.
We are the users, we are responsible for the products we deploy. If developers start using AI exclusively we run the risk of systems that fail and a populace that only knows how to ask the funny little white box in the corner why it happened, instead of using the art of debugging.
Tread carefully, lest we lose basic knowledge that got us here in the first place.
I’ve been assuming that vibe coding is just one more abstraction layer. And abstraction layers have been upsetting me since they neutered the machine language skills that I worked so hard to learn. And assembly language, and, and, and. I’ve stopped fighting it, I’m not proud of that, but I think it would be easier to fight the government than to fight an abstraction layer. And given the rate of change, vibe coding may be abstracted away any minute now. Open Source is dead, long live Open Source!
I believe that we shouldn’t talk only about vibe coding; we need a smart coding approach. I wrote more about this in the article.
https://dev.to/kolkov/smart-coding-vs-vibe-coding-engineering-discipline-in-the-age-of-ai-5b20
My CoDe WaS hArD tO wRiTe It ShOulD bE hArD tO rEaD
I flunked out of coding from data structures twice and did other things in life. LLM’s have been great for me doing hobby server stuffs.
We need to learn how to efficiently and sustainable use these powerful wonderful tools. So, now I’m going to ask my cloudy llama/grok/geppetto “How to efficiently and sustainable use yor possibilities?”
I don’t think the question is whether or not llms are useful or can help people. It’s about does it endanger oss and some people have gone further to share concerns about the internets utility more broadly.
I think it’s clear it endangers oss. It’s harder for adoption, a class of users are no longer finding bugs, the bugs being found are often complete noise, and an LLM might prefer to copy an oss project with slight modification rather then import it. I could go on, but basic second order thinking makes it clear that the signal to noise problem is now more of an issue than before.
feeling like a minority. i like programming. it’s fun to do something well. everything i write, my goal is to remove redundancy, remove bloat, remove extraneous dependencies, and to find a clean factoring that makes all problems simple. the last thing i want is a bigger or more capable black box.
i do sometimes want automated tools for mechanical tasks (provably correct transforms), and LLMs these days are heading in the opposite direction but i imagine they’ll come around. i play against a chess engine that, if i understand correctly, uses a neural network to prioritize a classical (provably correct) search. a lot of low-hanging fruit in that kind of system, i imagine.
To me vibe coding is instructing an LLM by a non-coder and let the LLM write the code. But I don’t see this endangering OSS at all. Existing projects have developers, and developers armed with an LLM are much more productive and write much better code than a non developer ever could squeeze out of an LLM.
I think this is going to be the end for commercial software sooner than OSS, OSS will grow much faster now than before and reach maturity and even surpassing commercial software at some point in functionality, stability etc. and don’t contain as much commercial slop and bloat. Sure, there’ll be more slop, but that’s a given when new technologies arise. Between the slop will always be some gems.
The unique problem for open source is the extent it makes development a democratic process.
There are clearly more idiots (w or wout LLMs) then competent programmers.
Even in the comments section of HackaDay!
If the idiots can all vote themselves commit privileges, the project is done.
I don’t think that’s a viable threat, for most sensibly arranged projects.
Idiots have already tried voting/harassing Linus out of the Kernel.
Apparently, he’s rude to them.
Nothing new.
It will put extra load on OSS project ‘gatekeepers’, but simply banning anybody incompetent enough to just submit LLM slop should do the trick.
One strike, out.
Perhaps a LLM to detect LLM slop and direct cut/paste from same places LLM didn’t actually learn anything.
Will need a human for ‘sanity check’.
It’s hard to say if it would actually help.
Or just huge generate noise that looks just enough like signal to really F things up.
On the gripping hand, there are a large # of code changes that are just API calls.
Those will invariably look a lot like available examples.
But you can’t just let that category in automatically.
It’s got to be the right API.
LLMs are particularly bad at not mixing a two APIs together in one result.
Exactly what you’d expect from a statistical word salad generator.
Last I saw was enums from API #1 being used in LLM slop for API #2.
Both APIs doing similar things.
I can’t disagree.
As in, I literally can’t. The moderators keep deleting my reply.
“Killing Open Source” is clearly hyperbole, but a reason I don’t often see articulated is that “Open Source” is actually the natural and normal way to code. I see a lot of my generation started with dialects of Basic, which many computer companies seemed glad to include for free, at a time when “using a computer” was synonymous with coding. To them it didn’t matter there were hundred of variations, users could put their cute little programs together and trade and perhaps even sell them, like trading cards. Perhaps it’s a coincidence Microsoft sold many of these Basics, but it’s in line with their overall “programmers over users”. But, of course, 8-bit computers really needed a faster language, and both amateurs and “shareware” programmers needed faster languages like C, and other languages that were more platform agnostic. But that meant a loss of control, from the manufacturers(who were also software providers), and why IBM bumbled on it’s own invention of the PC. The customers would keep making their own software, and selling it. Those dedicated to their “Free Software” found they needed to protect their work legally, to do what the big tech of the time thought they could control in a little walled garden with their own MS Basics. The very idea of BASIC was to provide an open programming environment for learning and sharing, and though it evolved into FOSS, it was always going to be a significant part of computing. So, maybe programming will devolve into sharing prompts rather than true programming languages as we know them now. But there will always be those that create and share their work, and tweak existing code to run faster and better. The genie is out of the bottle. This is just my reaction to the title. Whatever follows in the article may be fine, but it’s not about Open Source dying, by any means.
It mattered quite a lot, because the point was to capture users to their variant. The fragmentation was intentional, though ultimately counter-productive. The point of BASIC being a universal programming language for beginners was just a poorly held facade – each company wanted their users to use their version on their hardware, so they introduced subtle differences and incompatibilities that made direct porting of software between systems as difficult as they could get away with.
I researched ANSI BASIC recently. The committee was IIRC Kemeny and Kurtz (Dartmouth) and Texas Instruments. It deliberated from 1978-1983 releasing two versions. Little did I know that my first dialect was ANSI TI BASIC on the TI-99/4A. Except for the committee members, almost nobody produced an ANSI BASIC.
It’s interesting to me that TI stuck to ANSI syntax in a myriad of business products , including calculators. There was an internal document with coherent subsets to apply in each context.
Let’s also not just act like every single new coder is going to be vibe coding and never even once be curious about how it all works themselves. I learned TI-BASIC and immediately jumped into z80 asm because I wanted to know how the calculator worked underneath. Now I know asm flavors, BASIC flavors, C flavors, etc.
It’s lowering the bar to entry, and to those that let it, that’s as far as they’ll go. How is that different from the dev copy-pasting from Google? That certainly didn’t ruin coding or OSS.
Real coders exist, and always will.
Copy paste from Google?
Luxury.
When I was a kid, we typed programs (games mostly) from paper magazines and we liked it!
And we didn’t understand any of it, because the magazine was in a foreign language. Once, a boy figured out that it was actually in English and found a dictionary, well, the child protective services had to be called…
You had magazines? Wow. I had to type programs from mimeographed newsletters where sometimes the purple ink was weak. Worse if two pages stuck together!
Just kidding, I had magazines and David H Ahl’s MORE BASIC COMPUTER GAMES.
GD it guys, you each tell more outrageous lies, then the last guy says:
‘You tell that to youth today and they won’t believe you!’
Just to close the circle: over at AtariAge some folks have experimented with getting AI to write TI BASIC. There’s just enough in the training data but it’s frequently mixed with other dialects.
I posed a programming challenge in TI Forth. An unhappy result was: someone used AI to get a Visual Basic solution then told AI to translate to Forth. I cried. Technically correct (one bug) ANS Forth, but top level was a mess of nested loops and conditions, which is an anti-pattern, especially in Forth. Nested loops should be factored out! Routines (“words”) should express one operation in 1-5 lines (extra whitespace ok.)
My solution for those conditions and feels like poetry to me.
AI is killing everything, including the planet.
Don’t worry, the planet will return the favor.
You’re killing me! 🤣🤣🤣
AIiiiiiiii!
In about 200 years. And not the planet, because it is just rocks. But the annoying humans.
On the topic of Stackoverflow as a symptom of LLM use: I got a lot out of SO, while simultaneously irked by 1) the tendency to not answer the question asked, and 2) getting the impression that it was turning into off-shoring s/w engineering support.
Unless Tata, Wipro and the like are diving head first into vibe coding their clients’ projects, it appears I was wrong about #2.
For Tata?
If they started using complete idiots just vibe coding you’d immediately know.
Their results would improve drastically.
And be delivered on time. And they might even work!
Let’s keep our expectations realistic…
They might compile, still won’t link.
Like I say, ‘improve drastically’.
If the LLMs are using open source code for training and people stop producing new os code… How will novel stuff happen? It feels like there’s an issue here around LLMs learning from themselves?
Also I’ve not looked into licensing: I’ve recently had my first use of an llm (Gemini) doing something useful: I wanted a plugin for kicad that did rectangular shaped spiral traces and within a minute it had made me the plugin, with the right options in the plugin’s menu and instructions on how to install it. Should/can I upload to GitHub? Is there any point? The next person who needs this facility can just ask Gemini. But … This only was possible because of the hundreds of plugins already on GitHub that it learnt from…. How will it learn to do plugins for new libraries and software??
If you format it according to all open source standards and support it, then why not… That’s what I did. I had a lot of shared code in my private projects, so I extracted it, formatted it, and it became a great ecosystem of fairly professional projects that I use for my private projects, but others can now use them too. And yes, I do track issues; that turned out to be the hardest part—keeping everything perfect. But smart coding made it possible. I wouldn’t have had time to do it all by hand, separate it into separate libraries, format it according to all the standards, write documentation, and track all the changes. But I manage the agents, not them manage me.
https://dev.to/kolkov/smart-coding-vs-vibe-coding-engineering-discipline-in-the-age-of-ai-5b20
https://github.com/kolkov
That. I’ve been a top 1% SO for quite a few years. Then LLM’s started to use it for training / as an income model, students for homework and lazy people as a Google surrogate. Its only voluntary, so I just stopped. In general I would argue this is a great way to kill a community.
There’s a concept: Dead Internet Theory, in which new OSS frameworks “do not exist unless they are in the training data.” In one case, React dominates all other frameworks, but it takes 18 months for LLM to “learn” the latest version! So LLM continues to spew workarounds, to use deprecated features, and to omit better ways to get the same result.
Apart from nothing new getting discovered, it puts the burden on code reviewers to “update” the generated output.
Which raises the question whether the present situation is any worse. Previously, you might have found one helpful soul out of ten or twenty trying to second guess your intent or otherwise criticize your question, or just spouting nonsense as they didn’t know the answer any better than you.
With the LLM you have a 90% chance of getting the right answer, or at least a 90% right answer which is better than amateur guesswork. If the complaint is that the AI will simply recycle the most elementary and trivial solutions, well, so do the people. Most of the people you get are perfectly mediocre and couldn’t point at anything clever – because they’ve learned all their tricks on the same forum.
The real question is, does OSS die because AI breaks the “process”, or was there never really any process as imagined to begin with. Was it just the blind guiding the blind for the most part?
It should read “fixing open source projects in seconds flat” because that is what I use AI “vibe coding” for lol . I am on my 18th app probably that is a big hitter in the electronics game, but has had the same awful interface, necessity for web to remember commands/flags for that particular environment, or require 4 other python/rust/burgercode single function scripts to run along with their required sdks, apis and other bs. AI can easily fix most of these gripes in about 20 seconds and hand me a way more functional piece of software. I wish I could go back but it is just so much faster and easier than like others have said to pour hours into figuring out the correct flag to use with this particular distro blah blah I am getting angry just thinking about the abuse myself and others put themselves thru to see a random display show a hello world. AI as a hardware bench buddy is just awesome. Imagine having a non-gatekeeping, fragile ego graybeard on the bench beside you with every pinout known on every chip on the board and the protocols to trigger them if necessary. That is just awesome and incredibly helpful imho. Open source takes 20 people that forks into 6 projects and then everyone makes up and comes back for a final push on a project 8 years later and then promptly fizzle out with not even a toe over the finish line leaving things to sit until some other group comes along and does the same thing lol. I am pretty over it at this point.
I agree this impedance mismatch, where it used to be harder to write a fix than review it, and now it’s harder to review than to write, presents a lot of challenges for OSS. For instance I started using crush (https://github.com/charmbracelet/crush) a few weeks ago, and it’s awesome. I’ve also been extending it like crazy. But ultimately the only way to keep my contributions “available” while also using them myself was to implement a plugin system, caddy-style. This way the core team can see if I get any traction, if my code sucks, etc. but I don’t have to wait around for them.
More and stricter quality gates will definitely help ofc, and I don’t have a problem having giving an LLM “hey, check out this PR and tell me if it’s good or not”. IDK if you could fully solve the problem, but at least reduce it a bit.
Careful with “is it good?” After Claude did a tolerable job of diagramming (documenting) my framework, I asked it to compare and contrast it to competing OSS frameworks (in the sane area.)
Aspirational LLM bias gave me a list of “Enterprise Grade” advantages of my code, some of which didn’t exist…
haha no doubt. I’m thinking consensus building between different prompts could get pretty close though. Even if they individually have maybe a 70% chance of being right, 10 of them should get a lot closer to 99% no?
I don’t gt the stack overflow reference, making me doubt the research. The fact that stack overflow is becoming irrelevant is obvious (and scary, if not for forums like that, how can we get actual new knowledge into llms …).
Anyway, for users stack overflow is stupid. Many post that are not just quite what they need, asking something takes forever in some cases (and in son cases literally forever). Chatbots are there at your win and do not tire.
So chatbots are like companions and google at the same time. If a search engine where as good as llms, we would have seen the sane decline. So obvious IMO.
Tl;Dr if I can ask an llm, why would I care to ask so?
I’m not a coder, I’m a mechanic. I like to build things, and not having a route to code production log-jams my creativity. Vibe-coding for my projects this last year has put the other half of many projects within reach and allowed me to dump cortical content. Is it perfect? Not at all, but the LLM can code, which I can’t, and I can think technically and do human things, which the LLM can’t. Claude Opus 4.5 has changed my life. Gemini 3 Pro, too, though it can’t really work that well with 1000 plus lines. You’re all coders and I’m sorry you’re put out, but I’m empowered (relative to my patience and tenacity), and I don’t really want to give it back.
It’s important to understand that without programming and engineering knowledge, an agent or LLM can lead you into the depths of programming. Yes, the code might build and compile, and sometimes even work, but it can’t be used in production; it’s fraught with…
“It’s important to understand that without programming and engineering knowledge, an agent or LLM can lead you into the depths of programming.” That’s good to know but it’s not clear what it means.
What you are not clear is where your knowledge is not entered into yet.
Probably because the community on StackOverflow is filled with serial redditors who are more interested in karma than answering questions. Constant belittling. Constant snark. Chatbots don’t do that. And they will get you the answer quicker.
Karma was the death knell of stack overflow.
It’s stupid that you can’t answer your own questions anymore. I used to have an issue, search a bit, and post a question. But I don’t just wait until an answer arrives from upon high – I keep working the problem. If I find a solution, I can’t post an answer to my own question because that’s karma farming. I don’t even know what karma is good for. Except embedding images in your posts? Or something like that?
They banned me. Me, with 40 years UNIX experience, and a brain the size of a planet…..
I was recently handed a project based on Zephyr OS. This project was coded by humans. If I didn’t have an LLM to help me wade through the mountain of garbage I’m dealing with, I would still be sitting here trying to figure out which of the many configuration files I need to look at to figure out why the serial monitor refuses to work. Instead, I get a coding partner who, while flawed like any other coder, understands Zephyr FAR better than I do or did. This partner knows which file contains which part of the settings. API changes make things more difficult, but they always have. At least I have working serial output now.
Consider FreeCAD. If you want to find information on FreeCAD, most of the results of a web search are going to be for some older version that no longer applies to what you want to do. You might glean a couple of tricks from the noise, but the problem is not that FreeCAD was updated, it’s that the web search engines don’t do a good job of pointing you to the right content based on your search.
The situation is basically the same with programming. I want information on some version of Zephyr, but the search results I find are all across the spectrum of all the various releases. With an LLM I can get some bad results at times, but I get those bad results and can fix them in less time than it would take me to even understand what I’m trying to do.
I’m a self taught programmer, and I’m most proficient in C and Python, but I’m not as good as most people attempting the same types of things I dabble in. That’s fine. I also do PCBs, schematics, CAD work, foreign languages, raise a kid, etc. I don’t have time to become the programmer that my projects require. I do have the time to work with an LLM and build something that works well enough to call it a success. I love open source. I report bugs. I don’t usually report solutions to those bugs. This is all unlikely to change unless LLMs can produce code that is acceptable for open source submissions.
On the Stack Overflow side of things, I’m not upset at all that people are not visiting that horrible site. Do they sometimes have answers to my questions? Yes, but there is no way I’d ever ask another question on there. No one deserves to be belittled, insulted, or treated like a leper because they have a question. Who do they think have questions? Seasoned veterans? Of course not! People who are learning! Yet they claim it’s not a site for learning. The main problem with SO beside all the jerks is their goal is impossible to accomplish without learners providing the questions that they flippantly ignore and insult. No more Stack Overflow? No problem!
I managed not to state my opinion about Zephyr so far. Well, I dislike Zephyr more than I dislike Stack Overflow. I would never use it in a personal project, nor would I begin a professional project that uses it. Abstraction is a distraction from the hardware. I don’t want to troubleshoot the framework. I want to troubleshoot my code and hardware. Want to experience something so poorly organized that your head explodes? Try Zephyr. /project/application/build/application/zephyr <– that’s where you find your flashable binaries… unless you use MCUboot, then half of it is ALSO in /project/application/build/mcuboot/zephyr. Make sure you flash them to the correct locations! You also need to modify the board.dts, Kconfig, app.overlay, cmakelist.txt, prj.conf, oh, and I forgot.. then you have to program the actual source! Good luck doing anything with that API. It’s a beast! I would not know half of this without the help of an LLM, and I’m only scratching the surface.
My last point: people who don’t like LLMs are mostly just the people who feel threatened by them. Are LLMs perfect? Of course not. They’re modeled after humans.
PPL just don’t understand LLM AI, its trained from Facebook/twitter/reddit posts, 90% of which is moronic bile; Sure its also trained on ‘code’, so it can parrot code on demand, but its not real code, its parrot-code;
The only ppl impressed by LLM AI coding are ppl who don’t know crap about code; I have been doing “AI” since 1980’s professionally, I follow it all along, I was doing LLM when it first came out, not even 10 years ago it could do arithmetic, it still can’t; It just predicts the next token, and to a fool it looks like genius; To the CEO’s and World-GOV its a means to get all the world on the same page, and make everybody into an idiot, where idiots are easy to control; For programming it means that all non-gov programming is verboten, as the “AI” will just say “Sorry Dave, I can’t do that”
Forgive me if I take your opinion with a grain of salt. I just asked Gemini and ChatGPT what’s 2+2? They both answered 4. Ok.. let’s assume that question is too linguistically connected and it’s peppered all over the web. Everyone knows 2+2 is 4, no arithmetic needed, right? So I asked 150×3. They both answered 450. When do they stop being able to do arithmetic? Gonna need some bonafides or you’re just another nobody who makes wild claims of authority without evidence while posting from anonymous accounts.
Just google it…
ChatGPT failed to calculate 241-(-241)+1.
It answered 484.
Curious – what was your prompt? I typed “what is 241-(-241)+1 into duck-duck-go, got 483. I also asked the Glean AI our IT chose, it said 483, and also showed it work, 241 – (-241) + 1 = 241 + 241 + 1 = 482 + 1 = 483. Both which match Win 11 Calc
Whether it can do math depends on if the parser throws the question into a separate math solver. It’s not necessarily the language model that gives the answer.
Amateur FreeCAD tech writers didn’t version stamp the old docs and tutorials.
But at this point, it’s water under the bridge.
New docs are version stamped, so situation workable w good search strings.
If you got ripped on SO, it’s because your question was already ‘asked and answered’ many many times.
Search first, beginner questions are ‘done’, search again w different keywords.
Expect answers based on principle, not ‘cut and paste’ ready code.
Insisting on cut and paste ready code will get you flamed, but then you deserved it.
Nobody is going to spoon feed you information while stroking your ego.
AI is good at that, too bad the information quality sucks.
I have to agree with the general idea alot of other commenters are making here. AI is great for removing the mumdane. Its great forngetting the idea out. Especially for small scale projects. You also really need to know how to code to know what to ask for.
I would also say a lot of the problems listed are brought on by themselves. There is a reason there are a million memes about every answer on Stack Overflow being “use the search” or “You are doing it 100% wrong (assessed without full context)” or simply “closed, duplicate.” There is also a reason people avoid manuals, because, especiallynfor open source things, then documentation is incredibly crypric and written by someone who has no concept of writing to an audience that isn’t already intimately familiar with the product on a developer level. That or the software only has one install option using some obscure flash in the pan set up that requires 10 other things be installed that may or may not work.
You have to know the answer to your question to know its lying to you, they call it ‘hallucination’, I call it bull-shitting; All to often when I call out the AI, it argues with me, when I provide proof it apologizes, then when I restart the session, its the same bullshit all over again, as the AI has no memory;
I have been doing LLM AI since 2012, I have tons of HW, and huge machines where I can do my own algo’s, so I don’t have to be dependent on the metered LLM-AI; But still its crap, many of the experts admit so, that LLM-AI is not the path to AGI; LLM-AI is like the 1M monkeys on typewriters who write the bible or Shakespeare, some are impressed, but to math ppl its the probable outcome, or AI slop-art, the same monkeys can throw feces on the wall, and AI Ceo’s can pick out the most beautiful and say ‘see what our AI monkeys can do, beautiful art’, what they don’t tell you is that its one in a million;
I spent most of my life in systems coding, doing low level ASM, knowing the HW very well, there is no way in hell that any LLM-AI could write such code; Only trivial problems found in CS-101 textbooks can be generated by our ‘monkeys on a chip’
I’m the great-great-grandpappy of AI. I’ve been coding LLM AI since 1842. I have all of the computers in the world and they’re big. Very big. The biggest some say. Everyone is very impressed by my computers. I don’t have any monkeys or typewriters. You’ve got me beat there. But I’m going to catch up to you. I’ve already asked Melania to buy 2 million typewriters and all of the monkeys in Africa, Asia, AND South America. I’m going to have the best monkeys the world has ever seen. Then we’ll see who has the most beautiful art. And code. don’t forget the code. The big beautiful code.
Somebody here said it best “Stack Overflow, is where MENSA Redditors find home”, most of the ‘mind control’ we live in is because of google’, I ask a question about SW or HW and I’m only given a reddit or stack-overlow link, … so that’s where I land, now of course now I get the AI bile, which most of the time is just bullshit; Now of course the Google return is who pays the most for ads, and words generate revenue, and what you see in results has NOTHING to do with your question; But yes reddit&stack-over, seem to have had this cozy relationship with Google search; Not to be outdone by the morons on SO or Rediot, when OPEN-AI ‘aligned’ their LLM-AI they paid 10k African ppl in Kenya $2/day, to make the AI “Politically Correct”, by incorporating “Reddit Think” into the AI; Now recall that Reddit is product of US-NAVY-INTEL, like 4chan, its no accident that “WOKE” is a weapon, to de-fang and make morons of young;
What people don’t realize is that we’ve all been using AI for decades to answer out questions, it just didn’t write English or Python yet: PageRank and the many algorithms that have come since indexed the Internet and found relevant articles according to your search prompt. Stack overflow and Reddit boomed to prominence for a time because they fit what the search engine was looking for. The joke was that being a good programmer really meant being able to use Google and copy from StackOverflow. It became a feedback loop, benefitting these sites, for better or worse, because of their SEO. The Javascript ecosystem has always been a popularity contest, with popular and long-supported libraries being preferred, because you know it will be easier to find answers for.
People used to hate high(er) level compilers since the beginning of it.
And LLMs are just a new layer of compiler, that fails like each compiler failed in the past, and will mature into a greater tool day by day.
Is better to get used to it than try to fight it.
Interesting thought, and I mostly agree with it.
“Mostly agree” because AI is a tool like any other, albeit darn advanced and darn flexible (in its own ways), but any tool is only as good as its user/master.
Meaning, if the user is dumb, the tool will cancel the advantages of having one in the first place. Dumb users usually hope the tool will work it out instead of them mastering the craft, and in some/limited number of occasions it will, but statistically speaking those probably wouldn’t make a lasting difference.
Compilers do what you tell them to do, the LLM when I ask it to code a problem, it will argue with me, it will lie, it will feed me bullshit; If you all want to call LLM a new abstraction on the software dev process fine, but I think it’s what’s it is, LLM is trained from lowest common denom Facebook/twitter/reddit bile; 50 years ago I used to do ASM, and I wrote compilers for years the entire C++ dev era, nobody tolerated morons or bullshit, now if you decide to use LLM for SW dev, its you the programmer who must tolerate your moron idiot AI helper, then you can train it, and as soon as you unplug, or restart, its back to tabla-rasa; Cybernetics (AI) has been sold and busted every 20 years since 1950’s, its 99% bullshit;
OSS programmers love to reinvent the wheel. Now they have a shiny new tool to make that easy.
I don’t entirely agree with the authors; it’s a question of their approach to programming. Vibe coding isn’t the only possible way to work with agents; there’s also Smart coding. I even wrote an article specifically outlining the differences. As for open source, there could be many more good libraries. For example, Go has developed its own professional graphics ecosystem, something no one wanted to write for 16+ years.
https://dev.to/kolkov/smart-coding-vs-vibe-coding-engineering-discipline-in-the-age-of-ai-5b20
https://dev.to/kolkov/go-126-meets-2026-with-a-professional-graphics-ecosystem-9g8
https://github.com/kolkov
AI saves me a lot of time compared to parsing StackOverflow for an answer that is almost right, that is anyway copy and pasted into my own own code.
The problem I see that will come up in a not soo distant future, is that answers to new problems won’t be available on StackOverflow because of people not asking the questions, and fewer users will be there to answer to them, which means that in turn the AI will also not have the answers.
I believe that OSS will only increase due to the fact that more people will be creating tools, and having not used hundreds of hours to write it, they will be keener to share it.
I completely agree. There’s a risk that there will be fewer answers online. But there could be more good code. The key is to use agents correctly, rather than relying on vibe coding—that is, not trusting the agent entirely, but rather guiding it along the desired path.
For example, agents were a lifesaver for me when my vision deteriorated after COVID-19. Now, fine print is flaking for me, and it’s become difficult to work with code if there’s a lot of it and I have to write and correct it myself, but I can check the finished code.
https://dev.to/kolkov/smart-coding-vs-vibe-coding-engineering-discipline-in-the-age-of-ai-5b20
I will always respect and remember what StackOverflow was and how it helped countless devs, including myself. Unfortunately, this article is all fear mongering. StackOverflow sold their data to be used as AI training material, essentially signing their own death certificate. Consulting firms are also taking a huge hit because they relied on StackOverflow for their teams of junior devs to write boilerplate code while charging $200/hr. These are the roars of aging tigers. They aren’t offering solutions. They aren’t calling for a vetting process or protocol. They are making a bold claim and cherry picking studies with legacy codebase that fit their narrative. 15 years ago when I got into programming the old guard would say “you guys today don’t even need to build anything anymore, just use a CDN or pull from a repo”. Nothing has changed. These are the death throes of aging tigers. Don’t be scared, the roars are loud but if you listen closely you’ll hear what they’re actually saying… Remember me…
I’d agree with these findings actually because we are using many fewer open source components in Flexiva (a new code base) than Apex (an older code base). We replaced many of the older components with home-grown vibe-coded ones which do only what we require, plus our trained AI generates its own API specifications which suits the way we work.
I think the exact opposite is/will be true. Updating and creating Open Source code will be easier and easier. If I was a for profit software company I would be worried.
I am about to release around 9 open source projects i would never have finished, released or even started if it werent for opus. Including groundwork projects others can build upon.
From my lazy ass perspective, AI boosts productivity like nothing before. I started so many little personal projects in the same scheme of Great Idea -> POC -> [boring implementation details] -> Something useful. Like personal cataloging projects, home server admin automation scripts, computer quality of life things. The projects have been gathering dust because of the [boring implementation details]. Now AI helps me handle that boring part. It unblocks me. And I learn a lot in the process — it’s like having a superpatient co-worker sitting next to you whom you’re not embarrassed to ask the silliest questions.
I think this article is overly pessimistic about FOSS effects from AI. For starters, AI didn’t kill Stack Overflow, surly intolerant “experts” did that by attacking posters for not “being technically apt enough”. AI has infinite patience for questions, stupid or not. I have been using Claude for 2 weeks now, and I put articles on my github repo about how to us Claude for development with it, and my experiences with it. Claude and I have written about 30,000 lines into the repo in that time, mostly projects on my wish list that I didn’t have time to do. I’m also using it to create better testing and help with other development projects. In short, for my FOSS project it has supercharged it. Why so down?
That’s the same style argument as saying printing presses killed books, code is code. Open source code is software whose source code is publicly available and licensed in a way that explicitly grants anyone the right to:
View the source code, use the source code, modify the source code, and or distribute the source code (original or modified); without requiring permission from the original author, as long as the terms of the license are followed. Out of those things, vibe coding produces material that fits directly under that definition. Aka, open source code lmfao
“experienced developers who gave them a whirl subsequently burning them to the ground in scathing reviews.”
Not here:
Took AI 10 minutes. Made two functional errors Dave caught which were then corrected by him telling the AI.
Let’s Create a Commodore C64 BASIC Interpreter in VSCode!
Dave’s Garage
1.1M subscribers
Dec 15, 2025
Dave uses OpenAI Codex to create a complete implementation of Microsoft’s CBM BASIC v2 for the Commodore 64.
https://www.youtube.com/watch?v=PyUuLYJLhUA
Dave’s CV:
Professional Career
Microsoft (1993–2003): Joined as an intern in the MS-DOS department in 1993 (initially under Ben Slivka), then hired full-time.
Worked on operating systems including MS-DOS, Windows 95, Windows NT, Windows XP, and up to Windows Server 2003.
Key contributions (as developer and development manager):
Created Windows Task Manager (originally developed at home and submitted internally; became a core feature in Windows NT 4.0 and later versions).
Ported Space Cadet Pinball (3D Pinball for Windows – Space Cadet) to Windows NT.
Developed Visual ZIP Folders (integrated ZIP support in Windows, part of Microsoft Plus! 98 and later).
Worked on Windows XP Product Activation (anti-piracy system; reportedly embedded references to Microsoft Bob as an Easter egg).
Contributed to other areas like OLE32, Windows Shell, Media Center, and more.
Left Microsoft in 2003 after about a decade.
Post-Microsoft:
Founded SoftwareOnline LLC, a software vendor/entrepreneurial venture.
Holds six patents in software engineering.
Retired after 45 years in the imbedded space. I’m using chatgpt to write an Colossal cave/Zork level adventure game framework in OO forth. everything is a container or a message. build/create does>, can/is bitmaps, trees, LL’s and timers. I’m using Scott Adams adventures as a simple test fixture. With a enough direction, you can get interesting code from it. I could have wrote it myself, but I wanted to see what it can do. Minimal success getting it to build a minimal, multitasking Atari 8 bit O/S.
Recently when I was migrating twiboot (an AVR I2C bootloader — which I’ve forked — my changes are in my Github), I thought I could save some time using ChatGPT to do the busy work. It kept insisting my problems were on the master side, and kept proposing changes to that. I wasted three days of it telling me I was almost there and that this fix would definitely work. Finally I had enough of that, implemented some good logging and rolled my sleeves up the way one did before LLMs and had it working in a couple hours. That told me all I need to know about LLMs and their coding prowess. LLMs are great for creating functions with a few inputs and very narrow specs, but once the code balloons into 500 lines or more, a human brain works much better.
This article is about vibe coding’s impact on open source and knowledge communities like StackExchange… basically, less activity and long term decline in both domains… which is an obvious and predictable result.
If you think about it, what “activity” is probably missing… it is the activity that AI can already replace. 80% of these forums are people asking questions that google (and now AI) can answer in 2.2 seconds… beginner questions that have already been answered. Thousands of open source projects exist for every one that has real potential or makes a significant contribution to the evolution of technology or the open source community.
What is the value in this “activity” that is not happening. What are the chances that real, valuable content has disappeared? Experts working in their field are always going to have questions that other experts can/need to help with.
So the red herring here is that “valuable” irreplaceable activity is going to be lost, and I see no evidence of that here; this article is rage bait. The only actual potential issue I see in the observed decline in activity is how are you going to train the next generation of experts… when AI eliminates the rungs at the bottom (short term) and middle (mid term)… or do we devolve into an “Idiocracy” (great movie though rather crude).
that “how are you going to train the next generation of humans” issue is very real and i suspect those of us who learned how to do anything at all before LLMs are going to become an increasingly scarce (and sought after) resource. the only remaining way to get a real education is to end up in prison
Experts are always valuable so I agree with you there.
We fretted about not enough tech people when the Internet disrupted everything, and everything kept going on; people learned new skills, businesses new ways to work. Then the next generation had no work ethic, no expertise, no attention span and wanted political ideas to be emboided by their work… and companies changed to meet their workforce where they were… Now we have remote work, deglobalization/geopolitical and AI and all sorts of other disruptions.
Things will always change and there will be winners and losers. Remaining beholden to better days before will probably result in one being left behind.
I’ve tried vibe coding and also just using copilot with claude 4.5 occasionally and i do have to say that you can also get the llm to explain a software system you are unfamiliar with.
But i’ve also had ai decide to ignore my clever optimizations usually after the token limit was reached and it “forgets” to put my instructions about this in it’s summary. Resulting in it sacrificing memory the platform does not have to make the typical implementation a bunch of times now.
So yeah you can make a simple app way easier now. But i don’t think human ingenuity is dead just yet.
Whether it turns out to be the next abstraction layer or the end of innovation seems murky to me. Right now though it would still have to be the human to decide to make a library/project available to others. That is still possible with ai. If all those new to making software vibe coders still have to learn that, it would at least explain it a bit added to that that the ai might have a not invented here syndrome in it’s learning bias perhaps, though I’ve not seen that happen yet.
Let’s not fight the new emperor and his clothes, but instead enjoy our hobby of creating well thought out code. Then in a few years (months?) time, you’ll be in high demand because other codebases will have deteriorated into garbage. And best of all, there won’t be any junior coders trained by your business to hand off to. How’s that for job security ?
Maybe focus a bit more on requirements analysis and architecture, but be sure to still understand the language.
Some problems are suited to once-off “seems to work” generated code, but surely not OS, banking applications and other stuff containing data that Enterprises need to explain to their auditors and shareholders…
Besides, both high- and low- quality code is still somebody’s responsibility regardless.
I like how the bot in the image is a sentinel from The Matrix, disguised as a cat.
Coding for 30+years and I love how AI helps me. It removes the mundane, in the way that syntax highlighting, automatic imports etc all have helped in the past.
I am still programming / writing code every day for my day job, and I estimate I now get 1-2 weeks of 2023 equivalent work done every single day. And its not lower quality, it just saves me the round trip time of figuring out what I did wrong.
People who are using AI and introducing bugs are using it incorrectly. That’s the danger – bad or careless programmers now have significantly more power,