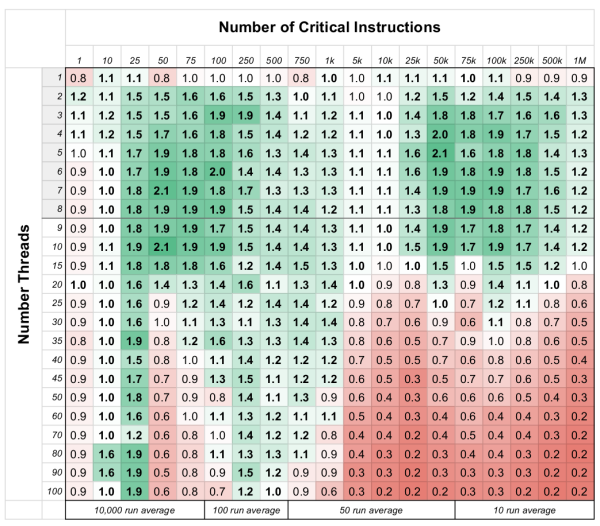
With the performance of modern CPU cores plateauing recently, the main performance gains are with multiple cores and multithreaded applications. Typically, a fast GPU is only so mind-bogglingly quick because thousands of cores operate in parallel on the same set of tasks. So, it would seem prudent for our applications to try to code in a multithreaded fashion to take advantage of this parallelism. Or so it would seem, but as [Marc Brooker] illustrates, it’s not as simple as one would assume, and it’s very easy to end up with far worse overall performance and no easy way to fix it.
[Marc] was rerunning an old experiment to calculate the expected number of birthdays in a shared group of people using brute force. The experiment was essentially a tight loop running a pseudorandom number generator, the standard libc rand() function. [Marc] profiled the code for single-thread and multithreaded versions and noted the runtime dramatically increased beyond two threads. Something fishy was going on. Running perf, [Marc] noted that there were significant L1 cache misses, but the real killer for performance was the increase in expensive context switches. Perf indicated that for four threads, the was an overhead of nearly 50% servicing spin locks. There were no locks in the code, so after more perf magic, the syscalls taking all the time were identified. Something in there was using a futex (or fast userspace mutex) a whole lot.
Continue reading “Make Your Code Slower With Multithreading”