Job hunting can certainly require a good amount of hoop-jumping in today’s age. Even if you’re lucky enough to have your application read by an actual human, there’s no guarantee the person on the other end has much of an understanding about your skill set. Oftentimes, the entire procedure is futile from the start, and as a recent graduate, [harshibar] is well aware of the soul-crushing experience investing a lot of time in it can be. Well, as the saying goes: if you can’t beat them, join them — and if you can’t join them, automate the hell out of the application process.
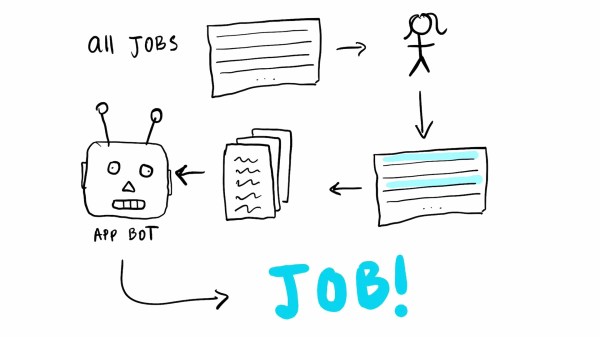
As the final piece of a “5 Python Projects in 5 Days” challenge [harshibar] set for herself — which also spawned a “Tinder for Netflix” for the web development section of it — she essentially created a web-scraper that gathers job openings for a specific search term, and automatically sends an application to each and every one of them. Using Beautiful Soup to parse the scraped pages of a certain job portal, Selenium’s browser automation functionality to fill out the online application forms, she can get all her information into the form saving countless hours in comparison to the manual alternative. The program even hits the apply button.
While the quantity-over-quality approach may not be for everyone, there’s of course room for more filtering and being more selective about the job openings beforehand, which [harshibar] also addresses in her video about the project (embedded below). And while this won’t fix the application process itself, we can definitely see the satisfaction a beating-them-at-their-own-game might provide — plus, it can’t have a worse miss rate than your typical LinkedIn “recruiter”. Still, if you’re looking for a more systematic approach, have a look at [Lewin Day]’s view on the subject, he even has advice job hunting is still further down the road for you.
Continue reading “Job Application Script Automates The Boring Stuff With Python”