There is a certain magic and uniqueness to hardware, particularly when it comes to audio. Tube amplifiers are well-known and well-loved by audio enthusiasts and musicians alike. However, that uniqueness also comes with the price of the fact that gear takes up space and cannot be configured outside the bounds of what it was designed to do. [keyth72] has decided to take it upon themselves to recreate the smooth sound of the Fenders Blues Jr. small tube guitar amp. But rather than using hardware or standard audio software, the magic of AI was thrown at it.
In some ways, recreating a transformation is exactly what AI is designed for. There’s a clear and recordable input with a similar output. In this case, [keyth72] recorded several guitar sessions with the guitar audio sent through the device they wanted to recreate. Using WaveNet, they created a model that applies the transform to input audio in real-time. The Gain and EQ knobs were handled outside the model itself to keep things simple. Instructions on how to train your own model are included on the GitHub page.
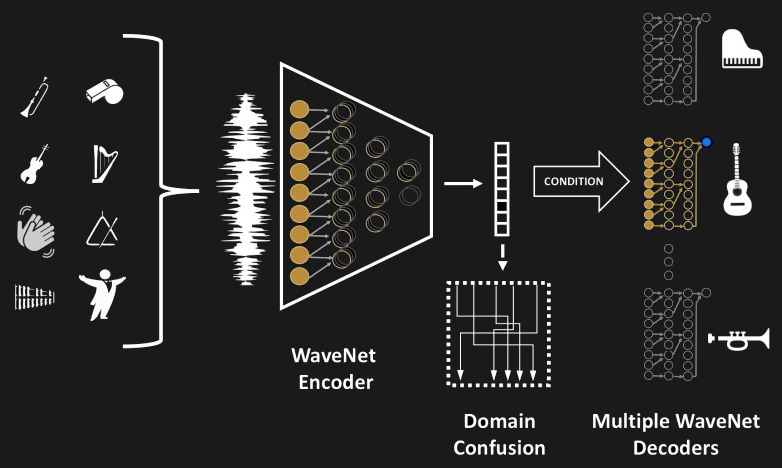
The inspiration for it came from the human ability to hear music played by any instrument and to then be able to whistle or hum it, thereby translating it from one instrument to another. This is something computers have had trouble doing well, until now. The researchers fed their translator a string quartet playing Haydn and had it translate the music to a chorus and orchestra singing and playing in the style of Bach. They’ve even fed it someone whistling the theme from Indiana Jones and had it translate the tune to a symphony in the style of Mozart.
Shown here is the architecture of their network. Note that all the different music is fed into the same encoder network but each instrument which that music can be translated into has its own decoder network. It was implemented in PyTorch and trained using eight Tesla V100 GPUs over a total of six days. Efforts were made during training to ensure that the encoder extracted high-level semantic features from the music fed into it rather than just memorizing the music. More details can be found in their paper.
So if you want to hear how an electric guitar played in the style of Metallica might have been translated to the piano by Beethoven then listen to the samples in the video below.
First Google gradually improved its WaveNet text-to-speech neural network to the point where it sounds almost perfectly human. Then they introduced Smart Reply which suggests possible replies to your emails. So it’s no surprise that they’ve announced an enhancement for Google Assistant called Duplex which can have phone conversations for you.
What is surprising is how well it works, as you can hear below. The first is Duplex calling to book an appointment at a hair salon, and the second is it making reservation’s with a restaurant.
Note that this reverses the roles when talking to a computer on the phone. The computer is the customer who calls the business, and the human is on the business side. The goal of the computer is to book a hair appointment or reserve a table at a restaurant. The computer has to know how to carry out a conversation with the human without the human knowing that they’re talking to a computer. It’s for communicating with all those businesses which don’t have online booking systems but instead use human operators on the phone.
Not knowing that they’re talking to a computer, the human will therefore speak as it would with another human, with all the pauses, “hmm”s and “ah”s, speed, leaving words out, and even changing the context in mid-sentence. There’s also the problem of multiple meanings for a phrase. The “four” in “Ok for four” can mean 4 pm or four people.
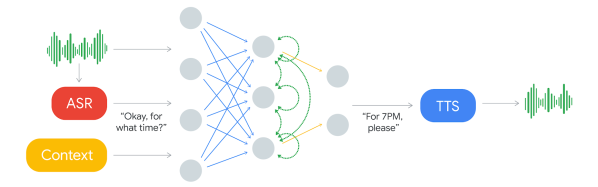
The component which decides what to say is a recurrent neural network (RNN) trained on many anonymized phone calls. The input is: the audio, the output from Google’s automatic speech recognition (ASR) software, and context such as the conversation’s history and the parameters of the conversation (e.g. book places at a restaurant, for how many, when), and more.
Producing the speech is done using Google’s text-to-speech technologies, Wavenet and Tacotron. “Hmm”s and “ah”s are inserted for a more natural sound. Timing is also taken into account. “Hello?” gets an immediate response. But they introduce latency when responding to more complex questions since replying too soon would sound unnatural.
There are limitations though. If it decides it can’t complete a task then it hands the conversation over to a human operator. Also, Duplex can’t handle a general conversation. Instead, multiple instances are trained on different domains. So this isn’t the singularity which we’ve talked about before. But if you’re tired of talking to computers at businesses, maybe this will provide a little payback by having the computer talk to the business instead.
On a more serious note, would you want to know if the person you were speaking to was in fact a computer? Perhaps Google should preface each conversation with “Hi! This is Google Assistant calling.” And even knowing that, would you want to have a human conversation with a computer, knowing that it’s “um”s were artificial? This may save time for the person whom the call is on behalf of, but the person being called may wish the computer would be a little more computer-like and speak more efficiently. Let us know your thoughts in the comments below. Or just check out the following Google I/O ’18 keynote presentation video where all this was announced.
Speech synthesis is nothing new, but it has gotten better lately. It is about to get even better thanks to DeepMind’s WaveNet project. The Alphabet (or is it Google?) project uses neural networks to analyze audio data and it learns to speak by example. Unlike other text-to-speech systems, WaveNet creates sound one sample at a time and affords surprisingly human-sounding results.
Before you rush to comment “Not a hack!” you should know we are seeing projects pop up on GitHub that use the technology. For example, there is a concrete implementation by [ibab]. [Tomlepaine] has an optimized version. In addition to learning English, they successfully trained it for Mandarin and even to generate music. If you don’t want to build a system out yourself, the original paper has audio files (about midway down) comparing traditional parametric and concatenative voices with the WaveNet voices.
Another interesting project is the reverse path — teaching WaveNet to convert speech to text. Before you get too excited, though, you might want to note this quote from the read me file:
“We’ve trained this model on a single Titan X GPU during 30 hours until 20 epochs and the model stopped at 13.4 ctc loss. If you don’t have a Titan X GPU, reduce batch_size in the train.py file from 16 to 4.”
Last time we checked, you could get a Titan X for a little less than $2,000.
There is a multi-part lecture series on reinforced learning (the foundation for DeepMind). If you wanted to tackle a project yourself, that might be a good starting point (the first part appears below).