[saurabhchalke] recently released whisper.unity, a Unity package that implements whisper locally on the Meta Quest 3 VR headset, bringing nearly real-time transcription of natural speech to the device in an easy-to-use way.
Whisper is a robust and free open source neural network capable of quickly recognizing and transcribing multilingual natural speech with nearly-human level accuracy, and this package implements it entirely on-device, meaning it runs locally and doesn’t interact with any remote service.

It used to be that voice input for projects was a tricky business with iffy results and a strong reliance on speaker training and wake-words, but that’s no longer the case. Reliable and nearly real-time speech recognition is something that’s easily within the average hacker’s reach nowadays.
We covered Whisper getting a plain C/C++ implementation which opened the door to running on a variety of platforms and devices. [Macoron] turned whisper.cpp into a Unity binding which served as inspiration for this project, in which [saurabhchalke] turned it into a Quest 3 package. So if you are doing any VR projects in Unity and want reliable speech input with a side order of easy translation, it’s never been simpler.



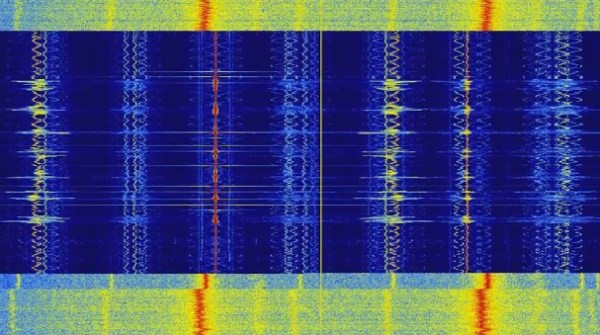
 His experiment was simple enough. He picked up a Baofeng handheld radio transceiver to transmit messages containing a call sign and some speech. He then used a 0.5 meter antenna to receive it and a little connecting hardware and a NooElec
His experiment was simple enough. He picked up a Baofeng handheld radio transceiver to transmit messages containing a call sign and some speech. He then used a 0.5 meter antenna to receive it and a little connecting hardware and a NooElec