[Rajesh] put web scraping to good use in order to gather the information important to him. He’s published two posts about it. One scrapes Amazon daily to see if the books he wants to read have reached a certain price threshold. The other scrapes Rotten Tomatoes in order to display the audience score next to the critics score for the top renting movies.
Web scraping uses scripts to gather information programmatically from HTML rather than using an API to access data. We recently featured a conceptual tutorial on the topic, and even came across a hack that scraped all of our own posts. [Rajesh’s] technique is pretty much the same.
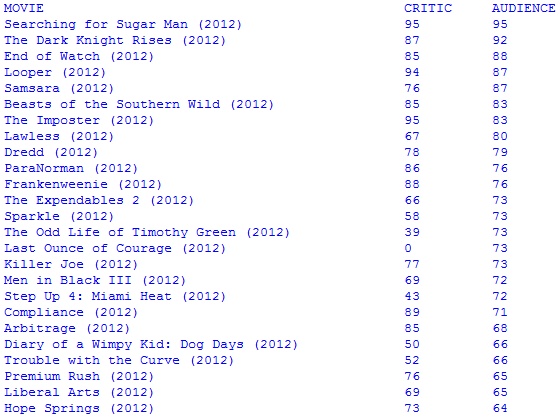
He’s using Python scripts with the Beautiful Soup module to parse the DOM tree for the information he’s after. In the case of the Amazon script he sets a target price for a specific book he’s after and will get an email automatically when it gets there. With Rotten Tomatoes he sometimes likes to see the audience score when considering a movie, but you can’t get it on the list at the website; you have to click through to each movie. His script keeps a database so that it doesn’t continually scrape the same information. The collected numbers are displayed alongside the critics scores as seen above.















I would do the same thing with NewEgg and HDD prices, so that I could easily sort by $/GB.
With Newegg, you don’t even need to scrape! There’s an unofficial API that the Newegg.com app uses to get product data that other people have discovered and documented. This page describes it well: http://www.bemasher.net/archives/1002
http://camelcamelcamel.com does this for free
much nicer user interface too
This is the post I was going to make. While I appreciate the hackery involved with web scraping, it’s always best to let someone else do it if you can ;-)
http://scrapy.org/
Web scraping can be used for an endless number of possibilities. I personally code in PHP and use SIMPLE HTML DOM
I’m wondering how they come up with those silly names.
Using a whole framework for scraping…
tsk… Real Gurls use plain Rexx and do all the scraping with just ONE gigantic PARSE VAR statement :-P
Considering Amazon has known to drop or inflate price based on browser and location, he should modify his script to pass various agent strings and also check the same through a few proxies. You never know what deals could be had.
Do you have any reference or this is a personal experience?
They adjust book prices on this guy pretty much after he’s bought the book.
http://www.tbray.org/ongoing/When/201x/2012/10/17/Sandman-Pricing
They also are known to adjust prices throughout the day, with noon pricing higher than 2PM pricing, etc.
And here’s an interesting opinion from a lawyer on scraping Amazon’s prices:
http://storefrontbacktalk.com/e-commerce/window-shopping-felonies/
Not a direct answer to your question, Kris, but it’s pretty much the same thing:
http://verdict.justia.com/2012/07/03/the-orbitz-controversy-why-steering-mac-users-toward-higher-priced-hotels-is-arguably-wrong-and-what-might-be-done-about-it
You know RottenTomatoes has a free api?
http://developer.rottentomatoes.com/
Camelcamelcamel does not track digital items such as Amazon Kindle. That was the reason to make the script.
1) We took down his site.
2) I can’t seem to get the code to run in Ubuntu Server 12.04. I get this error:
Traceback (most recent call last):
File “amazon.py”, line 54, in
con = title.contents
AttributeError: ‘NoneType’ object has no attribute ‘contents’
Beautifulsoup is not returning any results on either query. I checked the data being passed, and it is indeed in there. Any advice?
Ok, I’m working on getting it back up. I just tried with 3 books and 1 item and it was working fine. Screenshot:http://imgur.com/grThF5e . I remember I had to handle the title differently than I do normally. I usually use element.string. For the title I had to use element.contents
This is the output from urllib2: http://pastebin.com/pHa58nF9
It’s the version of beautifulsoup you are using causing that problem. Later versions are less forgiving. There’s a lot of talk about it on one of the BS lists.
yahoo pipes is also an easy, quick option
Hooray for scraping! (Big fan here)
Careful – while the laws are grey, some businesses hate when people scrape their data…they tend to try to enforce “using an approved web browser” on their sites, although it’s difficult and expensive for them to actually pursue litigation.
And uh, mind those applications that hammer sites with multiple, simultaneous requests for data…they REALLY hate that one since it’s similar to a DoS attack. ;oP
I’ve been using scraping for heaps of things. I wrote a price tracker for a local computer store in Australia (MSY), I made an XBMC addon that displays sports scores while watching TV, I also wrote an IMDB scraper for XBMC ratings.
The possibilities are endless… but like previously mentioned, be careful not to hammer the site in question!
just wait for the black helicopters to come pick you up to get eaten by lawyers for violating some obscure ToS
The sites dead….
google cache is here:
http://webcache.googleusercontent.com/search?q=cache:rawdust.com/amazon/amazon-kindle-price-alerts.htm
useful tip
http://webcache.googleusercontent.com/search?q=cache:ADDYOURSITEWITHOUTHTTP
…thinks of how many times he’s done this as a freelancer for ebay and amazon with and without APIs…
Google are the only ones you have to use proxies with, you use to be able to use their toolbar query with timeouts…
One does not make Beautiful Soup from Rotten Tomatoes.
Looks like it is from http://www.amazon.com/The-Elegant-Universe-Superstrings-Dimensions/dp/0375708111/ . It is not in stock at Amazon, so it does not have a price available to parse. Try the Kindle edition http://www.amazon.com/The-Elegant-Universe-Superstrings-ebook/dp/B001P7GGRS/ . Also, I take all the referral information from the end of the link (was “ref=tmm_kin_title_0″). I don’t know if it makes a difference, but I like to work with the most direct link.
I’d love to do an app for this on Ebay…I looked at their API awhile ago but it seemed really annoying to use. I just wanted to type in a search and immediately pop up the average price of completed listings over the past week. Anyone point me to a good place to learn how to do this?
Their query restrictions and query types make that only possible with a caching mechanism…
I actually wrote a PHP+curl daemon scraper using their API once, not sure if the company still uses it.
Another nice python alternative is http://packages.python.org/pyquery/
If you prefer Javascript phantomjs is a headless webkit based browser.