
Raindrops on roses, and whiskers on kittens. They’re ok, but state machines are absolutely on our short list of favorite things.
There are probably as many ways to implement a state machine as there are programmers. These range from the terribly complex, one-size-fits-all frameworks down to simply writing a single switch...case block. The frameworks end up being a little bit of a black box, especially if you’re just starting out, while the switch...case versions are very easy to grok, but they don’t really help you write clear, structured code.
In this extra-long edition of Embed with Elliot, we’ll try to bridge the middle ground, demonstrating a couple of state machines with an emphasis on practical coding. We’ll work through a couple of examples of the different ways that they can be implemented in code. Along the way, we’ll Goldilocks solution for a particular application I had, controlling a popcorn popper that had been hacked into a coffee roaster. Hope you enjoy.
What’s a State Machine?
State machines are basically a set of constraints that you set on the way you’d like to approach a problem. Specifically, you try to break your problem down to a bunch of states. In each state, the machine has a given output, which can either depend on a list of variable inputs to the state, or not. Each state also has a list of events which can trigger a transition to another state.
Mapping out your application in terms of what can happen in which state, and then when the machine transitions from one state to the next helps you clearly define your problem. When your code has a structure that makes it easy to plug these concepts in, everything is peachy.
For instance, when you fire up your coffee roaster, it may enter an initialization state, take some actions, and then go straight into a waiting-for-input state. In the waiting-for-input state, there may be two event-driven transitions possible: when one button is pressed it might go into a preheating state where it turns on the fan and heater, or when another button is pressed it might go into a configuration state where it lets you set the desired final roast temperature. The point of defining the states is that they limit when certain actions can happen — you don’t need to worry about setting the roast temperature in the preheating state, for instance.
Picking the right set of limitations to apply to your project’s code gives it structure, and once you get used to the state machine structure, you might find it useful for you. Of course, there are other, grander reasons to think about your problem in terms of a state machine.
One is that they are particularly easy to represent either graphically or in a table, which makes documentation (and later bug-hunting) a lot easier. The other is that, for applications like automatic code generation and automatic FPGA synthesis, there are sophisticated tools that transform your description of the state machine into a finished product without you getting your hands dirty with any of the actual coding.
Hackaday’s own Al Williams recently wrote an article covering state machines in these terms, and his article is a great complement to this one. If you’d like more state machine background, go give his excellent article a read. Here, we’re just interested in making your embedded coding life easier by presenting a few possible design patterns that have stood the test of time.
The Coffee Roaster Application
 A concrete example is worth a thousand words, so let’s start off with a perfect state machine application: controlling a small home appliance. In this case, an air popcorn popper that was hacked into service as a small-batch coffee roaster.
A concrete example is worth a thousand words, so let’s start off with a perfect state machine application: controlling a small home appliance. In this case, an air popcorn popper that was hacked into service as a small-batch coffee roaster.
The former popcorn popper had a fan that blew the popcorn around and a heater that heat up the air before it entered the popping tube. Both fan and heater were on the same circuit, with the voltage drop across the heater coil cleverly chosen so that the remaining voltage could run the fan motor more or less directly. It also had a thermal fuse to keep it from burning up, and an on-off switch. That’s all, and that’s all that’s necessary for the job.
To turn the popper into a coffee roaster, the fan and heater circuits were cut apart and made separately controllable. The fan got its own 16 V DC power supply, switched on an off with a power MOSFET. The heater runs through a solid-state relay to the mains power. Since the roaster was supposed to have temperature control, a thermocouple and amplifier (with SPI interface) were added. This is all tied together by a microcontroller that’s got four user pushbuttons plus reset, two LEDs, a TTL serial in/out, and a potentiometer connected to an ADC channel just for good measure.
Just writing this down gets us a lot of the way toward defining our state machine. For instance, we know what events are going to be driving most of our state transitions: four buttons and a temperature sensor. In practice, the machine also needs to know about elapsed times, so there’s a seconds counter running inside the microcontroller as well.
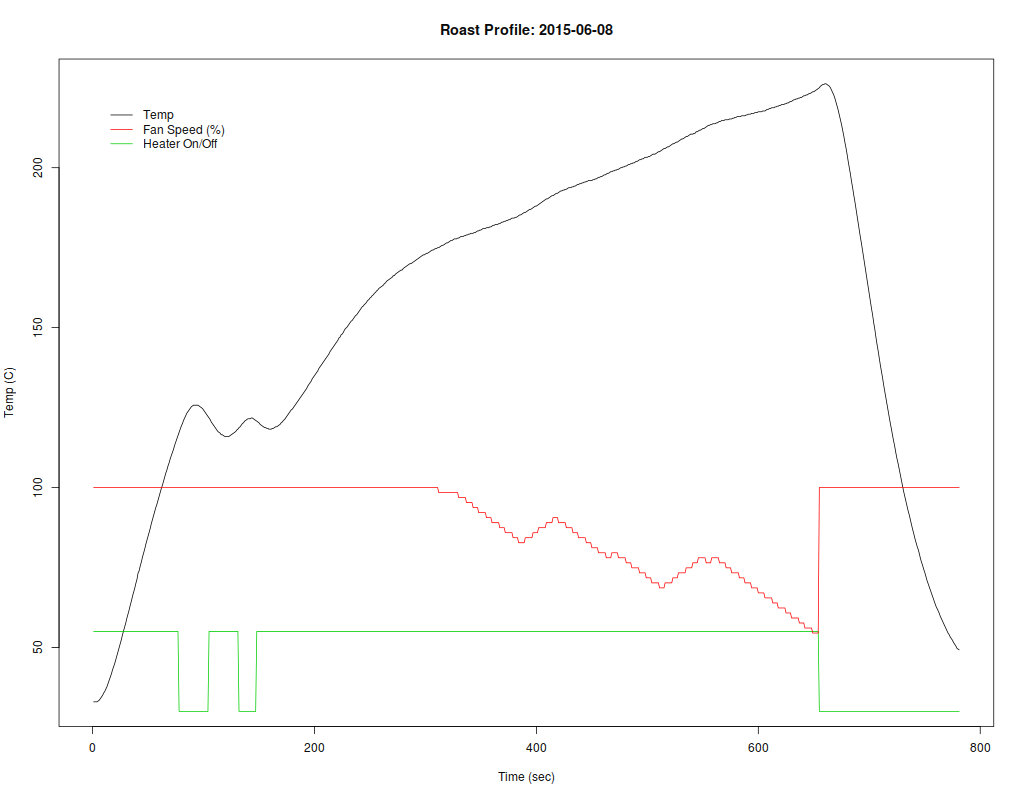 To come up with the relevant states, it doesn’t take much more than thinking about the desired roast profile. It turns out that roasting coffee is a lot like doing reflow soldering: you warm everything up, then ramp up the temperature at a controlled rate to a desired maximum, and then cool it back down again. From the roast profile, we get the states “preheat”, “soak”, “ramp”, and “cooldown” corresponding to the obvious phases of the process. Before the roast starts, the machine also goes through a “initialize” and “wait-for-input” states.
To come up with the relevant states, it doesn’t take much more than thinking about the desired roast profile. It turns out that roasting coffee is a lot like doing reflow soldering: you warm everything up, then ramp up the temperature at a controlled rate to a desired maximum, and then cool it back down again. From the roast profile, we get the states “preheat”, “soak”, “ramp”, and “cooldown” corresponding to the obvious phases of the process. Before the roast starts, the machine also goes through a “initialize” and “wait-for-input” states.
A further “emergency-shutdown” state was inspired by the real-life event where a wire came loose in the temperature probe and the roaster created charcoal instead of coffee. A nice thing about state-machine code is that you know exactly which sections of the code you have to modify when you’re adding a new state, and more importantly, which sections of code you don’t have to touch.
In each of the states the code controls the heater, the fan, and the LEDs, and potentially logs output over the serial port. These are our outputs. In the “preheat” state, for instance, the fan and heater are maxed out and the temperature rise is monitored to make sure that the thermocouple is working. If the panic button is pressed, the soak temperature is reached, or the thermocouple isn’t working, the machine moves on to another state.
With this background in mind, let’s look at two different code structures that can implement the same state machine.
Switch Statements
The simplest implementation of a state machine can be built with a chain of if...then...else statements. “If in state A, do something, else if in state B, do something else”, etc. The nesting and indentation get crazy after only a couple of states, and that’s what the switch...case statement is for. You’ll see a lot of state machines coded up like so:
int main(void)
{
enum states_e {INIT, WAIT_FOR_INPUT, PREHEAT, SOAK, ...};
enum states_e state = INIT;
uint16_t temperature = 21;
while (1){
switch(state){
case INIT:
doInitStuff();
state = WAIT_FOR_INPUT;
break;
case WAIT_FOR_INPUT:
if (buttonA_is_pressed()){
state = PREHEAT;
}
if (buttonD_is_pressed(){
state = SET_TEMPERATURE;
}
break;
case PREHEAT:
fanOn();
heaterOn();
if (temperature > SOAK_START){
state = SOAK;
}
if (test_thermo_not_working()){
state = EMERGENCY_SHUTDOWN;
}
break;
etc.
}
temperature = measure_temperature();
}
}
The code goes in an endless loop, testing which state it’s in and then running the corresponding code. The transitions between states are taken care of inside the handler functions, and are as simple as setting the state variable to the next state name. Instead of using numbers to enumerate the states, the code makes use of C’s enum statement which associates easy-to-read names with numbers behind the scenes. (Alternatively, this could be done with a bunch of #define statements, but the enum is sleeker and arguably less error-prone.)
The INIT state simply does its work and passes on to the next state. WAIT_FOR_INPUT doesn’t change the state variable unless a button is pressed, so the microcontroller spins around here waiting. The PREHEAT state actually starts the roaster going, and tests for the conditions that will bring it out of the preheating phase, namely the temperature getting hot enough or the temperature probe not being plugged in.
The EMERGENCY_SHUTDOWN state was added late in the firmware’s life, and it’s worth looking at where you need to touch the code to add or remove a state. Here it required a new enum entry, a new case statement in the switch to handle its behavior, and then transition code added into every other state that could possibly lead to a shutdown.
Finally, the temperature updating routine is called outside of the state machine. We’re not at all sure how this jibes with the state machine orthodoxy, but it’s a very handy place to have periodically polled actions take place, the results of which could possibly be relevant for the next pass through the state machine.
For small state machines, this style of writing a state machine is straightforward, decently extensible, and it’s pretty readable. But you can see how this could get out of hand pretty quickly as the number of states or the amount of code per state increases. It’s like a very long laundry list.
One possible solution to the sheer length of the switch...case statement is to break each state’s work off into a separate function, like so:
switch(global_state){
case INIT:
handle_init_state();
break;
case WAIT_FOR_INPUT:
handle_wait_for_input_state();
break;
etc.
}
It’s shorter, for sure, and until you have a lot of states it’s not unmanageable. Notice that the state variable must now be made global (or otherwise accessible to each of the state handler functions) because the transitions occur inside each state handler function. If all the code does is implement the state machine, the state probably makes sense as a global variable anyway, so that’s no big deal. A little more disconcerting is that the temperature variable, and every other argument to a state handler, will need to be declared global as it stands now, but let’s just roll with it for a moment.
Wrapping up the switch...case version, you need to do three things when you add a new state:
- add a new state name to the
enum - write your new handler code in its
casestatement - write transitions for all of the states that can lead to the new state
Function Pointers Version
Let’s see what we can do to streamline and simplify the switch...case version of the state machine. Each state name matches with one and exactly one handler function, and the change in handler function is all that differs across states. In other words, the handler function really _is_ the state. The global_state variable that gives a name to each of the states, that we thought of as being the central mechanism, is actually superfluous. Whoah!
We could get rid of the switch...case statement and the global_state variable if only we could store the function that we’d like to call in a variable. Instead of creating this big lookup table from state name to handler function, we could just run the stored state handler directly. And that’s exactly what function pointers do in C.
Function Pointers Aside
Here’s a quick rundown on pointers in general, and function pointers in particular. (We’ll have to do a pointers edition of “Embed with Elliot” in the future, because they’re a source of exquisite bugs and much confusion among people who are new to C.) When you define a function, the compiler stashes that function’s code somewhere in memory, and then associates the name you’ve given to the function with that memory location. So when your code calls the function do_something(), the compiler looks up a memory address where the code by that name is located and then starts running it. So far, so good?
Pointers are variables that essentially contain memory locations, and function pointers are variables that contain the address of code in memory. Pointers do a little more than just store a memory location, though. In the case of function pointers, they also need to know the type of arguments that the function requires and the type of the return value because the compiler needs to be able to set up for the function call, and then clean up after it returns. So a function pointer contains the memory address of some code to run, and also must be prototyped the same way as the functions it can point to.
If we have a couple functions defined, and we want to use a function pointer as a variable that can run either of the two functions, we can do it like so:
int add_one(int);
int add_two(int);
int (*function_pointer)(int);
int add_one(int x){
return x+1;
}
int add_two(int x){
return x+2;
}
int a = 0;
function_pointer = add_one;
a = function_pointer(7); // a = 8;
function_pointer = add_two;
a = function_pointer(7); // a = 9;
What’s going on here? First we declare the functions, and then declare a function pointer that is able to point to these kind of functions. Notice that the function pointer’s declaration mimics the prototypes of the functions that it is allowed to point to.
After defining two trivial functions and a variable to store the result in, we can finally point the function pointer at a function. (That was fun to type!) Behind the scenes, the statement function_pointer = add_one takes the location in memory at which the function add_one is stored, and saves it in the function pointer. At the same time, it checks that the arguments and return value of the add_one function match those of the function pointer, to keep us honest.
Now comes the cool part: we can call the function pointer variable just as if we were calling the function that it points to. Why is this cool? Because we’ve written the exact same code, a = function_pointer(7), and gotten different answers depending on which function is being pointed to. OK, cool, but maybe a little bit confusing because now to understand the code, you have to know which function is being pointed to. But that’s exactly the secret to streamlining and simplifying our state machine!
Function Pointer State Machine
Now, instead of storing the state’s name in a variable and then calling different functions based on the name, we can just store the functions themselves in the state variable. There’s no need for the case...switch statement anymore, the code simply runs whatever code is pointed to. Transitions to another state are achieved by simply changing the handler function that’s currently stored in the state pointer.
It’s time for an example:
void handle_state_INIT(void);
void handle_state_WAIT_FOR_INPUT(void);
void (*do_state)(void);
uint16_t temperature = 21;
void handle_state_INIT(void){
doInitStuff();
do_state = handle_state_WAIT_FOR_INPUT;
}
void handle_state_WAIT_FOR_INPUT(void){
if (buttonA_is_pressed()){
do_state = handle_state_PREHEAT;
}
if (buttonD_is_pressed(){
do_state = handle_state_SET_TEMPERATURE;
}
}
(etc.)
int main(void)
{
// Do not forget to initialize me!!!
do_state = handle_state_INIT;
while(1){
do_state();
temperature = measure_temperature();
}
}
As you can see, all of the per-state code is handled in its own functions, just as in the streamlined switch...case version, but we’ve gotten rid of the cumbersome switch...case construct and the global_state variable, replacing it with a global function pointer, do_state.
Now, when you want to add another state, all you have to do is write the new handler code and then add the transitions from each other state handler that can lead to our new state. Not having to fool around with the state enum is one less thing to worry about.
And note that nothing in the main() body needs to change at all; it calls whatever function is pointed to by the global do_state function pointer, and that gets updated in the state handlers with the rest of the state code.
Style-wise, it’s nice to prototype the functions that get pointed to and the function pointer that will point to them all in the same place because that makes it easy to spot any inconsistencies, which the compiler will thankfully also warn you about.
You might want to split the state handlers off into a separate module, and that’s particularly easy given the above framework. The function and function pointer prototypes go off into the module header, and the functions into the code file just as you’d expect. All global variables required for the handlers will also have to be declared extern in the module header.
Wrapup
There are still some loose ends to tie up here, like dealing properly with the proliferation of global variables that have been used to pass arguments to the state handler functions. A great solution for that case is to pass structs to the handlers that contain all of the relevant arguments, but that’s a tale for another time.
In the mean time, you’re hopefully sold on the possibility of casting some of your microcontroller projects in terms of state machines. Learning state machines is a great excuse to build a simple robot or domestic appliance, for instance. Give it a try. To really grok state machines, it helps a lot to break down some complex behaviors into states, events, transitions, and outputs. Just thinking your project through this way is half the battle.
But then once you’ve sketched the machine out on paper, take the next step and code something up. Start out with some simple scaffolding, either the switch...case variety or the function pointer version, and expand out your own code on it. You’ll be surprised how quickly the code can flow once you’ve got the right structure, and state machines can provide the right structure for a reasonably broad variety of tasks. They really are one of our favorite things!













For C-Sharpers, same thing can be done with Delegate (function pointer).
I run screaming from function pointer shenanigans in my embedded code, but that’s just me. That said, I might be tempted to try it next time just for the hell of it; practically everything I write ends up using one or more state machines anyway.
Don’t run from function pointers. Use them with care, but don’t run. In fact, you are already using them when you use an interrupt handle table. The concept really comes in to its own here when the state machine is described solely by a table, be it an array of structures, parallel arrays, or whatever, and the function pointers are part of the table data. In that case the external func pointer isn’t needed and the code can be dead tight. A well formatted table declaration can make for dead clear code.
Poor design using function pointers is deadly to debug, but that goes for ANY poor design, and isn’t restricted to those using func pointers.
I completely agree with pelrun. When I develop embedded code (most of my time) I follow these rules developed by NASA/JPL: http://spinroot.com/gerard/pdf/P10.pdf
Among these rules there is a big NO function pointers.
This is a fantastic document that I would recommend to everyone working on embedded systems.
Their rationale is that they want to run a model checker against it, effectively trying every combination of scenarios that the program may execute. Useful for NASA (don’t lose a rocket, please) and when developing concurrent systems, which often behave non-deterministically, making them hard to test. I’m, however, not that sure about how useful it is for the quick hacks I assume most readers will use this knowledge for. Also, I’m not sure why the model checker wouldn’t be able to handle function pointers correctly. Maybe it’s a thing of the past?
On the other hand, I agree that one should stay away from seldom-used constructs (for the particular language in use). The solution in this case (we’re upgrading from C to C++ here), is returning a specific type. Then, the model checker hopefully won’t be as confused. Though, both these methods (returning states in one way or another) seems like bad coding practice to me, as it increases the coupling between the different modules (states) in the program. They have to know about each other, possibly in a cyclic fashion. It would be better to set static states and operate on these, spreading the code out into modules based on particular parts of the global state. Oh, right, that’s object-oriented programming, :D
I’ve spent a great deal of time cleaning up “quick hacks” made by myself and others. The flip side of that coin is that doing it “correctly” tends to take so long to implement it might never have been made in the first place. Now I just try to create and maintain good habits, the top habit trying to make things homogeneous. If all the code looks and behaves the same way everywhere, it’s easy to find/fix it because its of the same basic form.
And if you have C++ available, you can use the Gang of Four’s State Pattern! http://gameprogrammingpatterns.com/state.html
Another C++ implementation, using member function pointers. This keeps everything encapsulated in a class, and easily allows to make more instances of the same FSM.
http://pastebin.com/q6iuxmH0
Thanks for those both!
This article is nice, but you failed to discuss the disadvantages of function pointer state machines. I’m not going to complete your article for Eliot but here’s what he neglected to mention:
-Switch statements neatly hold all the logic within 1 clause and even allow fall through for state transitions
-There is more stack manipulation overhead to using function pointers
-Amateur programmers quickly create spaghetti code when they slicing up their code into little functions and disperse these functions throughout their files
Since Eliot doesn’t seem to care about stack space, what is even worse is he is using a global variable to hold the state. This is completely unnecessary as the function could simply return a pointer to the next state!
Then the state is contained on the stack and not in the global space.
You could even have simultaneous multiple state machines operating using the same functions (which Eliot’s design DOES NOT allow).
What is even better than switch statements is using labels as values; the same direct dispatch as function pointers but without the stack overhead.
So this article is pretty good but terribly incomplete.
Why is cutting up little functions bad code? Of course depends on examples but if you use descriptive names and don’t use it to excess it makes it more readable, even if you do or don’t know the codebase.
Absolutely — this really ought to be done with structs to hold the various bits of data and current state. And each state function should return the next state (either as an enum or a function pointer) instead of messing around with globals.
I’ve done this more than once with a main function of the form (note: c-ish pseudocode)
void main (void) {
struct inputStruct inputs;
struct outputStruct outputs;
struct stateStruct stateVector;
int (*currentState)(struct inputStruct, struct* outputStruct, struct* stateVector);
init();
currentState = firstState;
while (1) {
getInputs(&inputs);
currentState = currentState(inputs, &outputs, &stateVector);
writeOutputs(outputs);
}
}
stateVector stores all the internal variables you’d like to keep from one cycle to the next. For many applications, it’s empty. You can also put this on a timer for things where you really need the frame time to be consistent (for example, most controls applications).
No matter how you structure your state machine, each state should be represented by its own function. The core idea of a state machine is that the individual states are discrete and should not interact outside of switching between states and operating on common data. Putting them in separate functions enforces that.
How does ‘ … Putting them in separate functions enforces that. … ‘ work then, given we’re passing global state around?
It’s the same as any other program where you have data that lots of parts of the program need to use. The only parts of the program with access to each part of the state (inputs, outputs, current state, and internal variables) are those that are explicitly given access to them,
Some micros (e.g. 8051 based) are very weak on accessing complex data structures because they only has a single pointer register. You want to avoid doing a lot of pointer dereferencing etc. Also they can have multiple memory space for return stacks (stack pointer is only 8-bit and can only point to internal RAM), but could have variables in internal or external RAM. You really have no choice but to use globals.
You have to understand what you are coding for and adjust accordingly.
I have recently implemented a stateful, multi level menu system using C++ object inheritance. Similar idea to the function pointers, but with fewer globals.
Pretty simple: I have a single class MenuState which contains a variable pointer of type Menu. I have multiple subclasses of Menu, one for each menu screen. Each menu has a function (let’s call it ‘doStuff’) which handles the transition logic to different menus (e.g. if button1 is pressed while in menu1, go to menu2) and performs whatever needed actions are to be done. MenuState has a poll() method, which is called repeatedly from the main loop. Within poll(), the Menu’s doStuff() function is called.
Very simple, but it has the advantages of a) keeping the logic for different menus in different classes (some of the doStuff() functions can get pretty long), b) having clearly defined states (one class / file for each state), and c) being able to keep private variables locally within each class.
It’s not the be-all, end-all approach to state machines, but it is another (somewhat more object oriented) model which can work in some cases.
Cheers
Everything doesn’t have to be global in the switch/case state at all – functions can take parameters…
Oh, and for constrained systems – be aware just how much overhead is used calling functions. Particularly if you’ve got a low register-count system…
Is it? Without parameters to the function, it usually boils down to pushing the return address (a constant, or in this case something that propably already is in a register from the last return call) to the stack and jumping. Often implemented as one instruction (one or a few clock cycles), compare that to the jump/branch used in infinite loops — and, compare it to the rest of the instructions the program exectues.
The inline keyword is your friend.
Except compilers don’t inline calls made through function pointers.
If your functions alway take the exact same set of variables. i.e. it is not reused elsewhere or you don’t need a reentrant function, you can use globals.
For a register constrained micro, that can save the calling overhead as the calling parameters don’t need to be pushed on to that stack and having the function use pointer arithmetic to access the variables. For stupid micro like the 8051, that’s going to save quite a lot of move instruction as it only has a single pointer variable and not enough registers for passing parameters. Also as I have mentioned before, the 8051 stack can only access up to 256 bytes memory. Pushing a lot of stuff only going to use up your stack space and god help you if that blows up.
There are always going to be example that certain good programming practices cannot work in real life due to constraints and in some cases make things less reliable.
This (premature? over-?) optimization is exactly the reason that I left the example state machine this way.
Calling the function-pointer’s function happens _a lot_ in this style of code, and minimizing that overhead is probably worthwhile if you’re going for speed and minimal RAM/stack footprint. Hence, global variables and avoiding unnecessary if statements. (If you really care, you’ll benchmark it.)
It seems to me that do_state() never gets updated in the while loop. Should there be a call to
handle_state_WAIT_FOR_INPUT() in the loop.
do_state() is a pointer to the current state function, and it’s updated within the function it points to. I *GREATLY* prefer to have something like do_state = do_state(), since that makes the update explicit.
I won’t argue against the return-the-next-state version at all! It lets you keep the state function pointer inside main() and makes it very obvious (in main) where the state is getting updated. That’s a totally great way to go.
OTOH, I left it with the global b/c it was more parallel with the switch…case implementation as I wrote it.
No discussion of state engines is complete without mention of protothreads.
Protothreading is a method of cooperative multitasking. It involves taking a function or task that might take a while to complete, and reorganizing it as a state engine that performs a series of smaller tasks. That state engine can then be asked to exit should a higher priority task need to run. Which, if designed properly, it can do within an acceptable amount of time. Then, by calling it again later, it can resume where it left off.
Protothreads are typically used on systems that are too resource limited to allow for a preemptive multitasking kernel to be used. But they have other uses as well.
For example, let’s say you have an SPI bus to which you’ve attached two devices. One is a LCD graphics display, which is rather slow, and operations like a full-screen scroll take up to 160ms. And you’ve just decided to add a sensor, which only takes a couple of us to read, but it must be read within 20us of a particular event occurring or it will be too late. Waiting for the graphics code to complete its current operation is therefore not an option.
Assuming you have or can add a preemptive multitasking kernel, you can run the graphics and sensor code in separate threads, and the sensor thread can preempt the graphics thread. Or you can put the sensor code in an interrupt. But either only gives the sensor code control of the CPU. The graphics code will still have control of the SPI bus. If the sensor code forcibly takes control of the bus, the graphics code won’t have a clue what happened, and when returned to will write corrupted data. Or the sensor thread/interrupt can wait for the release of the SPI bus, but then it will often run too late.
So you must put the sensor on a separate SPI bus. Hopefully, you have one available. You might have thought you wouldn’t need it, and used the pins for something else; in which case you’ll have to do some rewiring and code modifications. Or maybe you’re out of pins or SPI busses, in which case you’ll have to do some more drastic redesign, possibly switching to a different MCU.
But if that graphics code were written as a protothread (or at least using similar principles), it could simply be asked to gracefully release the SPI bus and exit within the required time.
This is a rather extreme example, most protothreads are far simpler than a graphics engine. I use this example because I’m in the process of writing a protothreaded graphics engine. Upon initialization, you pass it how fast you need it to be able to exit, along with a pointer to a global variable that when set, tells it exit is requested. Incoming drawing requests are put in a queue, rather than immediately processed, so as to never block any executing code. When the CPU and SPI bus are idle, the engine runs, and processes the queue. All drawing operations are progressively broken down to subtasks that can be performed in under the required time. It required surprisingly little overhead to do this.
Most of it’s in a single C function, which is typical of protothreads; as they can’t exit quickly if they have to call any long-running functions. It’s a state engine that’s 1,500 lines long, and it will probably be 2,000 before I’m done. Sounds scary, but it’s actually very well organized and readable. The key is maintaining your own stack to simulate function calls. For example, when it needs to draw a line, it it pushes a structure to the stack containing all the parameters and variables required to draw a line, and then proceeds through the necessary states. When drawing a filled circle, it pushes a filled circle structure. Filled circles are decomposed into a series of lines, each processed simply by pushing a line structure, and jumping to the first line state; equivalent to calling a line function. When the line is done, the line struct is popped off, and it returns to the circle state to generate the next line. At the very lowest level, everything is decomposed into a series of SPI pixel transfers, short enough that it can always exit within the required time, and handled by just a few key states. This well-defined hierarchy actually made it very easy to implement alpha blending and user-defined pixel shaders, that work for any drawing operation; I can draw some very fancy shaded and gradient UI elements faster than with any other library, because I can do it in one operation, rather than relying on multiple operations with overlapping drawing. And it will make it very easy to port to other graphics devices, as well.
This, along with my protothreaded Ethernet, and mesh RF network, mean I’ll very rarely require more than one SPI bus.
Oh man. Protothreads is already on my list, but this article was already XXL, and I didn’t even get to get into using structs to contain state-relevant variables.
If the overall topic/idea is “alternatives to OSes for embedded systems”, I see protothreads and state machines as two entirely different sub-topics. Protothreads are more like “keep these 5 plates spinning” and state machines are “first do this, then do this”.
But great comment/reply! And expect to see a protothreads column soon(ish).
“Notice that the state variable must now be made global (or otherwise accessible to each of the state handler functions) because the transitions occur inside each state handler function. If all the code does is implement the state machine, the state probably makes sense as a global variable anyway, so that’s no big deal. A little more disconcerting is that the temperature variable, and every other argument to a state handler, will need to be declared global as it stands now, but let’s just roll with it for a moment.”
I might be missing something here, but why can’y you return a state from your state handlers? And why can’t you pass the temperature as a function parameter?
You absolutely can, and the return-the-state version is great because it’s a bit more defensive-programmingy.
One of the big fears with globals is that you will make confusing spaghetti code by sneaking data from one function to another. In our context, that means that you don’t want to be changing the state pointer outside of the state handler functions unless you have a darn good reason, because it will make the code harder to read/debug later on, and it breaks the (useful) constraints of the state machine framework.
Returning and assigning the state pointer from the handlers makes this explicit, so I guess that’s a good enough reason to do so. I left it the way it was b/c it was more clearly parallel with the switch…case formulation, but maybe I should have taken the next step.
Re: arguments. Because the state handler functions must all have the same prototype (b/c they need to fit the same pointer) you can’t pass different arguments to different states, so you end up passing all the arguments to all the functions. One (great) way to handle this is to wrap them up in a struct, as I alluded to in the article.
But then you’ve got two choices. You can pass the struct by value, which is great b/c it prevents modification of the overall variables from within the handler functions, but can be tough on stack space in small-RAM systems. Or you can pass a pointer to the struct in memory, but then the values inside the struct aren’t protected against abuse from inside a handler function any more, so they might as well be global, IMO.
Cool article. I recently got into writing VHDL for Xilinx FPGAs. I have always ran away from the VHDL and state machine diagrams but once I got used to drawing out the diagrams before trying to implement any code it was very satisfying to get something working. It also helped to go to a single process clocked state machine. All the books teach a multiprocess approach that was hard (for me at least) too actually get running.
I just realized that the name of this series sounds like in-bed-with-elliot
I do enjoy them though, the basics are explained in a clear way.
Another excellent article in your series for beginners. I appreciate how you avoid muddying the waters with optimizations and implementations that would convince beginners that state machines are complicated. The concept of state machines is very simple and powerful. The variations and optimizations can come later. There’s a reason we don’t use James Joyce to teach children how to read.
Thanks again for the series. Keep the articles simple and keep them coming.
You’re a plant! Or you’re me, posting under an alias.
That’s exactly the spirit of the series — trying to cover the intermediate stuff in a way that’s simple enough to enter into, but still not just splashing around in the shallow end of the pool. Woot!
I want to also say thank you for “keeping it simple.” I have read a lot of articles on State Machines, your’s is the first one that I understood enough to (get ready to) code on a microcontroller. Save the refinements for later.
Is there any good free software to draw the state machine diagram?
Honestly, a transition table is a pretty nice way to record what your machine should be doing, and doesn’t require any graphics at all. Which totally doesn’t answer your question.
If you don’t need too many frills you can do it easily in Graphviz. If you do, I’m sure you can do it with some difficulty in Graphviz as well. :)
There must be other stuff out there that’s more specialized to the task, though. Hopefully someone else will chime in with a couple contenders.
Here are 2 articles on the subject of state machines via function pointers, both by the same author:
http://embeddedgurus.com/stack-overflow/2014/03/replacing-nested-switches-with-multi-dimensional-arrays-of-pointers-to-functions/
http://www.barrgroup.com/Embedded-Systems/How-To/C-Function-Pointers
The second one is an in depth article which has multiple examples with increasing complexity.
I discovered this beautiful piece of code recently. Hard to understand but I think it is as minimal as it gets, for the comfort it provides. Certainly worth checking http://www.beningo.com/tools-open-source-circular-buffers/
Best explanation of State Machines using pointers I have come across. Thanks much for removing all the typedef / enum / struct, code in your examples to get straight to the point, or is that pointer?
Aw shucks! Thanks.