The year so far has been filled with news of Spectre and Meltdown. These exploits take advantage of features like speculative execution, and memory access timing. What they have in common is the fact that all modern processors use cache to access memory faster. We’ve all heard of cache, but what exactly is it, and how does it allow our computers to run faster?
In the simplest terms, cache is a fast memory. Computers have two storage systems: primary storage (RAM) and secondary storage (Hard Disk, SSD). From the processor’s point of view, loading data or instructions from RAM is slow — the CPU has to wait and do nothing for 100 cycles or more while the data is loaded. Loading from disk is even slower; millions of cycles are wasted. Cache is a small amount of very fast memory which is used to hold commonly accessed data and instructions. This means the processor only has to wait for the cache to be loaded once. After that, the data is accessible with no waiting.
A common (though aging) analogy for cache uses books to represent data: If you needed a specific book to look up an important piece of information, you would first check the books on your desk (cache memory). If your book isn’t there, you’d then go to the books on your shelves (RAM). If that search turned up empty, you’d head over to the local library (Hard Drive) and check out the book. Once back home, you would keep the book on your desk for quick reference — not immediately return it to the library shelves. This is how cache reading works.
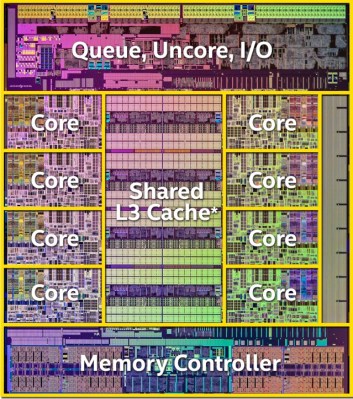
Cache is Expensive Real Estate
Early computers ran so slowly that cache really didn’t matter. Core memory was plenty fast when CPU speed was measured in kHz. The first data cache was used in the IBM System/360 Model 85, released in 1968. IBM’s documentation claimed memory operations would take ¼ to ⅓ less time compared to a system without data cache.
Now the obvious question is if cache is faster, why not make all memory out of cache? There are two answers to that. First, cache is more expensive than main memory. Generally, cache is built with static ram, which is much more expensive than the dynamic ram used in main memory. The second answer is location, location, location. With processors running at several GHz, cache now needs to be on the same piece of silicon with the processor itself. Sending the signals out over PCB traces would take too long.
The CPU core generally doesn’t know or care about the cache. All the housekeeping and cache management is handled by the Memory Management Unit (MMU) or cache controller. These are complex logic systems that need to operate quickly to keep the CPU loaded with data and instructions.
Direct Mapped Cache
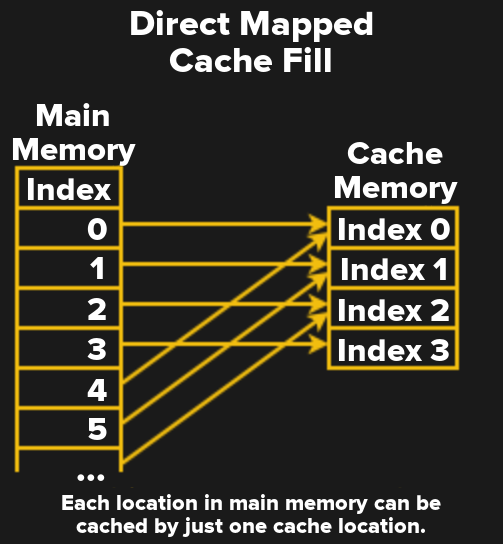 The simplest form of a cache is called direct mapped cache. Direct mapped means that every memory location maps to just one cache location. In the diagram, there are 4 cache slots.This means that Cache index 0 might hold memory index 0,4,8 and so on. Since one cache block can hold any one of multiple memory locations, the cache controller needs a way to know which memory is actually in the cache. To handle this, every cache block has a tag, which holds the upper bits of the memory address currently stored in the cache.
The simplest form of a cache is called direct mapped cache. Direct mapped means that every memory location maps to just one cache location. In the diagram, there are 4 cache slots.This means that Cache index 0 might hold memory index 0,4,8 and so on. Since one cache block can hold any one of multiple memory locations, the cache controller needs a way to know which memory is actually in the cache. To handle this, every cache block has a tag, which holds the upper bits of the memory address currently stored in the cache.
The cache controller also needs to know if the cache is actually holding usable data or garbage. When the processor first starts up, all the cache locations will be random. It would be really bad if some of this random data were accidentally used in a calculation. This is handled with a valid bit. If the valid bit is set to 0, then the cache location contains invalid data and is ignored. If the bit is 1, then the cache data is valid, and the cache controller will use it. The valid bit is forced to zero at processor power up and can be cleared whenever the cache controller needs to invalidate the cache.
Writing to Cache
So far I’ve covered read accesses using cache, but what about writes? The cache controller needs to be sure that any changes made to memory in the cache are also made in RAM before the cache gets overwritten by some new memory access. There are two basic ways to do this. First is to write memory every time the cache is written. This is called write-through cache. Write-through is safe but comes with a speed penalty. Reads are fast but writes happen at the slower speed of main memory. The more popular system is called write-back cache. In a write-back system, changes are stored in the cache until that cache location is about to be overwritten. The cache controller needs to know if this has happened, so one more bit called the dirty bit is added to the cache.
Cache data needs all this housekeeping data — the tag, the valid bit, the dirty bit — stored in high-speed cache memory, which increases the overall cost of the cache system.
Associative Cache
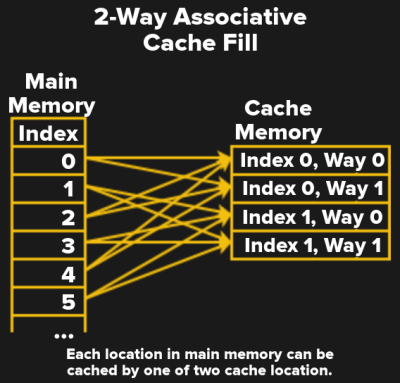 A direct mapped cache will speed up memory accesses, but the one-to-one mapping of memory to cache is relatively inefficient. It is much more efficient to allow data and instructions to be stored in more than one location.
A direct mapped cache will speed up memory accesses, but the one-to-one mapping of memory to cache is relatively inefficient. It is much more efficient to allow data and instructions to be stored in more than one location.
A fully associative cache allows just that — any memory location can be stored in any cache location. This also means the cache must be searched on every memory access. A search function like this is done with a hardware comparator. A comparator like this would require lots of logic gates, and eat up a large physical area on the chip. The happy medium is a set associative cache. The diagram shows a 2 way set associative cache. This means any memory location can go in one of two cache locations. That keeps the hardware comparator relatively simple and fast. As an example, the Intel Core i7-8700K Level 3 cache is 16-way set associative.
Virtual Memory
In the beginning, computers ran one program at a time. A programmer had access to the entire memory of the system and had to manage how that memory was utilized. If his or her program was larger than the entire RAM space of the system, it would be up to the programmer to swap sections in or out as needed. Imagine having to check if printf() is loaded into memory every time you want to print something.
Virtual memory is the way an operating system works directly with the processor MMU to deal with this. Main Memory is broken up into pages. Each page is swapped in as it is needed. With cheap memory these days, we don’t have to worry as much about swapping out to disk. However, virtual memory is still vitally important for some of the other advantages it offers.
Virtual memory allows the operating system to run many programs at once — each program has its own virtual address space, which is then mapped to pages in physical memory. This mapping is stored in the page table, which itself lives in RAM. The page table is so important that it gets its own special cache called the Translation Look-aside Buffer, or TLB.
The MMU and virtual memory hardware also work with the operating system to enforce memory protection — don’t let programs read or modify each other’s memory space, and don’t let anyone mess with the kernel. This is the protection that is sidestepped by the Spectre and Meltdown attacks.
Into the real world
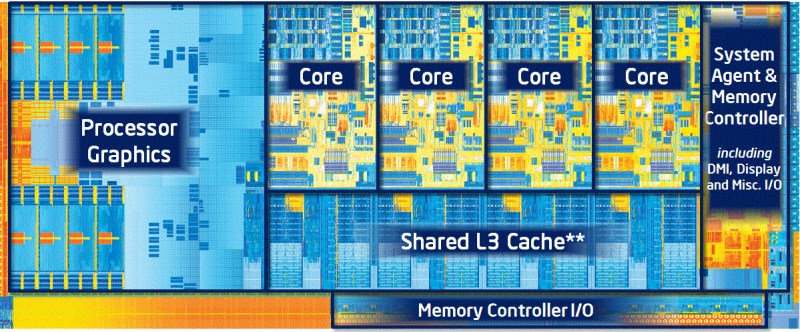
 As you can see, even relatively simple cache systems can be hard to follow. In a modern processor like the Intel i7-8700K, there are multiple layers of caches, some independent, some shared between the CPU cores. There also are the speculative execution engines, which pull data that might be used from memory into cache before a given core is even ready for it. That engine is the key to Meltdown.
As you can see, even relatively simple cache systems can be hard to follow. In a modern processor like the Intel i7-8700K, there are multiple layers of caches, some independent, some shared between the CPU cores. There also are the speculative execution engines, which pull data that might be used from memory into cache before a given core is even ready for it. That engine is the key to Meltdown.
Both Spectre and Meltdown use cache in a timing based attack. Since cached memory is much faster to access, an attacker can measure access time to determine if memory is coming from RAM or the cache. That timing information can then be used to actually read out the data in the memory. This why a Javascript patch was pushed to browsers two weeks ago. That patch makes the built-in Javascript timing features a tiny bit less accurate, just enough to make them worthless in measuring memory access time which safeguards against browser-based exploits for these vulnerabilities.
The simple knee-jerk method of trying to mitigate Spectre and Meltdown is to disable the caches. This would make our computer systems incredibly slow compared to the speeds we are used to. The patches being rolled out are not nearly this extreme, but they do change the way the CPU works with the cache — especially upon user space to kernel space context switches.
Modern CPU datapath and cache design is an incredibly complex task. Processor manufacturers have amassed years of data by simulating and statistically analyzing how processors move data to make systems both fast and reliable. Changes to something like processor microcode are only made when absolutely necessary, and only after thousands of hours of testing. A shotgun change made in a rush (yes, six months is a rush) like the current Intel and AMD patches is sure to have some problems — and that is exactly what we’re seeing with big performance hits and crashes. The software side of the fix such as Kernel Page Table Isolation can force flushes of the TLBs, which also come with big performance hits for applications which make frequent calls to the operating system. This explains some of the reason why the impact of the changes is so application dependent. In essence, we’re all beta testers.
There is a bright side though. The hope is that with more time for research and testing on the part of the chip manufactures and software vendors, the necessary changes will be better understood, and better patches will be released.
That is, until the next attack vector is found.














While they are reported together, the two issues have a very important difference: Meltdown crosses a privilege domain. Intel’s CPU design means that the speculation engine doesn’t bother to check the permission bits in the TLB before completing. If it threw a pipeline bubble when permissions were violated, Meltdown would be impossible. Sure, it slows down the slow path, but that’s already going to trigger an exception if it actually gets called. Meltdown is a design flaw.
Spectre is a scary exploit, but it’s not really a design flaw in the CPU (except for the case of certain CPUs that will also allow permission bits to be bypassed as well). No mainstream CPU architecture has an MMU intended to protect a process from itself, so allowing an application to attack itself is not a threat model that’s really been given much thought. Unfortunately, this is the model we see with embedded scripting in browsers. It’s a shame we don’t have MMU assistance there.
+1 to Chrome for running separate tabs in separate processes (?), instead of as separate threads or a single process.
Incidentally, this also causes people to hate on Chrome for eating all your RAM as a light snack.
Chrome is still open to an attack, while it’s easier to do the attack against software based protection (things running in the same process but hidden by bounds checks) it is still possible to do against another process as long as they share resources (e.g. caches).
Not bad. Wonder if this exercise can be simulated? Certainly is an education on how complicated CPUs are.
Actually the mitigations used at the moment for Spectre aren’t cache related but reduce the chance a attacker can influence the victim via the branch predictor mechanism. That includes making it much harder to hack the indirect branch predictor (retpoline takes advantage of how most processors handle function returns, IBRS and IBPB are microcode hacks). Similar on non-x86 processors.
For Meltdown it isn’t the working of cache that is changed either but what memory is mapped visible for user processes, if memory with sensitive data isn’t mapped into the user address space it can’t be accessed with Meltdown. Yes it indirectly involves the TLB which is a cache of the mapping _but_ it continues to work as it have always done. Absolutely no change.
Future fixes will probably make sure caches are accessed in a different way so that speculative reads can’t be detected if aborted. Then the branch predictor attacks doesn’t really matter (can only reduce performance). Meltdown will be fixed if permissions are checked before doing an access – which is already the standard for most processor designers, not Intel though.
It is so cool to be living in a time where a machine is called a “speculative engine”.
Imagine in a few years when we have closed time-like curve stacks and other such crazy sci-fi.
The guessing machines.
“That timing information can then be used to actually read out the data in the memory.” – the key to the whole attack.
Would be great to get more info on how that timing information allows the actual data to be read. It’s once thing knowing whether the memory has to be read or if it’s already in cache (from the timing), but how does that reveal the data in memory?
Hey Dave, Mike’s earlier article on Spectre and Meltdown covered some of this – but one of the best explanations I’ve seen showed up in the comments from [Alan Hightower] check it out here: https://hackaday.com/2018/01/05/lets-talk-intel-meltdown-and-spectre/#comment-4291735
To continue using the same speculative architecture there simply needs to be an update to the chips and or software that allows for the timings to constantly fluctuate at random intervals; & or encrypts all data at the cache level.
Encryption is too expensive, anything that is secure enough would be so slow it would wipe out the benefit of caching. The full solution (one which would require a change to the die) is to do a range comparison on the address that is speculatively fetched (before speculative execution there is a speculative fetch). If the requested address is not in the allocated memory range for the process the speculative fetch does not occur. No speculative fetch = no speculative execution.
Randomize timing isn’t a valid fix and would be much harder than you (and I before thinking about it). It would have to inject so much noise that speculative execution would be hidden – so just removing it entirely would be a better choice.
Encrypting cache data or memory wouldn’t do anything either as the Spectre attack makes a process with access read the data. If a program can’t read its private data it simply can’t run.
Dull as shit, but I suppose it helps the SEO a lot. So anyway, about your dogs, what breeds would you get?
how to access ring -3 in minix?
ask to NSA Deparment inside Intel HeadQuarter…