
This past semester I added research to my already full schedule of math and engineering classes, as any masochistic student eagerly would. Packed schedule aside, how do you pass up the chance to work on implementing 360° virtual teleportation to anywhere in the world, in real-time. Yes, it is indeed the same concept as the cult worshipped Star Trek transporter, minus the ability to physically be at the location. Perhaps we can add a, “beam me up, Scotty” command when shutting down.
The research lab I was working with is the Laboratory for Immersive CommunicatiON (LION). It’s funded by NSF, Microsoft, and Adobe and has been on the pursuit of VR teleportation for some time now. There’s a lot of cool technologies at work here, like drones which are used as location collection devices. A network of drones will survey landscape anywhere in the world and build the collection assets needed for recreating it in VR. Okay, so a swarm of drones might seem a little intimidating at first, but when has emerging technology not?
Gaining Speed by Minimizing the Un-Looked-At
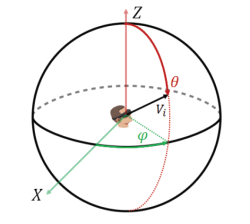
During a 360° video, a grid of sorts can be overlain across the entire view port, as shown above. This grid can be broken into a certain number of relevant spatial tiles, which is something that turns out to be much more palatable to work with when capturing Head-Mounted Display (HMD) of a user. This initial grid allowed us to integrate the relative user view navigation patterns to create a framework for view port-driven rate-distortion optimized 360° video streaming.
This was obviously done to maximize the user’s experience during their 360° video usage while keeping the run-time as efficient as possible with the given network and system resources. There were two 360° videos that we focused our efforts on. After having a large data set of user’s HMD to work with, dynamic heat maps were generated which captured the likelihood of navigating into different tiles of the overlain grid. This visual aided in seeing the different trends in each video that multiple users shared. As expected, it was found that the tiles in the center of the user’s field of vision were the most often viewed by far for both videos tested. Humans are lazy creatures.
Rate-distortion with bit-rate was also a component of this project, although I was less involved on that side. One known issue with 360° video streaming is that traditionally the entire 360° view sphere must be delivered to the user to reduce simulator and/or motion sickness. However, instead of loading the entire 360° sphere, we encoded the 360° videos to minimize the data rate assigned to the various 360° regions not often navigated in our generated heat maps.
Optimized efficiency was the pressing force throughout the entirety of this project. The end-goal was to have a neural network that could take the training it had used in the videos of the registered users, and then transfer that to live videos with the same users.


The proposed optimization was compared to both speed-based and monolithic rates on the right in each of the two videos. The same pattern can be seen in all three methods, however the proposed method has the best quality across the board.
Technical Approaches
I had a hodgepodge of different ideas to try to optimize the 360° VR view port data by processing various user’s HMD. In plain English, the past user’s HMD would theoretically give enough information to reliably predict which tile(s) in the view port needed higher resolution for a certain period of time in that particular video. By training a neural network with the yaw, pitch, and roll of each frame in a group of pictures (GOP), the goal was to be able to accurately predict where a user would look next. To think of it in a simpler way, the HMD output essentially a vector for the exact location of a user’s focus point when time was taken into account as a variable.
The first method we attempted was working with time series prediction in a nonlinear autoregressive network with exogenous inputs (NARX) in MATLAB. We initially used yaw and pitch from the HMD as inputs for this – it was quickly learned that roll was not nearly as important as yaw and pitch in these two videos as it had a relatively constant rate throughout the entirety of the display. We then thought to add the image data to the time series network, simply to see if it affected it positively or had no change at all. There were several issues that popped up with adding the image data into the NARX network, but one of the most persistent ones was getting the bloody images to format properly. All of our image data was in a 1×60 cell array (GOPs) of 32×32 cell arrays (frames). This, understandably, could not be taken as an input for the network. Unlike the sequences of yaw and pitches, which were single values, we had a sequence of images whose values were stored as matrices. We looked at different ways to go about inputting the image data to potentially improve the time series, but we sadly ran out of time before the seemingly short semester came to a screeching halt.
One of the most classic uses of deep learning currently is image classification (think identification). We were interested in training our data with a predetermined network, GoogLeNet, to implement the frame data using image classification as a new angle. The thought was to break either of the videos into each frame, gather information within each layer, and then add the yaw and pitch data into the last two layers of the convolutional neural network (CNN). Unfortunately, we did not have an updated version of MATLAB available to us that actually supported GoogLeNet. Darn you, wallet.
Had we been able to complete that testing, we planned to additionally try working with a Hidden Markov Model for prediction. Whether or not you happen to be caught up with what the cool kids are doing with machine learning these days, Markov is a name that is sure to sound familiar. Upon completion of all of these different predictions, it would have been very interesting to compare the results and see which method ended up being most effective with our study.
Continued Research
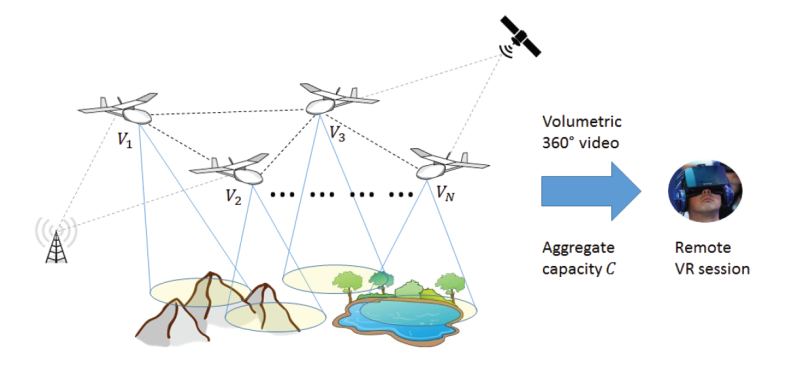
The reconstruction quality of the specified landscape sent to the user from the drone network will vary on a number of factors that are currently being worked out. Machine learning that can optimize the path planning with the swarm configuration will be a top priority in the near future as well. This is cutting edge research that I will hopefully be able to join in on when I return in the fall is very exciting for this field of technology.
 As with any research, the walls you run into outnumber the breakthroughs. Clearly, advancements must still be made with real-time HMD prediction. However, every inventor/scientist/hacker worth any merit has gone through this same seemingly bleak void of successful progress at some point during their intellectual career. The good ones just never stop trying.
As with any research, the walls you run into outnumber the breakthroughs. Clearly, advancements must still be made with real-time HMD prediction. However, every inventor/scientist/hacker worth any merit has gone through this same seemingly bleak void of successful progress at some point during their intellectual career. The good ones just never stop trying.
I wish all of the students I had the pleasure of working with in the lab good luck in their studies. I would also like to especially thank Jacob Chakareski for giving me the opportunity to contribute to his research.














Are you new here Lauren?
Doh! Guess not!
Well this will certainly come in handy as a visual archive as we destroy more of the environment. Only problem is the number of things to record makes the task rather incomplete.
It is almost exactly like “viewing”, a major element in ‘The Naked Sun’. 1956, Asimov. Or “Projecting” in the Skylark stories around 1928 to 1934.
Hi Lauren, I appreciate your write up. I know you didn’t ask for ideas and it sounds like you have left the project but it sounds like the team could benefit from some of the compression approaches in h.264 and h.265 video encoding. They have a raft of tricks which include change of different size blocks of pixels, rather than individual pixels (could the ML help?) and defining part of the current frame based on differences not only of past frames but also future frames. I’m not competent in video encoding but I have been reading into h.264 compression recently and there appears to be several links to the kinds of challenges LION is working on in your article above.
the cloud will become a literal cloud of drones. i like it.