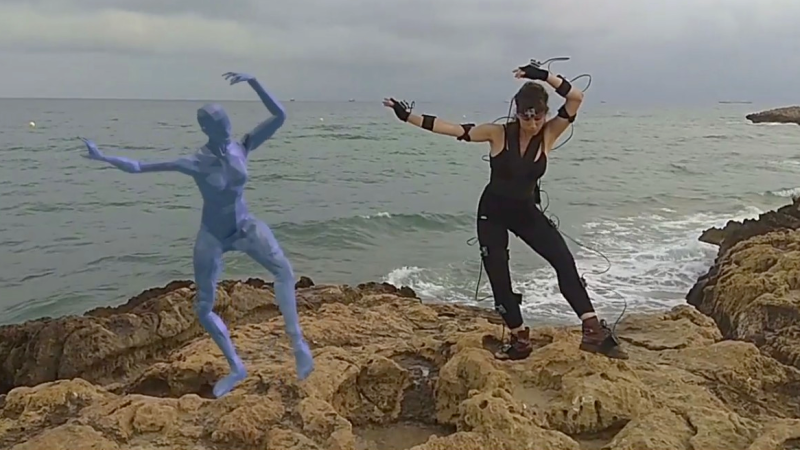
[Chordata] is making a motion capture system for everyone to build and so far the results are impressive, enough to have been a finalist in the Hackaday Human Computer Interface Challenge. It started a few years ago as one person’s desire to capture a digital performance of a dancer on a stage and has grown into a community of contributors. The board files and software have just been released as alpha along with some instructions for making it work, though more detailed documentation is on the way.
 Fifteen sensor boards, called K-Ceptors, are attached to various points on the body, each containing an LSM9DS1 IMU (Inertial Measurement Unit). The K-Ceptors are wired together while still allowing plenty of freedom to move around. Communication is via I2C to a Raspberry Pi. The Pi then sends the collected data over WiFi to a desktop machine. As you move around, a 3D model of a human figure follows in realtime, displayed on the desktop’s screen using Blender, a popular, free 3D modeling software. Of course, you can do something else with the data if you want, perhaps make a robot move? Check out the overview and the performance by a clearly experienced dancer putting the system through its paces in the video below.
Fifteen sensor boards, called K-Ceptors, are attached to various points on the body, each containing an LSM9DS1 IMU (Inertial Measurement Unit). The K-Ceptors are wired together while still allowing plenty of freedom to move around. Communication is via I2C to a Raspberry Pi. The Pi then sends the collected data over WiFi to a desktop machine. As you move around, a 3D model of a human figure follows in realtime, displayed on the desktop’s screen using Blender, a popular, free 3D modeling software. Of course, you can do something else with the data if you want, perhaps make a robot move? Check out the overview and the performance by a clearly experienced dancer putting the system through its paces in the video below.
As a side note, the latest log entry on their Hackaday.io page points out that whenever changes are made to the K-Ceptor board, fifteen of them need to be made in order to try it out. To help with that, they show the testbed they made for troubleshooting boards as soon as they come out of the oven.

















I’m a bit surprised the LSM9DS1 is capable of this. I spent some time trying to do translational and rotational tracking with just one, and accelerometer error would build up so quickly that the board thought it was speeding away at 20 MPH within seconds of power-on.
Maybe having multiple sensor points, and knowing that they have to somehow fit onto a human skeleton, aids in the fusion?
On further consideration, knowing that the nodes map to a rigid skeleton absolutely helps with the fusion. You don’t need to track translation at all! Since you know that each node is a constant distance from its child and parent, you can get the child’s position by projecting that set distance along the rotation. Set the root node as fixed in space, and you’re golden!
As you said, position tracking with IMUs is not directly possible. On this (and as far as I know all) mocap system just the orientations are used, and the joint locations are a consequence of the constant lengths of the body parts and fixed root. Once you have the pose in motion there are many indirect procedures to make it translate in space.
To get an accurate result with these kind of sensors the calibration is crucial. We are now preparing a complete guide on how the system can be built, and we dedicate a complete chapter to the calibration procedure.
Fabulous, thank you. :)
Is there a way to easily wirelessly update and connect all of the boards?
You could probably plonk an ESP8266 in each sensor node, but then you’ve added a microcontroller + support components to the BOM for each node. That, and a battery, and power control systems. It would be a fancier system, but much more expensive.
Dahud is right,
our idea was to make the base mocap framework as simple and economic as possible which in this case means using plain old cables with the native protocol that the sensors use.
Once the documentation is out it would be great to see smarter applications of the system, like a wireless connected one!
I would look towards some nRF51’s
interestingly they used a dedicated chip, an I2C address translator, to bypass the (damn stupid) limitation of two or four I2C addresses for this kind of chip (Invensense can you hear me???). My attempt at that was more hacky, using analog mux-ers but resulted in the lowest possible latency…
When I started this project I used digital i2c multiplexers on each node, but they added unnecessary overhead, since I had to perform a write to open, and another to close each Mux.
Then I found the address translator which is a little more expensive, but acts in a completely invisible manner. It just rearrange the address part of the message on the fly. From the master point of view is like talking with a device with a different address.
already outdated by simple vision systems
My thoughts exactly. This doesn’t *at all* seem the easiest way to do this.
If you want to do it in a studio, sure. This would be interesting for naturalistic outdoors movement though.
I think posenet works pretty well for this: https://github.com/tensorflow/tfjs-models/tree/master/posenet works outdoors just fine.
Comparing mocap technologies in like comparing cat and dogs: they both eat meat and have four legs, but thinking in terms of which is “better” is just wrong.
Multi camera optical systems are by far the most precise, but they are really expensive and have a limited capture space.
On the other hand monocular capture systems supported by AI algorithms are a really cool technology, and the most comfortable indeed. But they require lots of computer power, most of the time provided by a multiGPU cloud computer. Those beast are not cheap, so that kind of service would mostly by implemented as a subscription model. You would probably have to pay for each capture you process, the results won’t be in real time, and most important no one will never get to see the algorithm.
Posenet is great, is publicly available and it can also work with low computational-capable devices delivering results in real time. But as you can see on the many demo-videos available is far from been as accurate as an inertial based mocap system. And it gives you just bidimensional data: X-Y coordinates of each point.. that kind of information is useful in many areas, but you can’t rig a videogame character for example.
We will probably see great advances on capturing AI algorithms in the following years, but the current ones just can’t do what more “traditional” approaches can.
That chick on the right must be cold, she has no clothes on and is turning blue!
That’s why she’s dancing, she wants to warm up.
Simplest way is based on deep learning: https://blogs.nvidia.com/blog/2018/05/08/radical-3d-motion-capture/
interesting to see that both the “advertisement” and the layout of nodes looks a lot like Rokoko’s SmartSuit (just without the suit). They were promising heaven on earth and seem still to be stuck half-way to hell trying to make the software cope with measurement noise … not trivial!
Wow, such a honor been mentioned on this Blog. Thank you guys!!
The pleasure’s ours. Thanks for sharing your awesome work!
Can you get better accurate if you using raspberry pi4(more power = better sample rate) or more raspberry pi3(more i2c = better sample rate) or the problem is in the sensor accurate? Is your calibration good because the final animations has to many glitches and can you make better calibrations for better results that this or can I get better results with more expensive and good sensors?
Just looking for cheap motion track they sell for 1200€ srs and 50€ shipping srs it sent from Mars?