Even though machine learning AKA ‘deep learning’ / ‘artificial intelligence’ has been around for several decades now, it’s only recently that computing power has become fast enough to do anything useful with the science.
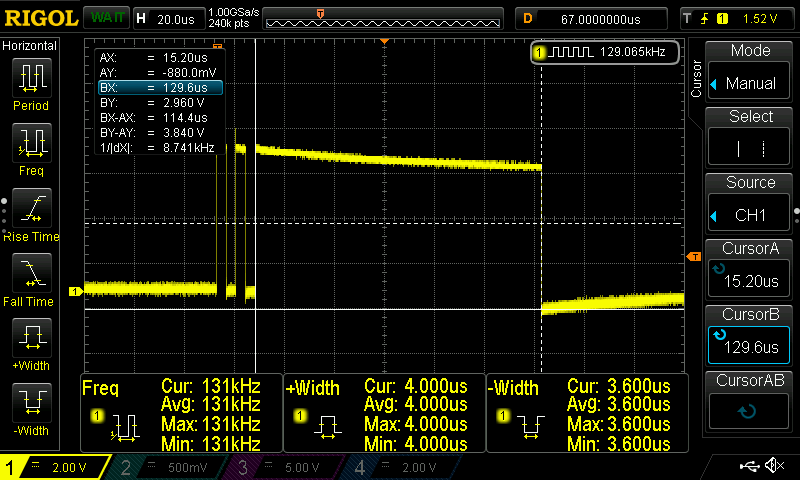
However, to fully understand how a neural network (NN) works, [Dimitris Tassopoulos] has stripped the concept down to pretty much the simplest example possible – a 3 input, 1 output network – and run inference on a number of MCUs, including the humble Arduino Uno. Miraculously, the Uno processed the network in an impressively fast prediction time of 114.4 μsec!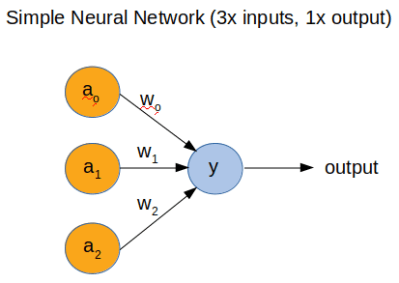
Whilst we did not test the code on an MCU, we just happened to have Jupyter Notebook installed so ran the same code on a Raspberry Pi directly from [Dimitris’s] bitbucket repo.
He explains in the project pages that now that the hype about AI has died down a bit that it’s the right time for engineers to get into the nitty-gritty of the theory and start using some of the ‘tools’ such as Keras, which have now matured into something fairly useful.
In part 2 of the project, we get to see the guts of a more complicated NN with 3-inputs, a hidden layer with 32 nodes and 1-output, which runs on an Uno at a much slower speed of 5600 μsec.
This exploration of ML in the embedded world is NOT ‘high level’ research stuff that tends to be inaccessible and hard to understand. We have covered Machine Learning On Tiny Platforms Like Raspberry Pi And Arduino before, but not with such an easy and thoroughly practical example.














I’m sure you’re going to get this comment a few hundred times, but this statement is wrong and/or misleading: “machine learning AKA ‘deep learning’.”
Machine Learning is a large Field of study in which one of the Sub-Fields is Artificial Neural Networks and Deep Artificial Neural Networks (aka. Deep Learning). Deep Learning is not the only Sub-Field of Machine Learning, it’s just the one getting the most attention right now.
It would be akin to me saying, “Internet of Things, AKA ‘Raspberry Pi'” or some other statement that show my knowledge is only skin deep.
Note: his networks were not “Deep” NN’s, and I think you were careful to avoid calling his deep, it might be worth it to mention, in the article that they are not Deep NNs, but simply a smaller example, that would be considered a normal (A)NN.
Gripe:
“a 3 input, 1 output network … Miraculously, the Uno processed the network in an impressively fast prediction time of 114.4 μsec”
Assuming he’s using a linear activation function, that amounts to 3 multiplications and 2 additions, even at a slow 16Mhz, that seems like a lot of clock cycles for such simple math.
Agreed, this article needs major redacting.
THIS.
The maths are -definitely- easy. Especially for those simple NN.
The point was to benchmark simple NN on various MCUs and compare how they handle the models. I guess most engineers when it comes to the ML, they know what it is, what it does, but they don’t get into the details and the maths and in the end they may just skip the whole thing because it seems complicated.
Also now I can see a number. I know that a 3-32-1 NN takes ~6ms in the Arduino-Uno. That’s a valuable information.
Of course it can get really complicated, but still if you don’t experiment with it you don’t know.
Also, I didn’t find any other related post that implements simple NN on MCUs and tests the performance on various MCUs. I think these tests are valuable and there’s still a huge gap in the low embedded domain. You may find some tools here and there, like utensor or X-CUBE-AI, but there’s still a lack of a generic lib that works on any MCU and be able to import Keras models and experiment. So, the low embedded domain it’s still a quite unexplored area. And this is what the post is all about.
I’m glad the article was useful to you.
I guess it was useful to me, because I’ll never ever even try to run a DNN on an Arduino. If an 128 parameter network took 6ms, then it’ll never run anything even mildly useful in reasonable time (even on a 10x or 100x faster chip).
My complaining was about the misleading information in the hackaday article. And yes, on a low power device like the uno, 100 μsec is fast, but the article uses such superfluous language that is seems like it’s a huge scientific break through. This is the equivalent of me writing: “print(2+2)” and being amazed that it was an impressively fast 3ms.
I was giving [Dimitris’s] article some space because, as he said, it’s a stupid project to try something out. But he also said performance is what matters, and what his goal with this is.
I must complain, his “dataset” is stupid, and in reality he’d be better off using random numbers from a text file as test/train data.
If he is doing this as a benchmark, did he do standard NN optimization, like quantization? No? Did he use a real dataset? No? Did he write his own, unoptimized code? It looks like it? Did he benchmark the timing for 1 prediction, 10, 100, or a thousand predictions per run? Did he run the test multiple times to average the results?
From what I see, he probably is not using quantization, which would have reduced it from 32bit float multiplication to 8bit float multiplication. My guess is that the 32bit floats would be much slower on those chips than 8bit.
Additionally, I suspect that all the performance that is bad besides the multiplication is due to loading things into memory and other overhead. Did he even do a null performance test? That is, run all the code except the multiplication? My guess is the NN didn’t take that long to run, but everything else did take a while.
Performance is important, but fair and quality benchmarks are needed to have any idea of the performance. [Dimitris’s] at least tried to provide data on it, which I appreciate, but the Hackaday article doesn’t really provide any benefit beyond exposure.
Also, for comparison, the Google coral edge you that lets a Raspi run NN at good speeds. It could run the 3-32-1 NN 62 million times per second, or 6 thousand times faster (I did quick math, sorry if I made a mistake).
It does 8,000 giga operations per second, and only takes 4 watts to do so. NOW that is “impressively fast”
“An individual Edge TPU is capable of performing 4 trillion operations (tera-operations) per second (TOPS), using 0.5 watts for each TOPS”
https://coral.withgoogle.com/docs/edgetpu/benchmarks/
Sorry, my comments were a bit too harsh. I guess it’s just been one of those days.
No worries! On the up side, we’re now much clearer about what the correct terminology should be.
Interesting because more controllers and processors are going to be coming with some sort of A.I. accelerator. It’s a buzzword, but also a use case from assistants to cleaning up photos. There’s certainly plenty of material, both free and paid, explaining all the math, and concepts behind DL.
“but also a use case from assistants to cleaning up photos” What are you using a case for? To clean up photos? What kind of case?
Spot on. Not the most informed article I’ve read this morning
Yup. Article seems to highlight the fact that the author doesn’t actually know much about AI/Machine Learning/Deep learning etc at all. The “Deep” in deep learning literally means “lots of layers in the ANN.” Shallow ANNs have been around for decades, “Deep” is more recent. Or rather, it was infeasible to train a deep network before modern video cards gave us super-cheap processing and modern storage could let us build databases of terabytes of data to train on.
This is closer to a perceptron, which has been around since the late 1950s.
Give them some credit, they never mentioned the word “deep” in a way that directly connected it to these networks. But they got close to saying it.
I totally agree.
The Uno was far from the fastest in the test results.
You’d also need to need to carefully look at the code that was used for the test, because the processor architecture in the Uno is totally different from the Teensy / STM32 which is different again from the ESP8266.
And the variables types and also the code structure could significantly affect the result, because of things like the ARM instruction pipeline and cache etc etc
Arduino is overpriced for what you get.
It’s like ordering a well pedigreed sample, and getting some random mutt.
Including the Chinese clones?
One of the advantages is all the shields erc.
But the brand name Arduinos are pricey.
I wouldn’t say it’s too overpriced, it’s targeted at teaching newcomers the art of microelectronics and circuit design. They use an easy to learn development ecosystem and can be bought for a few bucks a board now. I’d say that is pretty cheap actually, considering they aren’t meant for permanent product placement and only really for development. Sure, it isn’t an ARM board for a few bucks but learning to program an ARM chip is considered more advanced anyways. I cut my teeth on an UNO and it opened a lot of doors to learning more advanced concepts. I think the biggest issue is people, in general, love to hate it because it brought a bunch of novices into a field that was built from the hard work of classical mcu development. It’s like a “back in my day we walked to school uphill both ways, in the snow,” version of electronics knowledge.
Shall we call this answer 43 from now on? Saves typing and time.
Back in the 1980’s we used ARM. What is everyone using now ;-)
How would this perform on the 180-240Mhz Teensy 3.6? If it runs on an Uno, it should run on any Teensy.
From memory, I think he tested a Teensy as well. It’s in Dimitri’s article.
Great. My next product can include an AI controlled flashing led. Not of any engineering use but for marketing purposes ” uses AI” ticks the buzzword compliance box.
Running neural network inference is not computationally intense. The 20 questions game runs a neural network on a small handheld device from 15 years ago. https://en.wikipedia.org/wiki/20Q
Training a network is what takes a lot of data and computation. You wont be doing that very quickly on an arduino.
Next up: NN in TTL with integer math