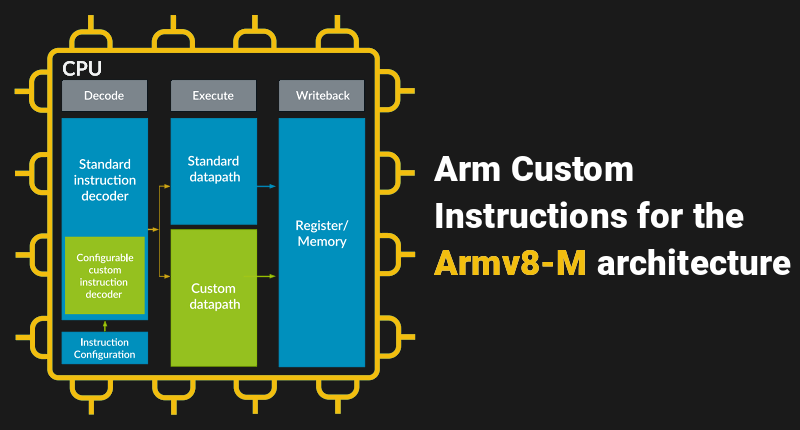
We’re surrounded by ARM processors, which enjoy a commanding foothold in the consumer market, especially with portable electronics. However, Arm Holdings has never focused its business model on manufacturing chips, instead licensing its CPUs to others who make the physical devices. There is a bit of a tightrope to walk, though, because vendors want to differentiate themselves while Arm wants to keep products as similar as possible to allow for portability and reuse of things like libraries and toolchains. So it was a little surprising when Arm announced recently that for the first time, they would allow vendors to develop custom instructions. At least on the Armv8-M architecture.
We imagine designs like RISC-V are encroaching on Arm’s market share and this is a response to that. Although it is big news, it isn’t necessarily as big as you might think since Arm has allowed other means to do similar things via special coprocessor instructions and memory-mapped accelerators. If you are willing to put in some contact information, they have a full white paper available with a pretty sparse example. The example shows a population count function hand-optimized into 12 Arm instructions. Then it shows a single custom instruction that would do the same job. However, they don’t show the implementation nor do they offer any timing data about speed increases.
Population count — determining how many 1s are in a word — is a good example of where this technique might pay off. You have a small piece of data you can process in a couple of cycles. For many other cases, though, the memory-mapped or coprocessor techniques will still be more appropriate. With a coprocessor or accelerator, you can have a separate piece doing something in parallel to the main CPU.
The custom instructions integrate with the normal Arm pipeline. There are only certain instruction formats you can use and your code gets the same interface as the ALU. That means it can process data, but probably can’t easily do anything to manipulate the processor’s execution.
What’s it good for? Typically, a custom instruction will perform some algorithmic step faster than it can be done using normal instructions. However, since you need to have the license for the Arm core, we aren’t likely to see end users adding instructions (please, prove us wrong). But a chip you buy from a manufacturer who make Arm chips could add some instructions like “validate IP address.”
The question is, would you use these instructions in the code you write? Doing so would probably lock your software to a specific processor family. That is, Microchip is unlikely to support ST’s custom instructions and vice versa. That’s good for the vendors, but not so good for developers, or for Arm. That seems to us to be the challenge. New instructions will need to be compelling and fast. A developer won’t likely limit their silicon choices just to do something silly in a single instruction on occasion. The vast majority of the time you’d use a C library and you won’t care how many instructions the operation uses.
To get any traction, vendors will need to find an irresistible need, and a custom instruction cabale of satisfying that need faster than any other ways of doing it. In addition, it needs to be a problem where the timing matters.
Of course, sometimes doing something like a population count can benefit more from a smarter algorithm. Arm, in particular, is very good at doing shifting.














/me adds ‘halt and catch fire’ instrunction
for (int i = 0; i <= 255; i++) {
i = 0;
}
It seems to be in there already, and could be done in almost any computer language.
Dammit, I had the same thought! Something that just simply ties the power rails together in a dead short near some otherwise-critical part of the chip. Call it, er, a “security feature” :P
# HCF
*BANG!* …out comes the magic smoke…
“The question is, would you use these instructions in the code you write?”
You might not, but the silicon vendor might – in ROM support code. A lot of ARM Cortex microcontrollers have at least some code in ROM – I know the Tiva C series has a large amount of driver support code in ROM, and the LPC81x series also has driver support code in ROM.
Obviously you don’t have to worry about portability there and they’re in the perfect position to create those instructions, and speeding up that code or saving space could have significant advantages.
Code to the API instead of the processor.
Yes, just what all RISC architectures have been begging for for decades, lots more complex instructions!
As long as those instructions do not access the main RAM address space and do not introduce new addressing modes, it’s still a RISC.
Double SHA-256 instruction. ;)
7 years ago that might have been useful
ROT26 is more efficient
This is equivalent to a writeable-control-store on microprogrammed CPUs isn’t it? The pdp-11/60 had that, did anyone use it?
I’ve heard rumors that the DECmate folks used the PDP-11/60 WCS to emulate a PDP-8 during development of the software for that platform.
That is true. Regrettably the PDP-8 emulator microcode for the PDP-11/60 was lost when DECmate development ended around 1990.
When I worked for DEC I wrote PDP-11/60 microcode in a project to find out whether the user microcode feature could be used to speed up the Basic Plus bytecode interpreter on the RSTS/E operating system. We found that while there was a small performance gain by having a special instruction to execute the inner dispatch loop of the interpreter it was not really worthwhile unless a very large part of the interpreter was microcoded but the control store and I think other hardware resources weren’t large enough to do that. (That was over 40 years ago and I didn’t keep a copy of the microcode I wrote.)
The only use I know was made of the 11/60 microprogramming capability was to emulate a PDP-8 for development of the WPS and DECmate Word processing software. The project manager for that told me they didn’t keep a copy when DEC stopped developing word processors based on PDP-8 hardware.
However, what ARM seem to be proposing is a way to dispatch a special functional unit in hardware and depending on what the functional unit does the gains could be very substantial.
It’s equivalent in terms of what it can do (ISA wise), but not from a performance perspective.
What ARM (and other vendors are providing) is simply a way to insert your hardware into the CPU pipeline.
A microcode based implementation won’t speed up your instruction too much over regular instructions, if the new instruction requires special processing not supported by your CPU hardware as controlled by the microcode.
Take the popcount instruction for example – a microcode won’t help much here because none of the resources of typical microcode-controlled CPU can help here. The microcode simply switches around buses connected to your existing ALU and register units. These units can’t do popcount efficiently.
OTOH, a dedicated hardware tree of 2,3,4,5,6 bit adders will do 64-bit popcount very efficiently, area and timing wise, and will do so in 1 cycle.
If your application needs this instruction for a significant part of its runtime, or for a timing-critical code section which cannot meet its deadline otherwise, this can be useful.
Second, these instructions will probably not be used by the large MCU vendors, where the MCU needs to be cheap and use minimal chip area. The MCU is also used by many customers and it’s likely there isn’t a specific instruction you would like to add which is useful for a significant number of customers (otherwise it would have been there as part of the standard instruction set in the first place).
It is mostly used by ASIC customers who needs it for their specific CPU cores intended for a specific task.
“We imagine designs like RISC-V are encroaching on Arm’s market share”. You have rather active imaginations. Of greater interest might be the financial problems of the consortium that purchased ARM.
They actually are. I know a lot of low end designs that dropped arm and used risc-v. They run only code stored in mask rom so full fpga testing of the core is possible and the risk is very minimal.
High end applications not (yet?) but the low end is very profitable for arm so it matters.
Any microcoded machine could do this. The problem is the availability of the micro-ops. The problem here is, that for the RISC zombies, this is precisely the opposite to the RISC philosophy, so ARM with stuff like this will enter in a sort of “identity crisis”
This does not oppose RISC in any way. RISC is defined as load/store, reasonably big register file address space. That’s all.
I’d rather have an instruction XYZZY. It’s a very important instruction look it up on wiki.
Nothing happens.
What about (cough, cough) plugh ?
Could it be used to integrate a whole different language, say some commonly used BASIC commands like print, goto, if, input etc?
First, it would still be machine code of some variety. Second, those statements are wildly different in complexity. GOTO is Jump, IF THAN ELSE require multiple operations – first to run the logical test, then to branch depending on the outcome – and PRINT and INPUT are I/O operations that are OS and system dependent. A CPU can’t tell the difference between a TV and a Teletype, after all.
So it’d still need a fair amount of flash space to get some basic BASIC commands working.
I think the best instruction ever was “Translate and Test” on the IBM 360 http://faculty.cs.niu.edu/~byrnes/csci360/notes/360trt.htm
Does anyone here remember the IBM XT/370 ? It was an IBM XT with several adapter cards installed, one of which was a Motorola 68000 CPU with custom microcode that emulated the IBM 370 CPU.
Also I think that the DEC PDP-8 had instructions that allowed you to code your own instructions as well.
Why does it seem that everything old gets new again? Are Hollywood and Silicon Valley that close these days?
It’s not a microcode though this time around. Extended instructions can (and should) be implemented in hardware.
Extended inatructions is the best way to implement low latency compute accelerators. Memory mapped approach is limited, while with extended instructions acceleration can be seamlessly integrated into your pipeline, no need to tranafer to / from your registers. And it can be easily integrated into a compiler too.
I experimented quite a bit with an idea of inlining Verilog into C for infering extended instructions transparently, and it seems to be a very versatile base for hardware-software co-design, allowing to construct more complex (e.g., HLS) systems on top. See an example here: https://github.com/combinatorylogic/soc
You don’t need to know about the instructions. Unless you’re doing bare metal assembly, it’s the compiler that decides which instructions to execute. If a vendor can supply a custom arm chop that works with all standard tools, and works better with their toolchain, how is that bad?
Sounds risky to me