
I will be the first to admit it. This is almost not — at least not specifically — a Linux article. The subject? An automation tool for Chrome or Firefox. But before you hit the back button, hear me out. Sure, this Chrome plugin started out as a tool to automatically test web pages and automate repetitive tasks in the browser. However, it can extend that power to all programs on your computer. So, in theory, you can use it to graphically build macros that can interact with desktop applications in surprisingly sophisticated ways. In theory, anyway; there are a few problems.
The program has a few different names. Most documentation says UI Vision RPA, although there are some references to Kantu, which appears to be an older name. RPA is an acronym for Robotic Process Automation, which is an industry buzz word.
Let’s take it for a spin and see what it’s all about.
Going a Step Beyond Macro Recording
I tested it with Chrome, it works very well on both Windows and Linux (and, presumably MacOS, but I didn’t test that). The desktop mode, however, took a bit of finagling. I eventually worked out the problems — sort of — and they may or may not be dealbreakers, depending on your setup.
UI Vision RPA is quite clever. If you are just automating a web page, you can record a macro. When you interact with the browser during recording, the program can see what you are doing by monitoring the domain object model (DOM) in the browser. Then it is able to find the same things and repeat your actions during playback.
There are many ways it can identify elements including by CSS identifiers, pattern matching, and — sometimes, using optical character recognition (OCR). That’s one of the more exciting things, is the coupling to OCR. For example, a script can find a stock symbol on a web page and then use OCR to read the price that is right next to it as text characters, not just an image.
You Literally Show It Pictures of the Menu Commands
To control all the GUI programs on your computer you need to download and install some extensions to the software. Once you do, you can go to settings and turn on desktop mode. The gotcha is that recording doesn’t work in desktop mode — you’ll have to set up scripts in a more manual way. You can use commands like XClick, XMove, and XType. The target selection mechanism now is very different and — if it works — really clever.
 The script GUI uses modules like this, one per command. There is a space on each command for an image you want to match. Next to that box are two buttons: Select and Find. When you press Select, the program gives you three seconds and then takes a screenshot of your entire desktop. This pops up in a simple image editor where you draw a box around what you want to find. The three second delay lets you pull-down menus or do any other set up required. You can set up your own images without using the Select button, but you have to figure out the location to put the pictures and the file naming convention, so that’s not very handy.
The script GUI uses modules like this, one per command. There is a space on each command for an image you want to match. Next to that box are two buttons: Select and Find. When you press Select, the program gives you three seconds and then takes a screenshot of your entire desktop. This pops up in a simple image editor where you draw a box around what you want to find. The three second delay lets you pull-down menus or do any other set up required. You can set up your own images without using the Select button, but you have to figure out the location to put the pictures and the file naming convention, so that’s not very handy.
When the macro executes or when you hit the Find button, the system takes another screenshot. This time it tries to match the image you provided in the command and then does the move, the click, or types the characters. There’s a confidence number you can use to relax how close the image has to be to the search image. By default this is 80% but you can change it globally in settings or by adding a suffix to individual file names (like ffis9y_dpi_120.png@0.5 for 50% confidence).
When this works, it works well. There’s also a command to do things relative to the search image. In other words, you can find an icon and then click the button next to it, for example. In addition to creating various mouse clicks and movement, the program can also simulate keystrokes. You can see the project’s video about desktop automation, below.
An Example: Resizing Images in Gimp
One of the things I do a lot is resizing images to fit the 800 pixel width for Hackaday articles. So I decided to see if the automation could make a macro that would do that with Gimp. Indeed it can, subject to some issues I’ll describe in a bit.
You can look at the script in two ways. The graphical version looks like this:
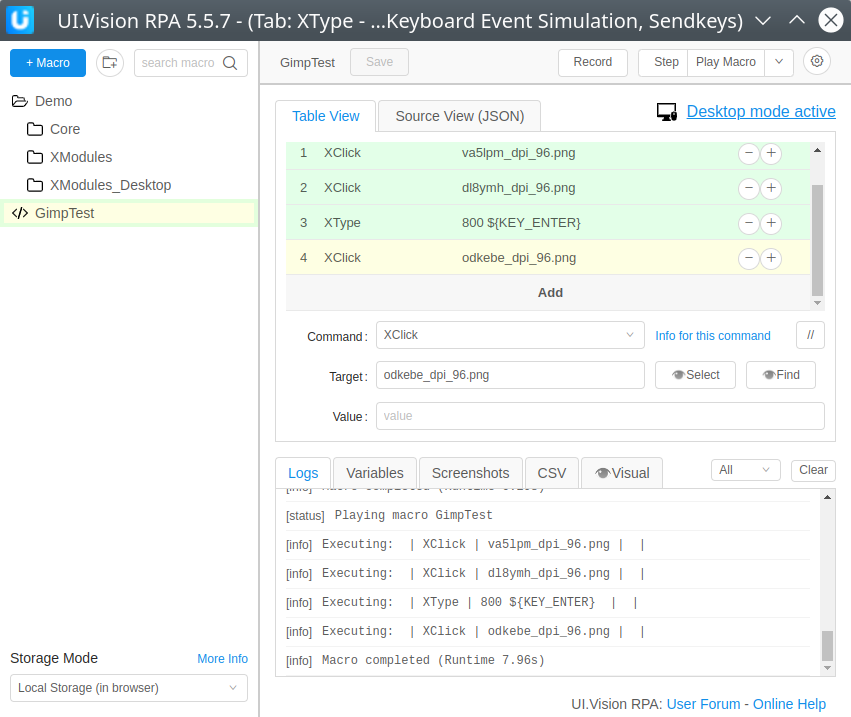
If you hover over the cryptic file names while using the program, you’d see the first image is that of the Gimp Image menu. The second is the menu entry that says “Scale Image” and the image on line 4 is a picture of the Scale button.
Here are the images in the order they appear in the script:

You can also look at the code as JSON:
{
"Name": "GimpTest",
"CreationDate": "2020-5-20",
"Commands": [
{
"Command": "XClick",
"Target": "va5lpm_dpi_96.png",
"Value": ""
},
{
"Command": "XClick",
"Target": "dl8ymh_dpi_96.png",
"Value": ""
},
{
"Command": "XType",
"Target": "800 ${KEY_ENTER} ",
"Value": ""
},
{
"Command": "XClick",
"Target": "odkebe_dpi_96.png",
"Value": ""
}
]
}
What Doesn’t Work and Some Workarounds
The program has a few serious problems. First, if you have multiple monitors, it won’t work. The authors are aware of the problem, so they may have a fix in the works, I’m not sure. However, a more serious problem is that it didn’t seem to work at all on two of my Linux computers running KDE Neon. After a little interaction with the developers, they decided that on some versions of Ubuntu, the screenshot Select function doesn’t work and suggested I manually take screenshots. However, that part does work on both of my setups. What doesn’t work is the pattern matching it does to do for macro playback or the Find button.
At first, I was stumped. Once I learned it wouldn’t work with multiple monitors, I had it working on Windows, so I knew I was using the program correctly. But on my Linux boxes, nothing was working. I finally figured out something. My Surface Book and a very large monitor on my desktop machine are both scaled. That seems to be what prevents the program from working properly. Setting the scaling to 100% made it work as expected.
So if you have a single monitor and you don’t use scaling, this could work. But I am hopeful that continued development will widen what is supported. For now there are a lot of rough edges, probably because desktop automation isn’t the project’s primary goal. A few things I found:
- The Linux installer for the desktop add ons, 1install.sh, uses Bash syntax but has /bin/sh at the interpreter. Some Linux distributions map /bin/sh to Bash, but many do not. Since the file doesn’t have execute permission anyway, you can just source it to Bash and it will work.
- The install file copies native messaging files to your browser directories. However, it doesn’t know about Google’s beta copies of Chrome. I had to manually copy
~/.config/google-chrome/NativeMessagingHosts(a directory) over to~/.config/google-chrome-beta. - The process of creating images without using the Select tool is not very pleasant. It appears the files have to be in the correct directory and follow the naming convention of the files the tool produces for you.
- The find function doesn’t appear to work unless the macro you are working on is selected in the left-hand pane (which isn’t always the case). Sometimes it appears the button does nothing and you have to remember to select the macro.
There is one other limitation, although it isn’t a bug. The OCR features — which you do not have to use — depend on remote servers. Not only will some people object to shipping their desktop screenshots to an unknown server, but there is a limit of 100 conversions a day. There is also a limit on the number of mouse clicks and characters you can have in a single macro in the free version. There is a way to pay to get more, and I can’t blame them, at least for the server-side OCR. Running a compute-intensive server isn’t free. However, you don’t have to use OCR, so this may or may not be a problem for you, depending on what you want to do.
The Promise
On the plus side, the system appears to be very versatile. You can call out to programming or scripting languages if you don’t like their GUI scripting. It is very appealing to have a single tool to script on any of the major platforms. It seems like if the program worked with multiple monitors and worked on common setups (for example, scaled multiple monitors), it would be a big winner. As it is, I am thinking it is something to watch to see if it improves. That is unless you only use a single unscaled screen. Then it seems to work just great.
If you want to just automate your browser, though, that seems to work with few problems. I had about 4,000 spam entries on a site that would only let me delete 30 of them at a time. That’s how I discovered UI Vision RPA. I needed a way to click the delete buttons over and over again and it did the job with very few problems.
Do you have a goto automation tool? We’ve talked about automating X11 before, but those techniques don’t help you on other platforms. They also don’t do image and text matching. Of course, you can always automate with hardware.














I’ve used PyAutoGUI (https://pypi.org/project/PyAutoGUI/) and OpenCV for similar automation tasks before. That approach is a bit brittle in the age of weekly website updates that might move a button around. In that case, selenium is a better tool.
Slightly OT: you can resize images from the command line with “mogrify -resize 800×800 image1 image2 . . . imageN”. mogrify is one program in the ImageMagick package, which is available for multiple platforms.
..or just `mogrify -resize 800 …` and it will scale to a width of 800 pels while maintaining aspect ratio.
“Do you have a goto automation tool?”
visgrep in xautomation
xdotool
Also working on a similar hobby project when I get free time, but cleaning up the existing GPL lib resources is slow. First step was making sure the core features are viable. Maybe December sometime for this utility if anyone is interested in helping test things… or someone gets around to it before we do… our build is only intended for *nix platforms. ;)
The UI OCR is a pretty slick feature, I may add it to the todo list as well.
I’ve used [SikuliX](http://sikulix.com/quickstart/) for this kind of automation. You basically write a Jython script that drives your application. It has a built in library for finding images on the screen (e.g., a button, text box, label, etc.) and offsets from them. For example, I used it to find a “net cost” label on an invoice then copy the price next to it. The script then makes some actions based on the value. The script has a loop that runs until the on screen count of item to process reaches 0.
Came here to say this! The SikuliX UI for capturing screenshots of target regions is great, and the fact that you can write your script in [J|P]ython gives you a lot of flexibility to tie in external data sources for business automation.
I recently found https://github.com/automagica/automatica which seems to be quite promising.
https://github.com/automagica/automagica
I was using Kantu and Selenium IDE at work a bit over a year ago to help generate Selenium/Python test automation scripts for web and mobile apps. This article reminded me that Kantu had the image matching stuff.
But I had no idea that this could also be used to automate any desktop app! uh, doesn’t this open the door to some tremendous exploits, or at least some killer pranks?
Commercial tools that are good. UIPath, Automation Anywhere, my favourite is Tocabot as its cloud. Opensource, pywinauto, beautifulsoup, selenium, puppeteer
So what does this offer over https://robotframework.org/ ?