[Benjojo] got interested in where the magic number of 1,500 bytes came from, and shared some background on just how and why it seems to have come to be. In a nutshell, the maximum transmission unit (MTU) limits the maximum amount of data that can be transmitted in a single network-layer transaction, but 1,500 is kind of a strange number in binary. For the average Internet user, this under the hood stuff doesn’t really affect one’s ability to send data, but it has an impact from a network management point of view. Just where did this number come from, and why does it matter?
[Benjojo] looks at a year’s worth of data from a major Internet traffic exchange and shows, with the help of several graphs, that being stuck with a 1,500 byte MTU upper limit has real impact on modern network efficiency and bandwidth usage, because bandwidth spent on packet headers adds up rapidly when roughly 20% of all packets are topping out the 1,500 byte limit. Naturally, solutions exist to improve this situation, but elegant and effective solutions to the Internet’s legacy problems tend to require instant buy-in and cooperation from everyone at once, meaning they end up going in the general direction of nowhere.
So where did 1,500 bytes come from? It appears that it is a legacy value originally derived from a combination of hardware limits and a need to choose a value that would play well on shared network segments, without causing too much transmission latency when busy and not bringing too much header overhead. But the picture is not entirely complete, and [Benjojo] asks that if you have any additional knowledge or insight about the 1,500 bytes decision, please share it because manuals, mailing list archives, and other context from that time is either disappearing fast or already entirely gone.
Knowledge fading from record and memory is absolutely a thing that happens, but occasionally things get saved instead of vanishing into the shadows. That’s how we got IGNITION! An Informal History of Liquid Rocket Propellants, which contains knowledge and history that would otherwise have simply disappeared.













I would try and make contact Vint Cerf or Bob Kahn, they may not know the answer, but they would definitely have more insight than most. And could probably point you in the direction of someone for a more definitive answer.
Or it came from 80/20% header rule
That wouldn’t make a lot of sense. For that to be the case, an ethernet header would have to be as much as 300 octets. Ethernet headers are only 18 octets.
Remember, the Ethernet Specification was independent of the header lengths in any higher layer protocols (e.g. AppleTalk, Banyan, DECNET, IPv4, IPv6, IPX, etc.).
I vote for 80/20. You don’t want too large packets, it increases the cost of retransmissions.
I would suggest reaching out instead to Bob Metcalfe. To the best of my knowledge, Cerf and Kahn were involved in the development of Internet Protocol and the Internet, but not the L2 definitions of Ethernet.
Also, one could review the original IEEE 802.1/802.2/802.3 proceedings. and probably get a fairly good idea.
Bob Metcalfe was one of the principle investigators/developers of the original Ethernet specifications.
Second that. I once knew some of that information, but it’s lost in the cobwebs now. My memory is that the packet length is strongly tied to network efficiency and fairness. There’s a compromise between packet length (Ideally, you would transmit your entire message in one packet) and network availability (a shorter packet means the next user gets access to the network earlier). So you are trying to maximise both throughput and network utilisation, while minimizing wait time and overhead (collisions, interframe gap and header time). 1500 is probably the value that works best (for 10 mbits//s…see below)
I’d start by reading Metcalfe and Boggs’ first paper on 3 megabit Ethernet: https://www.cl.cam.ac.uk/teaching/1920/CompNet/files/p395-metcalfe.pdf
For a 3Mbit Ethernet, the MTU turns out to be 4000 bits. The calculation is on page 402.
I’ll note that 4kbits is equal to 500 octets which is 1/3 of 1500 which 3mbps is a little less than 1/3rd of 10mbps, so that maps well.
OTOH, it means that leaving the MTU at 1500 octets as ethernet scaled from 10Mbps to 100Mbps to 1,000Mbps (Gigabit), then 10Gbps and now even 100Gbps was, well, perhaps a bit silly.
In fact all the backbone providers networks now transport jumbo frames, with 100/400G ports set to typically 9200 between P/PE routers. vSo they can carry Mpls payloads of also jumbo frame size.
Correct, its about setting mtu appropriateky for the bandwidths available. indeed whilst routers can oerform ip-fragmebtation, not all do. so theres still some risk when going over 1500 with headers
There is the Jumbo Frame option for internal networks: https://en.m.wikipedia.org/wiki/Jumbo_frame
Second that. And I’m sure Bob Metcalfe will help. I reached out to him once to get his blessing to use the photo of the original Ethernet sketch (the one used in the illustration to this page) in my book. He agreed right away and we had a nice chat on top of that.
From Metcalfe and Boggs (referring to 3Mbit/s Ethernet):
“We limit in software the maximum length of our packets to be near 4000 bits to keep the latency of network access down and to permit efficient use of station packet buffer storage. For packets whose size is above 4000 bits, the efficiency of our experimental Ethernet stays well above 95 percent. For packets with a size approximating that of a slot, Ethernet efficiency approaches 1/e, the asymptotic efficiency of a slotted Aloha network [27].”
If you work that out, 4000 bits is 500 bytes, so for a 10Mbit/s network, the max packet size is just about 3 times that or 1500 bytes. The reasoning and math is in the paper at the link I posted above. Well worth the read and a bit of playing on Excel/Libre Calc
The “slotted ALOHA network” mentioned by Metcalfe is pretty interesting by itself. ALOHAnet was a packet radio network developed by the University of Hawaii in the ’70s that was a direct ancestor to both CSMA/CD Ethernet and WiFi. https://en.wikipedia.org/wiki/ALOHAnet
I believe the raw MTU is 1536 including ethernet header. 1536 ist somewhat binary (1024+512)
Yes, that’s correct… On-wire MTU is 1536, including (IIRC, arguably obsolete) preamble and Ethernet framing/header/etc.
A long time ago i remember reading some (paper) article about this. Dont remember the exact details. The article was from one of the inventors: Metcalf or Metcalfe.
1500 Bytes is from Ethernet.
The 1500 Bytes were a compromise.
– Fast memory (for buffers) was relatively expensive.
– the CSMA/CD access method dictated limits: If a larger size is used, the medium would be occupied too long, so the total number of allowed stations on the network would have to be limited. (Bridges/Switches did not exist then).
(- there is also a minimum size on Ethernet: 64 Bytes. It is a limit from the physical size an Ethernet network is allowed to have. If this size is reduced, the total physical ethernet network span would have to be reduced. Otherwise Collisions could not be detected reliably.).
All these parameters of the original Ethernet were the result of simulations. There probably are some old PHD thesis about this.
All newer Ethernet technologies (10BaseT to 100GBase..) always maximized compatibility. So 1500 Bytes is still used today.
If I remember correctly, it has to do with the hardware clock rates and/or buffer size on early interfaces. There’s a limit to how many packets the L1 hardware can process, divide the link speed by that number and voila, there’s the most efficient packet size. It was set very early on and as hardware has much longer life cycles back then, it just lingered on and continued to be supported until it would be WAY too hard to change it globally.
Why do my comments vanish?
Because you said something mean, crazy, or political. Or replied to a comment that was one of the above, and the child comment got deleted with the parent.
Or because it got reported often enough that it was sent back to moderation, in which case if it’s fine, we’ll just re-approve it.
https://hackaday.com/policies/
Perhaps due to the confluence of your username and not-well-adjusted input handling?
Nah. We’re ok with that. (Knock on wood…)
I’m fairly certain from my 1980’s ethernet training that it was a factor of the number of bits that could fit on the standard ethernet cable combined with the minimum and maximum times that if would take to sense a collision.
CSMA/CD is the key here isn’t it? the “magic” number was all about the best chance of detecting carrier and collisions to achieve maximum throughput.
Exactly so. If I’d read this first I’d not have made my post.
No, that I do remember.
The length of the preamble and the inter-packet[frame] gap IFG, are related to the maximum segment length, because:
1. You want collisions to occur in the preamble if at all possible (preamble length)
2. You want the station at the opposite end of the segment to have an opportunity to see the medium is idle before anyone can transmit. (IFG)
Not exactly. CSMA/CD collision detection combined with the 100meter length limit is what dictated the size of the preamble, but not what dictated the 1500 octet MTU. The MTU was chosen based on the compromises around number of stations and high likelihood of transmit success on first try without tying up the wire too long.
My guess would be it comes from early Ethernet hardware – 2K RAM for packet+workspace, Maybe also data recovery/synchronisation time constraints.
That sounds correct, just looking at the data link: “The EtherType field is two octets long and it can be used for two different purposes. Values of 1500 and below mean that it is used to indicate the size of the payload in octets, while values of 1536 and above indicate that it is used as an EtherType, to indicate which protocol is encapsulated in the payload of the frame. When used as EtherType, the length of the frame is determined by the location of the interpacket gap and valid frame check sequence (FCS).”
So if you’re running the larger frame size/MTU you’d need to hold off for the gap. If there was a collision or data error on the segment, the gap might get trashed, leading to a buffer overrun and all sorts of nasties (maybe crashing workstations etc as back in the day the s/w wasn’t that robust). So – best to keep it to 1500 or less for robustness.
MTUs came from the ARPANET IMP processor
https://en.wikipedia.org/wiki/Interface_Message_Processor
The 1500 is the maximum Ethernet packet size and it is that way due the original CDMA nature of Ethernet.
https://en.wikipedia.org/wiki/Ethernet_frame
I believe it was first specified in IEEE 802.3, but it might have been defined in DIX 1 or 2.
https://en.wikipedia.org/wiki/Carrier-sense_multiple_access_with_collision_detection
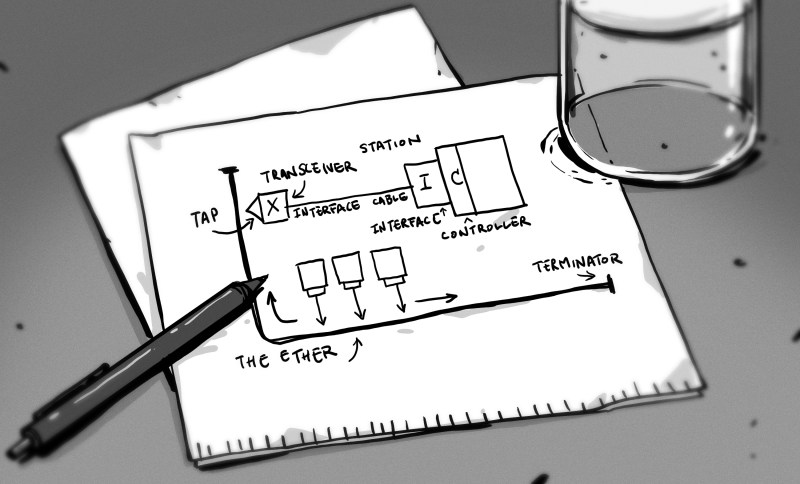
You also need to know about MAUs (Ethernet transceivers).
https://en.wikipedia.org/wiki/Medium_Attachment_Unit
Aah yes. The vampire tap. You would core into a foil jacketed half-in-diameter stiff cable to reveal a bare naket center conductor which you would then poke into with the MAU – a vampire tooth with insulation.
https://networkengineering.stackexchange.com/questions/2962/why-was-the-mtu-size-for-ethernet-frames-calculated-as-1500-bytes
It appears to be a function of two things.
1) the anti-babble feature of the MAU
2) The change in definition of the Ethertype from DIX to 802.3
Plus you don’t want a single node hogging the wire too long.
I thought the anti-babble timeout was a calculated value but it is appears to be arbitrary. So it seems that the primary reason for the 1500 MTU is for fairness allowing other nodes attempts to gain access once every 1.5ms. In the other direction the minimum packet size is a calculated value.
…and then the AUI cable would rip itself off the transceiver because the damn slide latch didn’t retain it worth beans.
Look up CDMA/CS and Ethernet transceivers. I believe it was first specified in IEEE 802.3 or maybe DIX 1/2. It is a function of the math for CDMA/CS.
s/CS/CD/ – CSMA/CD, or Carrier Sense Multiple Access/Carrier Detect.
I’d guess memory size plus likely a balance of latency. Transmission lines were really slow then and if you want ‘quick’ turnaround then the packets have to be small.
:) Several technical parameters today are tied to past architectural decisions.
From HD limits, file systems, SQLs, network parameters.
You cannot build something without being elastic in architecture.
If something in your architecture can lead to limits, look for alternatives, or at some point a break in compatibility will be required.
1500 limit is just one among many others, look at x86/PC the size of the limitations that we follow until today.
MAP might have mentioned something about it in “The Elements of Networking Style” but it has been a while since I read it.
Actual limit is 1536 octets (bytes). A consequence of the media (copper) access method used by Ethernet. The reason is that this was needed to meet limits on back-off time for CSMA-CD, the transmission method used to manage segment ownership. If it was longer than 1536, at 10mb/second (original speed), effective use of the copper was poor with all those that had attempted to transmit stepping on the packet forcing the first user to retransmit, with a specified max nodes per segment, any one of which might begin to transmit a packet, it was a compromise to meet the spec that statistically, Ethernet, and by extension CSMA, could provide a certain bandwidth without requiring tokens, or a management layer with a central node. Remember, it wasn’t the only network out there. It was a compromise at 10Mb/s.
It was the only GOOD network out there. :-)
It’s a bit sad that so much back ground and context is being lost in this digital age. It almost feels as if books have a place in condensing this kind of information in a way thst newsgroups and emails do not have lasting impact.
It’s been a few fortnights but I’ll take a stab at this one. Totally cannot produce any documentation of substance.
Three decades ago I worked for a Token Ring (802.5) firm. Not IBM but one that OEM’d Token Ring h/w to IBM. We were working on implementing big frames (16K? not sure, many tequilas ago) and discovered the obvious – a frame has a physical length when it’s on a wire. If the frame is physically longer than the wire it’s transmitted on the hardware must start processing the frame before the entire frame is received by the hardware. The alternative is storing the entire frame before processing, which slows transmit rates. It seems counter-intuitive – but bigger frames can result in slower throughput. A lot of networks don’t physically have enough wire length to support big frames.
…and that’s why small “frame”/cell tech like ATM and SONET/SDH often carry our data today – even if “Ethernet” is layered on top of it. We often share our networks today so smaller “transactions” can result in increased perception of speed – not necessarily throughput but sometimes that’s faster too.
Fun note – we had a Fluke meter back in the day. It would tell us the electrical length of the network and we would calculate the MTU from that to make sure the frame would fit on the customer network.
I also designed Token Ring boards…something I never want to do again. 4Mbit TR might have worked well, but when they tried to go to UTP and then 16Mbit TR, well…the warts started to reveal themselves.
Getting a UTP-16M TR switch through radiated emissions testing was an exercise in frustration. All the more so, when 100BASE-T was coming out at the same time. You knew it was futile, but you still had to do it. Luckily, I was able to join the Ethernet side of the business, which was much more fun.
Much later, at a different company, I was called upon to make an “in-house” fiber-based token passing network…work. The designer had left, his MAC was implemented inside a Xilinx chip with minimal comments, and the process of electing a master to initiate the token wasn’t working. Loads of fun…not…but I got it working after hacking a bit. So no matter where you are, your work on TR can come back to bite you!
As I recall, from building metro Token Ring networks for banks, the much feted “wrap” capability of Token Ring that allowed it to “heal” was actually a function of the connectors which would mechanically switch, when unplugged, to create the wrapped network.
If a cable actually broke, then the whole network would go down.
With UTP, they had to emulate that in software because RJ45 don’t have that feature and, in my experience, it didn’t work very well. When we first started building these networks for banks, we would often get a call saying “our network is down” because someone in the bank had unplugged part of the ring expecting it to wrap and, for some reason, it hadn’t. Or one of their cables had gone faulty, breaking the ring. And, of course, when their whole network went down, that was our fault.
Exactly. Those clunky Type I connectors were a royal PITA, even more so than the Ethernet AUI “slide latch”, which was totally ineffective against plenum insulated AUI cables. I can’t imagine their “self shorting” ability was all that reliable…nobody liked them or the inflexible cables. And, of course, the hubs were huge. The only solution was to use switches, and get away from shared media (to be fair, this was just as much of a problem with Ethernet!). But a TR MAC/PHY was 3x the cost of an Ethernet MAC/PHY, and once 100BASE-T came out, 16Meg TR just couldn’t compete, except on “low latency” and “guaranteed delivery”.
The problem with UTP TR was that, while the Ethernet UTP waveform was tailored to minimize radiated emissions, doing that with TR induced intolerable amounts of jitter…so they couldn’t do it, and it radiated like a banshee.
I designed Data General’s TR interface card for their AViiON workstations, because the contract specified a TR interface. Marketing said that if I couldn’t build it cheap, they’d go outside and buy an OEM card. So I used a bunch of GALs and massaged the Motorola bus interface on the (TI TMS380C16, IIRC) TR chip to be a VME bus interface and we had the world’s cheapest TR card!
(shortly thereafter, Motorola discontinued the 88K processor on which AViiON was based, and that was the end of THAT adventure!)
I love the idea that data has a physical length ” a frame has a physical length when it’s on a wire”. Out of interest (because my maths is terrible), what would be the calculation to determine, say, the length of a 400 bit message sent over Ethernet?
– Still comes into play today – FC storage switches negotiate buffer credits – essentially how much a sender can blast away into a wire before taking a break to confirm – since at 32Gbps you can pump a lot of data into a physical fiber before it hits the other end (LW, KM’s away) – and the less ack’s you need to wait for the better – but you also don’t want to overrun the buffer at the receiver and create retransmits or other issues. The more memory the receiver has available, the more credits can be given to a client/connection – and I believe LW connections receive more credits than SW connections, so they can queue more data up on the wire / less ACK round trips.
It’s because Ethernet has become the default transport for most of the Internet.
See https://datatracker.ietf.org/doc/html/rfc894
Originally Ethernet was a fat coaxial cable bus that stations connected to. When the station needed to send data it had to wait until any other transmissions had finished and then attempt to transmit. If two stations tried to transmit at the same time, you got a “collision” and both stations had to abandon their transmit and try again after a random time. If the maximum packet size was too large then that would block other stations from using the network. 1500 was, fairly arbitrarily, chosen as a good size to support most data types at the time, whilst not causing too many delays for other stations on the bus.
Additionally, the transceivers had a safety feature built in to stop faults in a station from blocking the whole network. This was known as “anti-babble”: if a station transmission was longer than around 1.25 ms, then the transceiver would assume it was faulty and isolate it from the network.
See: http://www.pennington.net/archives/ethernet/Ethernet_Version_2.pdf
Since the days of 10BaseT and LAN switching technology, everyone gets their own network segment and the smaller MTU isn’t useful. Hence most devices support “jumbo frames” which, typically, go up to 9000 bytes. But the legacy of Ethernet’s origins prevail and most switches and LAN NICs default to 1500 to ensure compatibility with other devices.
That is the DIX 2.0 specification but I don’t see the math in it for how 1518 was calculated. If people keep digging there is a formula about the timing of packets on the original thick coax Ethernet segments. Once you find that formula it will tell you the maximum time the packet can last and from that you can figure out the maximum packet length. This is all rooted in the design of CSMA-CD protocol. 1500 seems arbitrary now that CSMA-CD is no longer in use.
BTW, before 1500 it was 576 bytes on the packet switched networks based on telephone lines.
Here’s the v1 spec. It contains a lot of the same text, and doesn’t describe much about the packet timing that I could see:
http://www.pennington.net/archives/ethernet/Ethernet_Version_1.pdf
I spent a lot of time trying to run this down without success. At this point, we would probably be better off creating a new protocol which is just Ethernet but with a much larger MTU default and a protocol for negotiating MTU’s with upstream switches. Possibly we could co-opt an ethertype to flag an upgrade.
If you trace it back far enough, it ends up being the number of octets you can fit between the width of two horses’ rear ends.
In short whomever invents and introduces a technology tends to get stuck with the original while others come up with better versions. (see NTSC TV vs PAL) In the case of network technology that 1500 bytes became so widespread before hardware and protocols were developed to easily handle larger packets.
So the world is stuck with it until something comes along that can handle larger packets AND seamlessly “downshift” to 1500. To make that easiest, a larger packet size should be a multiple of what’s current so software and hardware can “thunk” between different sizes by buffering x small packets to assemble one large packet or hold one large packet and chunk it into small packets to send out sequentially.
It just needs to be done, like getting rid of all the early 7 bit hardware on the internet that trashed binary data and non-English text passing through by setting the least significant bit to zero, because in the base ASCII character set that bit is always zero.
7 bit routers are why BinHex exists. Unlike MacBinary, BinHex uses only 7 bit characters. I remember when Macintosh software sites had downloads in Stuffit, MacBinary, and BinHex, often with small test files to download and extract to see if something in the route between them and you mangled it. If you were on slow dialup, especially with a metered connection, you really wanted to be able to download Stuffit or MacBinary.
s/least significant bit/most significant bit/
Sorry, but
CSMA/CD: Carrier Sense Multiple Access w/ Collision Detection
The 1500 byte limit may come from memory limitations of early store and forward packet switches, since they would store entire packets in memory before retransmitting them. If they didn’t exist at the time that number was declared, then it could have been related to limiting the memory that needed to be embedded in network adapters.
No, it was the original frame size on the original shared-media Ethernet chosen, largely, to give all stations a reasonable chance of being able to transmit. It predated store and forward LAN switches by about 20 years.
Experimenter might have been thinking of x.25 packet switches, which would have been used for WANs, but they had a max packet size of 1024 Bytes.
MTU issue gets more complicated when tunnel is involved. The devices on both end of the tunnel has no idea there is a tunnel yet the tunnel still limited by the MTU. So everything has to be scaled down or be fragmented. it is a mess.
Back in the day, I was chairperson for organizing bi-monthly meetings of Ohio’s higher education network OARnet. It was about 1997 that higher performance connectivity with the moniker Internet2 was the Vogue. The Ohio Supercomputer Center was one of the entities involved in Internet2 research. We brought in an expert from the OSC to talk about internetworking performance. Packet length was discussed. Of course there are many competing variables. OSC research had shown that under average conditions of packet loss, segment length, application behavior, etc. that 1500 octets is a good default compromise. As it was, Bob Metcalfe and friends had made a pretty good choice. It is kind of like the fact 50 Ohm coaxial cable isn’t magic number, but it is a real world compromise between several competing factors.
I later worked for a business and we experimented with jumbo packets on our gigabit LAN when writing backups. The real world performance gain was only a few percent, so we decided to stick with 1500 octet packet length to keep life simple.
I still find myself on occasion going to Bill Stalling’s classic three volume set of networking books from the 1980s.
I think Bob Metcalfe was once asked what he would change if he had to reinvent Ethernet and he replied something on the lines of: ‘make the maximum packet size larger and fix the damn latch.’
Ethernet maximum frame sizes vary with the governing standards (e.g., the various 802.11 standards), but mostly, they’re around 1536 bytes (IP packets are 1500 bytes because Ethernet uses some bytes from the frame for its own addressing).
So, why 1536 bytes on the original Ethernet?
The very original Ethernet ran at 3 megabits. Why 3Mb? Because that was slower than the data path in the Alto computer, for which Ethernet was invented. This meant that the original Ethernet interfaces did not have to buffer data as it arrived, they could just write the bits into the computer’s memory (memory was very expensive then).
An Ethernet frame of 1536 bytes is 12288 bits, which takes 4096 (2^12) microseconds to transmit at 3Mb/s.
…And, at a 3Mb rate, a bit is about 300 feet long on the cable.
…And Ethernet works by listening to see if the cable is idle before you try to transmit a frame, so you want all your Ethernet interfaces to be within a light-bit of one another. Which is okay! This is a Local Area Network built for an office.