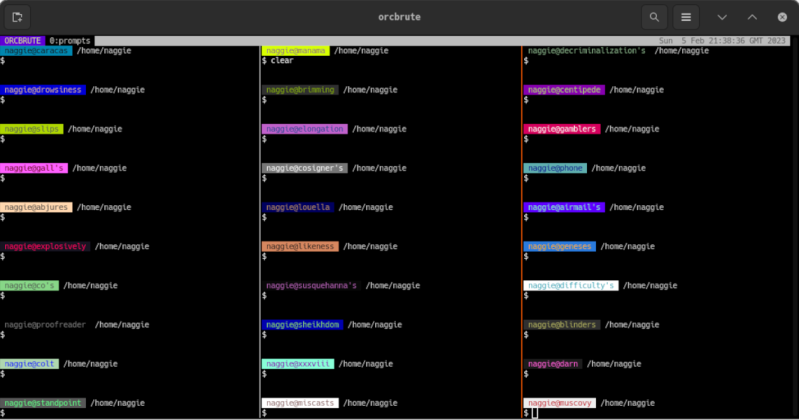
Maintaining or administering a computer system remotely is a common enough task these days, but it’s also something that can go sideways on you quickly if you aren’t careful. How many of us are guilty of executing a command, having it fail, and only then realizing that we weren’t connected to the correct computer at all? [Callan] occasionally has this issue as well, but in at least one instance, he deleted all of the contents of the wrong server by mistake. To avoid that mistake again, he uses color codes in the command line in a fairly unique way.
The solution at first seems straightforward enough. Since the terminal he’s using allows for different colors to be displayed for the user and hostname on the bash prompt, different text and background colors are used for each server. The only problem with this is that his friends also have access to these servers, and one of them is red/green colorblind, which led to another near-catastrophic mix-up. To ensure no edge cases are missed, [Callan] built a script which runs on every new server he spins up which selects two random colors, checks that they contrast well with each other, don’t create problems for the colorblind, and then applies them to the bash prompt.
For a problem most of us have had at some point or another, it’s a fairly elegant solution that helps ensure we’re sending the right commands to the right computer. This adds a layer of automation to the process and, while some color combinations do look similar, there are enough to help out most of us in some way, especially since he has released the source code on his GitHub page. For other helpful server administration tips, we’d recommend the Linux-Fu article about deploying your own dynamic DNS.














It is a good suggestion, but the problem is that you get used to anything after a while, even color. I have my name and machine in my shell prompt (joe@clamdigger>), so if I take the time to look I can always see what host a given terminal window is on. But I usually have a dozen or so terminal windows in different linux desktops. I have accidentally rebooted the wrong system a time or two, which is no big deal really.
What I watch out for is when I am writing to removable media. Do a “dd if=disk.img of=/dev/sdc1 and write to a system disk instead of the SD card in the card reader and you will be really upset. Too bad the devices are all /dev/sd.. — let me know if you have a safeguard for this other than eternal vigilance.
If you´re always using the same removable medium, it´s easy to set an udev rule that match this particular device and symlinks (or even rename) it to /dev/whatyouwant
Or even more globally match any USB attached mass storage, for example /dev/sdxn becomes /dev/extUSBxn if you want to.
Excellent idea, this would accomplish what I wish was the default. As for the next suggestion, I typically do just that in a makefile (since inevitably I end up having to do a bunch of experimentation that requires writing images to an SD card over and over.
Thanks
Make yourself a temporary alias for the SD card, test it, then use that so you can’t accidentally get the wrong device. e.g.
MY_SD=/dev/sdc1
ls $MY_SD
dd if=disk.img of=$MY_SD
In this example “ls” is not really a good test, but I’m on Mac so I’m not sure if “diskutil info $MY_SD” would work for you, but sub in any command that you feel gives the confidence that MY_SD points in the right direction.
I like to use lsblk which defaults to outputting a tree of devices and then extra columns including the mount point. Then double check that the device I want to dd to is NOT mounted as anything I care about. Maybe this is just extra vigilance but it’s an easy extra step.
I used to just run the mount command with no arguments, but mount output gets so full of crap these days with cgroups and tmpfs and sysfs and snaps and whatever else I don’t care about, that lsblk just gets to the point better.
The solution is to use a read-only OS (ex: tinycorelinux) and have regular backups of the writeable overlay layer (a layer which contains writeable overrides of files such as /etc/passwd). People shouldn’t be fudging around on Linux servers through manual commands anymore. We’re way past the good ol’ days of anyone needing to ‘sudo’ anything on a server.
That´s a very narrow-minded MS Win way of thinking.
Manual commands are still the most efficient and lean way to do the job, and won´t go away anytime soon. Not everybody wishes a clutter of GUI running on production server. Not even talking about embedded system (yes, those can be servers too).
I think you misunderstood. They’re actually suggesting the exact opposite of a Windows-ey approach. Instead of logging onto a server and running a bunch of commands (or clicking buttons) to set it up, you make some sort of declarative configuration *beforehand* and then just let it run. Docker is probably the most popular application that uses this general idea. NixOS also follows this principle, and it’s phenomenal.
It also scales down really poorly. It’s fine for a corporate environment where you’re deploying or redeploying multiple similar systems, but in a home lab environment, like the sort that would most commonly have any association with a Hackaday article on Linux terminals, having to learn an entire deployment system and write bespoke deployment scripts is harder, consumes more effort, and is in the bespoke setting no more safe than just manually deploying the thing.
hmmm…
when I think of the Docker systems I see “Linux” getting “closer” to windows.
Every Docker image can contain its own set of libraries, dependencies and so on – kinda like installer for any applications on Windows.
You can get some of the same problems previously almost exclusively restricted to Windows. -> Ancient old libraries etc. messing up your security.
Not as bad but kinda similar (or am I missing something?).
There is this free ebook, “The UNIX- HATERS Handbook”, which covered the case of accidental deletion of entire file system by a typo or other mistake. The book is almost 30 years old. And still this happens? Does the rm command even ask “Are you sure you want to commit mass filecide? Y/N”?
there is. unless you use the option -f which literally mean “force”
It´s hard to fight against resolute stupidity, you know. With power comes responsibility.
And with Great Power, comes the ability to blame things on “tricksie hobbitses”.
Under normal circumstances you’re not allowed to remove files you don’t have permission to and even with sudo it’ll check if you want to remove a write protected file and under normal circumstances. Normally rm can’t be used to remove directories etiher.
You have to explicitly raise your level of access to root, provide a password and explicitly tell rm to recursively delete everything in your specified path including directories with -r and suppress prompts with -f for this to be a problem. Ie. The user needs to bypass 3 levels of control and use a password to mess this up. The issue isn’t rm, it’s users being taught that sudo rm -rf can be used without serious consideration first.
Still, users, and especially sysadmins manage to delete wrong things since early UNIX, and then in Linux. I think the main cause for this is the use of command line in general. Many system,s were damaged by accidental typo. With Windows you have to select files and folders you want to delete in the location you want to clean up, and then either use a keyboard shortcut or use mouse to select a delete command. Standard behavior is to delete to bin, and you have to force deletion to oblivion.
IIRC, there is a story about a sysadmin that wanted to type entire path for rm -rf, but after first slash he hit a space or enter and the command deleted the entire file system. You can’t do that when using GUI…
“rm” has a safety option “-i”. When used, rm asks “rm: remove [file type] [resolved file name]?” for each file or directory. Most distros have this enabled by default for the root user. However that gets really, really old , or even unworkable, when you’re deleting a directory which contains a bunch of files. So the ingrained behavior for admins is to turn the warnings off when deleting entire directories by including the “-f” flag (“force”, which disables “-i”) whenever you use “-r”.
I just realized there is an “-I” (capital i) option (on gnu rm at least) which prompts if there are four or more files resolved with a wildcard, or if “-r” is used. Unfortunately that only prompts “rm: remove N arguments?” and doesn’t say what they resolved to.
I believe some versions of rm always warn for the specific case of “rm -r /”. [Not going to verify that on my machines :)] But it’s not possible for the computer to figure out in general the difference between harmless (“rm -r bin”, when CWD is /tmp/foo/build) from the dangerous (“rm -r bin” when CWD is /usr). A graphical interface takes care of that pretty well by giving lots of context clues about the thing you’re dragging to the trash can.
That’s also why UNIX-like systems are still around. Modern Linux is like a modern chainsaw. It has a clutch, safety cutoffs, brake and guards. Get the job done every day for uncountable number of people all over the world. However, if someone decides to operate it in unsafe manner – it’s mostly his fault for getting hurt. Android is a perfect example of corporate shills trying to make a “safe” OS for users with average IQ of 70. It’s about as functional as a dildo, and the worst thing that can happen is user will chip his teeth with vibrations.
I call this a big pile of bovine manure.
UNIX and UNIX-like systems are quite good for running servers. These systems are the backbone of the Internet. And for two key reasons: many sysadmins are trained to use them despite their specific problems and shortcomings. And the alternatives are (apparently) worse. Some claim that the reason for popularity of those systems is that they’re free and open source, and “easy” to modify. In truth “free” is seldom cheap.
As for Android, it was created to be easy to use for average user. And it is. I never had any problems with my Android devices. It just works. And that’s the reason this Linux-based system is so successful. And why desktop Linux fails so badly when compared to the Windows or MacOS. And if you have chipped your tooth with vibrating dildo, I think it’s an user-device interface issue, specifically incorrect input port error. Retry, Abort, Ignore?
Retry, Abort, Ignore?
Use correct port and have a game of chess.
desktop Linux fails so badly ? Go tell that to Cortana, and get ads rewards and customized suggestion. If you manage to find the right drivers for your hardware. Maybe you have to install more apps from the MS store ?
Most linux distros will refuse these days, unless passed the option –no-preserve-root to force the issue. On other Unices your milage my vary. Most BSDs won’t block this behaviour because the behaviour of the rm command is defined by the posix standard. I believe SmartOS claimed a loophole where posix also claims rm can’t remove the current directory, the current directory must be under /, ergo rm can’t remove /.
When you rm -rf, the only thing that is prevented from being destroyed is the root. I think that’s the only case where it will block you, and you can bypass it with –no-preserve-root
That wouldn’t have helped in this case. They — and their friends — repeatedly used a custom-made script that wrote random blocks to the hard drive and to kernel memory. They didn’t accidentally commit mass filecide; they intentionally committed mass systemcide, but accidentally (repeatedly!) on the wrong target.
I wish their posting about it explained why they felt the need to do systemcide frequently.
That sounds like a hardcore test for something safety-critical that has to be designed to fail safe in all situations, including random hardware failure.
No, it doesnt*. Just last month we activly tried it on… Arch I think, and it wouldn’t let us.
and for everything else: enter a harmless overload function to bashrc?
*for some distributions
alias rm rm -i
perhaps?
For saftey I never start by typing an rm command directly. I start with ls and get the full path correct first, this way if something goes wrong like me hitting enter a little early then the worst that happens is I list the contents of a dirctory I don’t want rid of. Once my ls command is fully formed I run it once to check whats going to be deleted, hit up followed by ctl + A then replace ls with rm -rf.
I try and follow this basic idea any time I’m typing in a comand that has the possibility to really screw a filesystem and start with something more benign only subbing in the weapons grade command at the last.
Alias it to a shell script to add a custom confirmation:
“Are you sure you want to delete everything under [X] on machine [server name]?”
For added aggravation, require the user to enter the server name to confirm the action.
I do something similar, but using hostname based profiles in the terminal emulator – such that production hosts get a red background, staging blue, dev green. Foolproof.
Also don’t have partitions of other machines mounted – particularly not on /tmp !!!
(Yes, I remember someone who did it and it wasn’t me!)
I hate using colors. To prevent accidents I have a multi layer backup system. A bad error can be solved in minutes, a small catastrof takes two hours. Full catastrof (fire, flood, terrorism) about 30 hours.
It reminds me of time when I was using putty profiles where every production server had a red terminal background colour set, of course I configured it after I confused a prod server with a test instance
A prompt with a unique face, animal, food, object combination 🤔🐺🍉🕯️does not work on a simple tty but may be useful elsewhere, otherwise there are symbols that can be grouped for the same purpose that will work on all consoles and can have colour variants too. It is a sparse to sparse set transform problem, you want to have each machine ID “licence plate” as far, visually distinct, from all others as possible.
Reminds me of one of my early programming days. After a full day of hard work I decided to do a little clean up, so I typed:
rm * .o
Note the space. :)
First
find . -type f -name ‘*.o’
Then
find . -type f -name ‘*.o’ -exec rm {} \;
“When Fumblefingers Attack!”
I use synth-shell to customize my hosts with unique prompts and separate colors. I started doing so precisely to avoid confusing my servers when I was logged over SSH, although I’ve eventually added more functionalities to the prompt over time. I’ve posted it to my Github, simply search for synth-shell-prompt
I have a similar, simpler setup in ZSH:
https://i.imgur.com/q8fjPqI.png
https://gitlab.com/RunningDroid/minidots/-/blob/master/.zshrc#L85-94
$ alias rm /bin/rm -i
Oh and every time you use root spend an extra few seconds reading back the command you typed, or better yet copied and pasted from a previous successful execution, at least two or three times while confirming in your head that you are in the right folder and that the command will do what you think it will do and not any unexpected edge cases you did not think about. And always have a disaster recovery plan and good (tested) backups.
Counterpoint: YOLO!