
Once upon a time, machine learning was an arcane field, the preserve of a precious few researchers holed up in grand academic institutions. Progress was slow, and hard won. Today, however, just about anyone with a computer can dive into these topics and develop their own machine learning systems.
Shawn Hymel has been doing just that, in his work in developer relations and as a broader electronics educator. His current interest is reinforcement learning on a tiny scale. He came down to the 2023 Hackaday Supercon to tell us all about his work.
Rewards Are Everything
Shawn finds reinforcement learning highly exciting, particularly when it comes to robotics. “We’re now getting into the idea of, can robots not just do a thing you tell them to, but can they learn to do the thing you tell them to?” he says. Imagine a robot copter that learns to fly itself, or a self-driving car that intuitively learns to avoid pedestrians. The dream is robots that do not simply blindly follow orders, but learn and understand intuitively what to do.
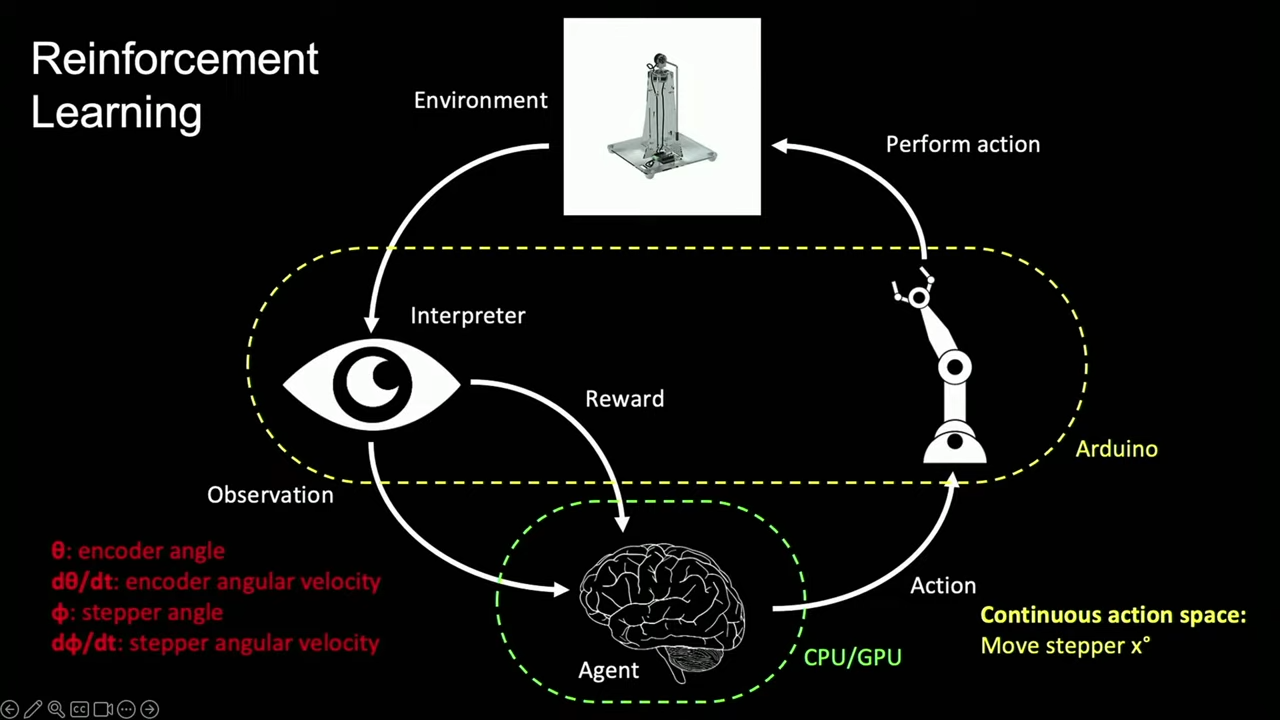
Obviously, a great deal of machine learning research involves teams of PhDs and millions of dollars in funding. As an individual, Shawn decided to start smaller. Rather than try and build an advanced quadripedal robot that could teach itself to walk, he instead started with a simple inverted pendulum. It’s a classical control theory project, but he set about getting it to work with reinforcement learning instead.
Reinforcement learning is all about observation. The AI in charge of the inverted pendulum can see the position of the pendulum, and its angular velocity. It can also swing it around with a stepper motor, and knows the stepper motor’s angle and velocity. The reinforcement part involves setting a “reward” for the desired position of the pendulum—namely, when it’s balancing in the inverted position. Thus, over time, the AI learns which actions correspond to this reward, and it effectively “learns” how to control the system.
As is often the way, Shawn’s first attempts didn’t work. There was too much latency between the measurements from the inverted pendulum being sent from an Arduino via serial reaching the AI agent running on his computer’s GPU. Thus, he simplified things. Instead of trying to get the pendulum to balance, he decided to just try and teach an AI to swing it up vertically. He also decided to run the AI on a microcontroller, eliminating much of the latency involved in trying to train a model on his GPU. He also simplified the action space—rather than continuous control of the stepper, the AI was only able to make three actions. Either add 10 degrees, subtract 10 degrees, or do nothing.
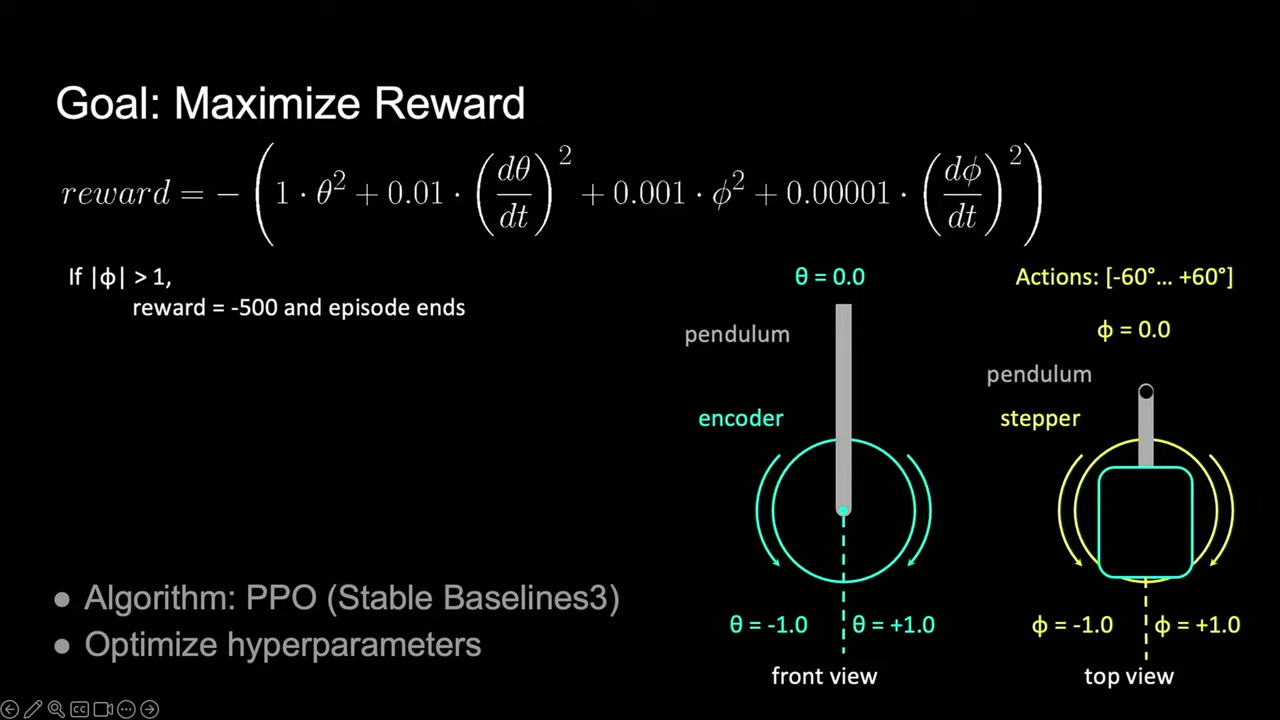
This proved far more successful. He was able to train a model using the Stable Baselines3 framework that could successfully make positive actions towards flipping up the pendulum. Once trained using the actor-critic method, the actor half of the model could be deployed to a microcontroller and tested on the real system.
He used Edge Impulse to compress the model and ran it on a Seeed Studio XIAO ESP32S3. The microcontroller no longer needs to run the reward function, as it’s already been trained on how to act to get the desired result. It just goes ahead and does its thing. The live demo worked, too — the model was able to swing the pendulum (briefly) into the vertical position.
Finding the Best Tool for the Job
Shawn notes that for reinforcement learning tasks like these, virtual training grounds can be of great value. They allow much training to happen much faster, often with thousands of iterations running in parallel. There’s also less hassle versus training models on real mechanical hardware, which can get damaged or require manual resets after each training run.
All this is not to say that reinforcement learning is the be-all and end-all of robotics these days. As Shawn explains, for many tasks, particularly straightforward and repetitive ones, classical control theory remains supreme. Just because you can do a task with machine learning techniques, doesn’t mean it’s the best way to go about it.
Ultimately, reinforcement learning can help a machine achieve all kinds of complicated tasks. The trick is to create the right reward function and measure the right parameters. As Shawn ably demonstrates, choosing an appropriately simple goal is also a great way to get started!














So, once it’s in actor half mode, it is no longer able to learn but only “remembers” what it had once learned. So it will never get smarter or better.
“Once trained using the actor-critic method, the actor half of the model could be deployed to a microcontroller and tested on the real system….
The microcontroller no longer needs to run the reward function, as it’s already been trained on how to act to get the desired result. It just goes ahead and does its thing. “
Leaving the “learning” in place often turns your model to crap over time. See “catastrophic forgetting.” The real world often doesn’t contain the same perfectly balanced mix of all possible cases, so the model just slowly slides into uselessness as it becomes less and less general. Better to train a good, highly-experienced model and then just lock everything into place.