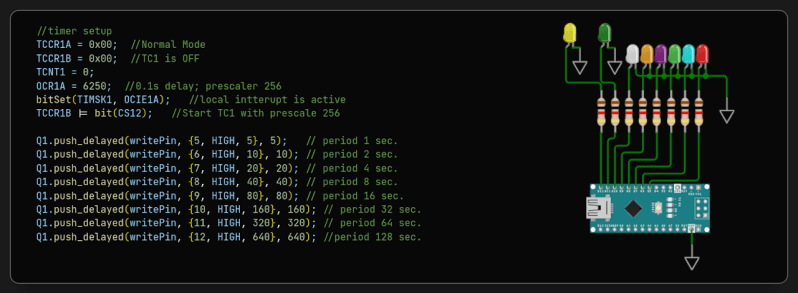
Embedded programming is a tricky task that looks straightforward to the uninitiated, but those with a few decades of experience know differently. Getting what you want to work predictably or even fit into the target can be challenging. When you get to a certain level of complexity, breaking code down into multiple tasks can become necessary, and then most of us will reach for a real-time operating system (RTOS), and the real fun begins. [Aleksei Tertychnyi] clearly understands such issues but instead came up with an alternative they call ANTIRTOS.
The idea behind the project is not to use an RTOS at all but to manage tasks deterministically by utilizing multiple queues of function pointers. The work results in an ultra-lightweight task management library targeting embedded platforms, whether Arduino-based or otherwise. It’s pure C++, so it generally doesn’t matter. The emphasis is on rapid interrupt response, which is, we know, critical to a good embedded design. Implemented as a single header file that is less than 350 lines long, it is not hard to understand (provided you know C++ templates!) and easy to extend to add needed features as they arise. A small code base also makes debugging easier. A vital point of the project is the management of delay routines. Instead of a plain delay(), you write a custom version that executes your short execution task queue, so no time is wasted. Of course, you have to plan how the tasks are grouped and scheduled and all the data flow issues, but that’s all the stuff you’d be doing anyway.
The GitHub project page has some clear examples and is the place to grab that header file to try it yourself. When you really need an RTOS, you have a lot of choices, mostly costing money, but here’s our guide to two popular open source projects: FreeRTOS and ChibiOS. Sometimes, an RTOS isn’t enough, so we design our own full OS from scratch — sort of.














I did something similar, around an event queue, and added several macros similar to the ones used in C coroutines to allow to write asynchronous functions. I used it for the firmware in my keyboard.
Let’s try to put the link… https://gitlab.com/rastersoft/full-ten-keyless It is in the “firmware” folder, and the key files are ‘eventloop.c’ and ‘eventloop.h’
Thank you for this :-)
I use some sensors that have their own ASICs and their readout is not constant time depending on the state of the ASIC when polling it. I just bypass this in my delays by logging diffing the millis before and after and subtract the time it took of my delays. that way the delay really is the delay I did intend, sans the senser readout lag.
Might be a caveman solution in my own case, but I keep this header file in mind. Seems cool! It’s just, I don’t make great enough projects to need that precision yet. Wish I could see it in a video, my own work seems to be very basic.
To me the only caveman-ey thing is using delays instead of timer interrupts. Only really an issue if you’re on battery power or would like to do processing in those delay cycles, though.
To be honest, limiting power usage should always be one of the top priorities when writing embedded code.
First and foremost because IF you will need to limit power usage at a later stage, but you cavemanned your code like this, you’re gonna be in big trouble. Because you will invariably have to implement a whole different architecture, probably meaning that you need to rewrite everything from scratch, meaning that all your testing and validation will have to be redone from scratch.
I have asked if they can call WFI instead.
Event queues are awful, what if you miss an event or event flooding?
Just use cooperative scheduler and polling+interrupts for 99% of cases.
Why not just FreeRTOS+avoiding shared memory as much as you can? I’ve never had a problem with it and it’s widely used and trusted, and there are a few others that seem to be almost as trusted, and a commercial version that’s even safer…
I think that if we ever have flooding events, meshtastic could be a great help! Now that’s science!
As someone who has written several cooperative schedulers, I approve. They’re awesome
Little secret: the TomTom application on their navigation devices uses coöperative scheduling as well. With some interesting optimisations to increase responsiveness to user-input.
But to be honest, if the tasks need to do a lot of work, the tasks will also need a lot of functionality to split the work into small enough pieces to process without taking too much time. It can add a lot of overhead (in code, I mean, but also in design) and the code can become quite tricky. Also, the tasks have to restrain their use of memory. So having to process a lot of data can turn the code ugly very quickly.
But, the worst problem is: acting upon asynchronous input, like user interaction. There you are: you’re got a touch screen and it registers touches on an interrupt. But you can’t do real work in the interrupt, just register the touches and transform them into swipes, clicks, doubleclicks, etc. And then you post those in a queue. If you’re lucky, the task that handles the input is next in line to be executed. If you’re unlucky, it was just handled and will take a few ms. or more before it will be called. So you get choppy user-input an choppy output as well (scrolling). So you have to optimize the scheduling so that you can signal the current task that it needs to save state and stop asap, and pull the user-input handling task up the scheduler queue so that it gets executed next. But tasks are not independent, and you can’t always just invert the order, and… well, there are a hundred more “but”s…
Bottom line, I think, is: programming is hard, there is no catch-all solution, and the more feature rich you make your software, the more you will get into “custom solutions” (i.e. tricks, workarounds, and hacks).
Unless you have huge computing power and memory, and can use pre-emptive multitasking without fear of battery drainage and memory fragmentation.
Not sure I get it, these are logically equivalent, they just invert the control.
@Dave Rowntree said: “The idea behind the project is not to use an RTOS at all but to manage tasks deterministically by utilizing multiple queues of function pointers.”
If I am not mistaken, you just described how a basic RTOS works. The next step up in sophistication is to add a scheduler and memory management unit (MMU).
An RTOS hase pros and cons. One obvious con is overhead in task switching and in terms of memory (every thread needs its own stack).
Asuming you have a single core MCU and you have multiple timing critical processes/tasks you can implement your program in various ways:
-use an polling loop, every task is an explicit state machine and the processing of a single tick/iteration cannot take more than a certain amount or a step has to be split in multiple smaller steps (states or substates)
-use an polling loop, like above, but process critical things in interrupts
-use an RTOS, every thread becomes an implicit state machine and can be interrupted/continued at any point any busy wait can easily be converted into a semaphore wait and busy delays can be converted to RTOS delays
Sometimes you have a third party library that does some slow calculation. It can be a lot of work to rewrite the code to an explicit state machine that can be interrupted and continued.
Putting it in a low priority thread and optionally replacing busy waiting and busy delays can make it work easily in the background without rewriting it.
I’ve used loops, interrupts and an RTOS. But there is a point where a complex loop basically becomes a primitive task scheduler with software timers so you are almost writing your own RTOS.
In such a case an RTOS might be a better option.
What about not using RTOS and start doing this determistically?
Oh, but the lazy coders. Doing embedded systems. (facepalm)
One of the biggest drawbacks of an RTOS is interrupt overhead. Managing of tasks is usually done from within an ISR and this increases ISR latency.
On bigger systems, especially when you have multiple ISR priority levels this is not a big problem, but not for the smaller and simpler 8-bit architectures. Especially the Atmega’s don’t work nicely with an RTOS. Both because of it’s limited architecture, and it’s abundance of registers, which takes a lot of pushing and popping for a task switch. A simple system like this can help to keep your code organized. It’s much better then blinking a led with software delays and blocking all programming.
OTOH, just setting up a few interrupts is perfect for blinking a few LEDs. I’d say pick the tool for the job:
– Only a few inputs and outputs (whether GPIO or pushing/popping serial registers): Interrupts for everything
– Once you have a few processing loops that start fighting: a pointer queue like this might help
– A bunch more: get something 32bit and run an RTOS
My projects almost always fall into the first category, so I might be missing something.
Sorry, noob here. Is ISR an Interupt Service Routine?
yes mate
Yes.
This is fine for very short tasks, but for multistep tasks, you would have to queue each step after the trigger for each step, which means you would have to maintain some form of state machine. For many cases, it’s simpler and more maintainable to use coroutines such as protothreads.
When you have a function pointer, you already have a state machine. The pointer always points to the current state, and you just change the pointer to another function for another state. I have built state machines this way, and it worked very nicely.
Consider the following multistep task of comms with some slow device, which involves: claiming a communications interface, sending a poll request, waiting for a response, sending a value, waiting for an acknowledgment, retrying on failure or timeout, and finally releasing the communications interface.
You’d need a function for every step.
I’ll only do state machines via code generation these days. If I’m ever manually writing a state machine, I’m doing my job wrong. It’s far too difficult to get a non-trivial manually crafted machine to be robust to the required level.
I can describe a state machine and be certain that all the error states are caught and handled, and I can generate dot graphs to validate that every state and every transition is modelled the way I expect. It’s basically guaranteed that neither of those things is true for any hand-crafted machine.
And that’s before I even get into the gnarlier issues like accidental non-determinism…
ugh so
the part i like is the idea of just hand-rolling something simple. one of the things that continues to delight me is that ideas that are novel at first might seem complicated but a lot of times you throw them into code and it becomes 10 or 20 lines, maybe 100 once you add in the framework around it.
i’m gonna credit forth with giving me a real appreciation of this idea…in forth, you can use ‘IMMEDIATE’ words to essentially implement your own domain-specific language. no sophistication, just implementation. and i’ve run with this idea in a very unoriginal way, i’ve made a handful of pidgin forths for different (mostly embedded) projects. and it always amazes me how just a tiny effort on the framework — a “compiler” literally written in 70 lines of C — and suddenly the rest of the project feels like i’m writing in a high-level language. but without enduring any of the vagaries of a full-featured compiler or runtime library. it’s the to-the-metal experience i want but also comfortable at the same time!
i have a perhaps-unjustified hatred of arduino (and SDKs and IDEs in general). you might call my hack ‘anti-high level language’ in the parlance of this article.
the thing is, what makes these special, is that they’re so simple! from anywhere i stand, i can see all the way to the bottom and to the top. and i only reuse code in the most haphazard fashion. i don’t generalize. that’s the real forth lesson, that’s what Chuck Moore says when you invite him to speak to your club: don’t generalize. i love generalization. so i appreciate this reminder…just solve the problem in front of you in the simplest and clearest way possible. and then when you find out it’s really a different problem, you benefit from the transparency of your original code. your first draft doesn’t have all of the features or structure, but it also is so small and simple you can understand it and then throw it away in the rewrite. pluses and minuses but it’s a good approach to at least have in your toolbag.
and that’s where this project goes off the rails imo. an anti-rtos should be a one-off. once it generalizes, once it becomes code you lug around from one project to the next, then it has to grow warts. it has to solve problems you haven’t seen yet. and it can’t. that’s the fundamental “anti-[big thing]” innovation…you can’t solve the problem that isn’t in front of you so don’t try. but this tries.
on top of that…C++ yecht. no one can really read C++ templates. i believe that if Bjarne Stroustrup sits down to a weekend hack, he writes his templates by trial-and-error, a frustrating dialogue with the compiler’s verbose and opaque template-oriented error messages. and yeah it’s possible to know what C++ is doing, which templates are instantiated, what book-keeping, implicit destructor calls, exceptions, run-time type information, virtual functons, memory allocation, it’s possible to get to the bottom of any of it. but if you do, you defeat the purpose of C++. if you have to see to the bottom, you violate encapsulation.
haha and it’s hard for me to not nitpick the C++. it seems like Aleksei is afraid of the new C++ features, a mindset i strongly agree with. but it means the work queues are dynamically-allocated with new[] and delete[], and it also accounts for the large size of this extremely simple framework. there’s 4 different implementations of the work queue — no arg, arg, delay no arg, delay arg. and the arg processing introduces copying questions (copying is the hardest question in all of C++). and it only supports a single arg. if it was a one-off, the simplicity would not be obscured by the redundant 4 implementations. and if it wasn’t C++, you’d pass a void* instead of a template and you’d dodge the copying question. so the upside is, the templates are very easy to read but the downside is that’s because they don’t give you a genuine expressive advatage.
OTOH, cycles are cheap in 2024. why shouldn’t a tiny RTOS incur absolutely unnecessary memory management overhead?
haha so it’s neat idea but i’d personally respect it a lot more if it was a one-off hack as part of a cat toy or something. in my mind, lightweight frameworks, anti-frameworks, are brilliant precisely because you throw them away. i might cut and paste but i would never genuinely re-use something like this.
but maybe i’m entirely wrong and the point is to look at it and not to use it, and if that’s the case then really it’s a pretty good demonstration of just how easy this can be!
do you have a repo where we can look at your forths written in C ? i am quite interested :)
it’s not great, it’s just a very stupid idea that enabled it. it breaks its ‘source’ input into tokens, each token is a punctuation followed by an alphanumeric identifier. and i implemented about half a dozen prefixes, each one of which was basically expanded as if it was the simplest assembler macro. :foo defines a label. ; is function return. /foo defines a word symbol named foo. .foo calls a function. ,foo pushes the word symbol on the stack. a line that starts with ” is produced verbatim in the assembly, which i used to define the basic words like :add and :sub. so far i’ve made 3 of them and chosen a different set of prefixes each time. :)
the first one, for m68k back in college 25 years ago https://galexander.org/x/c335-final.tar.gz
I’ve got one here which is a single file which contains C, sh, awk and Forth: https://github.com/davidgiven/fforth/
That one’s been tested on a bunch of systems including the Z80 and amd64, so it scales reasonably well in both directions. System words are precompiled and the tokens embedded within the source file. Running the source file as a script redoes the precompilation and patches the source file with the updated data.
You basically described the not-invented-here syndrome on steroids. Fine for one-off cat toys, absolute nightmare in any professional context.
hahah yeah for sure! i don’t think “anti-___” development has much place in bureaucratized development environments!
though it’s a little more suited than i think you might give credit for. if you’re building a car, and you need a headlight controller…like an attiny that speaks CAN and controls a mosfet driver or something…it would be a lot easier both to validate and to maintain that unit if it contained only 100 lines of code total, even if those 100 lines of code were a completely redundant bespoke reimplementation of 100,000 lines of library. of course lots of other factors could outweigh that advantage!
there are lots of times when it’s great to use a fully-featured framework but also there are genuine advantages to throwing it away if you can make something that is genuinely small as a result.
RTOSes in general are an absolute nightmare. Because of priority inversion. Anything that allows you to avoid using an RTOS is a massive improvement in development costs and quality.
i’m pretty ignorant all around — i had to google ‘priority inversion rtos’. when i’ve done real time tasks (using regular linux user scheduling), i take great care to make sure that the high priority thread (refilling the audio buffer, or refreshing the frame buffer) has a fundamentally non-blocking interface to global data structure, using things like compare-and-swap, atomic store, statically-allocated buffers.
it seems like this problem is not so much in the RTOS experience itself but rather in sloppy design of multithreaded code?
in line with the thread on software engineering on the AI co-pilot article, i have found multithreaded programming to be extremely hard to classify! i’ve come up with a few great designs over the years but it is always a process of very carefully discerning the true requirements and then inventing bespoke idioms to make it so. i haven’t found any general structure to be useful for threading, and i wonder if problems like priority inversion aren’t a result of failed attempts to generalize something that resists generalization.
in particular, i find that mutex is not a good root idiom. but i also can’t rule it out, a lot of problems i can’t solve ‘properly’ without mutex.
The priority inversion is a problem even if you do not have an RTOS, but have a set of interrupt handlers. It is very hard to reason about all possible sequences of interrupt processing that might happen during some critical time period.
So the alternative is to always assume the worst case scenario (like, all interrupts triggered, all peripherals have input data at the same time) and poll the peripherals with an interval that is known to fit this worst case scenario data processing. Then you’ll have a true hard real-time, with a 100% guaranteed, statically known response latency.
It’s a pretty potent generalisation of a very wide range of event processing scenarios under hard real-time requirements.
Threads are quite a bit different story altogether here. You can do this deterministic polling style processing with multiple threads too, as long as there is only one thread that generates the timing signal, and all the threads are doing deterministic polling loop, with communication between them happening in, again, deterministic moments on their timelines. FIFOs (e.g., ring buffers) are a perfect abstraction for such communication, and for time synchronisation (as in, propagating the time sync command) simple spin-locks are the most deterministic.
Of course, this is not the most energy efficient approach, no sleeping is allowed here. In most of the hard real-time applications though energy efficiency is not the top priority.
combinatorylogic – i definitely appreciate how polling gives you such a defined response time!
the reason i almost never poll is that i usually have the “main loop” running something that isn’t as time-critical…like the ISRs will empty and fill circle buffers, and the main loop will process things between one buffer and the next. so i can do slow calculations in there, and maybe it’s undesirable if they become “an entire frame behind realtime” but at least the PWM will not glitch. so i will have timer-counter interrupt to generate the encoding, or edge detect interrupt to decode it “in the background”. note i’m thinking about embedded chips pic stm32 rp2040 etc that have a set of flexible timer-counter-io sort of interrupts.
of course i get away with it because my projects are dead simple. i can enforce really simplifying assumptions like each queue has exactly one reader and one writer. it’s simple enough i can put an upper limit to how far behind it can fall, so i have no hesitation to use fixed-length queues and drop on overflow. i suppose i could even write them as cooperative multitasking pretty easily.
where do you put your general non-time-critical logic, if the main loop is polling? it seems like i’d be tempted to use the second core that every chip these days seems to have but that introduces an even worse multithreading question :)
“Chuck Moore says when you invite him to speak to your club: don’t generalize.”
“Specialisation is for insects” Lazarus Long.
Both have a point. If you are producing something small that only needs to do one thing then specialise it. It’s an insect. In your example, presumably it only needs to read the CAN bus, and either change the state of the headlights between off, low and high, or maybe report the state of the headlights.
If you are producing something larger (the main car controller unit, for example) then you probably want to generalize more. You need to be able to understand more CAN bus messages than just the headlight ones. You can’t get away with pre formatted messages that you just dump on the wire without understanding them.
i totally agree…generalization is full of benefits.
but you can’t really preemptively solve unanticipated needs. very simple example, you have a queue…you re-use a general full-featured implementation that provides separate insert-at-head and insert-at-tail. now you come to it a year later and you have to add a feature that is trivial if you can assume no one ever inserts-at-tail. now you have to go about proving it can’t insert at tail in the existing codebase, and maybe even scattering comments around advising the next guy to never insert at the tail.
or you can implement the queue as a bespoke one-off because insert-at-head is the simplest ever linklist…then someday you come along and you realize you’ve got to implement a big hairy priority-based visit of the queue that would be totally trivial if only you could insert at the tail instead of the head!
you can’t win! you can only solve the problem in front of you today. there’s almost no way to anticipate whether future you will feel a more pressing need to insert-at-tail vs a need to prove no one ever inserts-at-tail.
but personally, once it’s gelled for a while, i’d rather have the version that implements exactly what’s needed (specialized) rather than one that has a bunch of vestigial parts hanging off of it that are part of a good generalized implementation but never actually used. but i won’t necessarily know that when i start.
do you have a repo where we can look at your forths written in C ? i am quite interested :)
https://github.com/WeSpeakEnglish/ANTIRTOS_C
After reading the examples, I’m not sure how F1, F2…. Are defined and I’m not sure how the scheduling works, like is it F1[0], F2[0]… Or is it F1[0], F1[1]… I can’t find this information which would be needed before I start working on anything with this framework. This seems to be a good idea but the documentation seems to be more about the idea rather than the implementation.
they’re regular C++ variables. “fQ F1(8);” defines an object of type fQ. the whole “antirtos kernel” is in antirtos.h, which is basically an implementation of class fQ, and three classes that are just like it. it’s just a simple queue of function pointers. push() to add a function pointer to the queue, pull() to remove one and call it. it’s “just” a delayed function call, really.
so the only thing missing from the example in the first example is the void main(void) { setup(); while (1) loop(); }
If you need several queues (for example, you want to push functions to first queue (F1) from one interrupt (ISR), and push other functions into second queue from another interrupt (ISR)).
In this case simply utilize both queues, so functional pointers will be placed F1[0], F1[1]…. and F2[0], F2[1]…
If you need only one queue , you may push into one (for example it could be again 2 interrupts if they not overlap each other), then it may be: F1[0], F1[1]… only.
In example folder on git repo there are also some examples (https://github.com/WeSpeakEnglish/ANTIRTOS/tree/main/examples)
BTW, you may use any of these 4 classes alone if you need. they are independent.
c++ already has everything you need to spawn threads. Why not use them in your antios?
because you can’t use threads on microcontrollers
And how are you going to do the scheduling of the said threads in a deterministic way?
I read that as “Antritos” which seems the perfect complement to Doritos.
You lost me on ++
+1
I’ve had similar thoughts. Basically all interrupts push to lightweight queues and the main loop just runs protothreads either round-robin or with a simple, deterministic scheduler.
There’s an even better approach – ditch interrupts altogether and avoid the headache of identifying priority inversion scenarios. Just poll all the inputs all the time, in a deterministic sequence.
Situation: There are 15 competing RTOSes.
“This is ridiculous! I’ll just write a lightweight task system instead!”
Soon: There are 16 competing RTOSes.
New RTOS’s will be introduced until morale improves.
So many projects on task schedulers and rtos, everyone taking linus torvalds to the pub over it. I guess not only is riscv not doing much and t2 linux and google protocol buffer (https://github.com/protocolbuffers/protobuf) not the matter but a generative nerdy os is about to come and generative fps shooters to yes.
Indeed, RTOS is a wrong approach when you need not only predictable, but very low latency. A deterministic polling loop, always going through the worst case path is a better approach in such scenarios. Caveat – energy consumption, you cannot use sleep modes if you poll continuously.
If you’re implementing, say, an FoC motor controller, it’s not a problem – MCU power consumption will be negligible anyway in comparison to the rest of the system.