Over the years there have been a few CPUs designed to directly run a high-level programming language, the most common approach being to build a physical manifestation of a portable code virtual machine. An example might be the experimental Java processors which implemented the JVM. Similarly, in 1976 Itty Bitty Computers released an implementation of Tiny BASIC which used a simple virtual machine, and to celebrate 50 years of Tiny BASIC, [Zoltan Pekic] designed a CPU that mirrors that VM.
The CPU was created within a Digilent Anvyl board, and the VHDL file is freely available. The microcode mapping ROM was generated by a microcode compiler, also written by [Zoltan]. The original design could execute all of the 40 instructions included in the reference implementation of Tiny BASIC; later iterations extended it a bit more. To benchmark its performance, [Zoltan] set the clock rate on the development board equal to those of various other retrocomputers, then compared the times each took to calculate the prime numbers under 1000 using the same Tiny BASIC program. The BASIC CPU outperformed all of them except for Digital Microsystems’ HEX29.
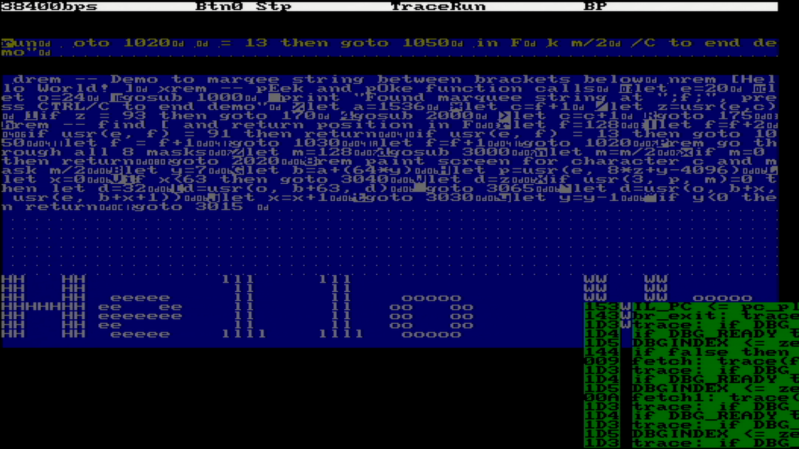
The next step was to add a number of performance optimizations, including a GOTO cache and better use of parallel operations. [Zoltan] then wrote a “Hello World” demo, which can be seen below, and extended the dialect of Tiny BASIC with FOR loops, INPUT statements, multiple LET statements, the modulo operator, and more. Finally, he also extended the CPU from 16-bit to 32-bit to be able to run an additional benchmark, on which it once again outperformed retrocomputers with comparable clock speeds.
We’ve previously seen [Zoltan]’s work with FPGAs, whether it’s giving one a cassette interface or using one to directly access a CPU’s memory bus. BASIC has always been a cross-platform pioneer, once even to the extent of creating a free national standard.














Just over 40 years ago, I looked at doing this kind of thing with AMD2900 bit slices. I abandoned the idea for two reasons.
Firstly, while it would have been a speed increase over existing processors (80386, 68000), that advantage would have disappeared in a couple of years. Now that processors are no longer improving that rapidly, that might not be true nowadays.
Secondly, advanced compiler techniques (e.g. peephole optimisation of the IL instructions) gave even larger performance increases. Nowadays such techniques – and many more – are widespread.
Nonetheless, creating a processor is a standard “fantasy” for hardware engineers. For software engineers the equivalent is creating a language. Both are fun and harmless, but shouldn’t be confused with useful :)
I’ll also note that comparing different processor’s performance normalised to clock speed was (and is) highly misleading, since some processors require many more clocks to execute one instruction. The 1802 is and example.
Yeah i think i’ve gone through the same evolution. I used to be very interested in forth-oriented CPUs, little stack machines where there would be a one-to-one direct compilation of forth words into cpu instructions. There’s no denying the elegance of such a system, or the potential for efficiency.
But these days, there’s such an enormous number of transistors in any little flake of silicon. A “real” compiler can target a stack machine or a register machine just as easily, regardless of the input language.
Even more than the ever-increasing MIPS and bytes, compilers have just become demystified to me. The “complexity” of any given code generator just doesn’t seem significant anymore. A lot of classical compiler meditations, like 1-token look-ahead in tree-parsing, turn out to be nothing burgers. Even when you counted memory in single digit kilobytes, it wasn’t hardly necessary to bend over backwards like that. I feel like a lot of early compiler progress was really all about convincing ourselves that it’s possible. Now we know it’s possible and it turns out it’s actually a lot easier than the contortions they used to put themselves through. Thanks to huge amounts of RAM and cache and pipelines, the naive O(n^3) algorithm is often faster than the fancy O(n) algorithm was, but the surprising part is it was faster on the older machines too we just didn’t realize it because we hadn’t yet convinced ourselves how well-bounded the recursion is in practice.
Always changing my perspective within my single lifetime. Hard to imagine the perspective of future people. But i’ve definitely lost interest in novel architectures. Even an x86-32 code generator for whatever language isn’t that tricky. The implicit code generator in QEMU’s JIT engine, for example, is quite elegant and simple. Machine translation of code is a solved problem. Knock on wood :)
Many of the time ansistors on modern PC/server processors are dedicated.to caches and OoO execution. But there is a viable alternative for parallel applications: barrel processors. The basic principle is to note that instructions are executed much faster than memory accesses, and so to share one core between multiple threads. For x86, such SMT is typically 2, but that is not adventurous :)
Sun took it to 64 threads in its Niagara T-series processors. Each thread executes at the same speed as main memory, so caches and OoO execution is irrelevant. That frees up silicon estate for the 64 simple cores, each of which executes the same SPARC instructions set. Overall it works extremely well on embarrassingly parallel server loads.
XMOS take a different tack for hard realtime embedded processors. They have up to 32 cores on a 4000MIPS chip, each with people romance guaranteed before execution. None of this measure and hope you blundered across the worst case rubbish! Chips can be transparently connected in parallel.
Uniquely XMOS also provides a decent software environment for multi core processing, which other processors completely fail to address. That’s down to it being inspired by the Transputer and Occam/CSP.
XMOS used to have a unique instruction set, but I believe they are in the process of switching to an augmented RISC-V instruction set.
I want to learn more about time ansistors and people romance of CPUs. 😉
A little over 30 years ago, I designed and implemented a virtual instruction set for a BASIC that the company I worked for sold. It used a PC-based compiler, and the runtime engine that interpreted the compiled instructions ran on a few PIC variants (mostly 16F74 and 16F877).
A few years after the initial implementation, I realized that the virtual instruction set I’d designed was pretty similar to the the MSP430’s instruction set, and fantasized about porting it over. Of course, I never did.
You are a very special kind of crazy: In the most brilliant way.
The AMD 2900 can switch contexts, i.e. WISC, writeable instruction cores… in two clock cycles:
So… You could run two operating systems at the same time, or you could run two instruction sets at the same time… This is what lit IBM on fire! They made the XT/370 system on a chip with this idea.
But oddly enough you could run two different instruction sets, and 4 different operating systems…
Unlinke modern cores, you have to restart to switch back to single instruction sets.
You could run a BASIC based OS, and a Pascal based OS… or even a Modula-2 OS, like the Lilth. ( an idea way way before its time ).
IBM Ran a PL/1 based OS, and Prime ran a PL/M based OS. The former was good for a long while, while the latter … had mini’s stacked up for recycling.
Of course these days, the ideas may come back…
When Intel heard of this they designed their own bit-slice… but even for all the advantages… it was incredibly slow.
Hi Tom! At first, I was thinking of implementing the Tiny Basic using (virtual) Am2901 slices (I have a project in which a faster Am9080 is implemented using bit-slices), but then I realized that adds just one more layer in the TBIL implementation, so opted for custom RTL design. The intent was learning / playing (covering everything from MUXs and hardware division to AI-supported vibe coding) but also maybe encouraging similar Tiny Basic ports for custom home-brew CPUs out there. However, it would be possible with some additional effort to create a home-brew Tiny Basic IC (similar to 8052AH Basic, or Basic Stamp, but much faster)
I wrote a tetris clone on the Atari800 in the 80’s. It was painfully slow, partly because I wrote it for simplicity instead of trying to optimize it. But that’s because I intended to run it through a Basic compiler someone had give me. That compiler didn’t do floating point, all variables were 16bit integers, but my Tetris ran GREAT after compiling.
Dig up that old Tetris code and modify it to run on this Tiny Basic CPU :-) You saw the speed the characters moving on VGA animated simply through Basic PEEK/POKE (USR in this case) – seems adequate (at 100MHz at least)
Single task OS running an interactive BASIC or FIG Forth may be useful
in our developing Nanocomputer hardware technologies?
Both BASIC and Forth can be used to load and run c codes? Or binaries
produced using other languages in a cross compile mode?
Big Tech multitasking large OS technologies are in appropriate for Nanocomputers?
Yes! Interactive BASIC and an option to compile. No sense trying to re-invent the wheel… Apple Soft Basic at 5Ghz? FIG Forth is much lighter weight and more efficient, so it could preform well at much lower clock speeds. Why not do multi-tasking?
I always think dearly of the Lilth machine that ran Modula-2 as its OS.
The Symbolics LISP machine, Data General also used PL/1, IBM Z/OS is based on PL/S.
The Early Macintoshes were SmallTalk/Pascal
I will never forget the first time I started TurboPascal on a machine with a 8087. It was ridiculously faster, I looked at my friend and said “We should write an operating system in this!”
Microsoft AI CEO Mustafa Suleyman says it will cost ‘hundreds of billions’ to keep up with frontier AI in the next decade
Big Tech LLVM/CLANG and Framework software technologies are what Suleyman is referring to?
I would like to ask for a comparison of how much electricity these processors consumed. Do these optimisations actually save electricity?
Can I run an old processor on a solar panel the size of a teacup?
Interesting idea, though, I do not fully understand why not just design a custom CPU for some kind of VM, walk backwards, so to speak. VM would have already handled things rather well, so making virtual registers into physical registers, etc, should be reasonably straightforward process.
FOr my humble needs, however, I would probably want to have something else – a CPU with different incompatible cores (ie, for example, Intel and AMD and ARM) running concurrently. That way what works best on one kind runs there, and spares shoehorning it into another CPU bottlenecks. I’d be willing to pay three prices, too, given I can pick some kind of open source code and compile it onto three separate CPUs at the same time, then pick the one that runs better, and discard the other two compiles. Any thoughts on that front? Oh, and I’d also want to have some kind of low-power standby CPU included as well, so that it can comandeer things like GPIO while partially turned off, and wake up on demand for heavy computation tasks. Kinda like what ESP32 clones do already, low-power mode where basic/simple things still can be handled, say, play DOS games on a low-power CPU while the other three monsters are offline.
Funny enough, I’ve seen more than one board with multiple cores like that, though NONE are approved to the shipped to the US, so they are unobtainiums now. Why? I don’t know. I ordered one through Amazon just this year, and it was suddenly cancelled, money refunded, apology email stated that none of this kind can be shipped to the US.
Is this an FCC Part 15 (radio-emissions) thing, an embargo thing (“North Korea Special!”), a physical thing (plastic made of components that are too flammable/too toxic/too something-bad), or something else?
I am unsure why or, how this board, too, cannot be shipped to the US address – Sipeed Tang Primer 25K. I imagine if I scout local warehouses I might find one in stock, but otherwise it was one I’ve tried ordering just recently (last week) and it was rejected at the Amazon checkout.
The one I’ve mentioned was one of those newly-issued boards that only appeared online early this year. It was one of the advanced multi-core ARM plus FPGA boards; it might have been mentioned here, on HD, too, so must be one of those dual-use kinds that go into military drones or something. I truly have no way of knowing that part, since I am not working for anything connected with the military, nor I a EVER want to do anything with the war mongers (personal reasons, unrelated).
I don’t think the tang primer 25k has any arm cores. As far as I know the only one with arm cores is the tang nano 4k, although you may be able to run soft arm cores on the FPGA fabric.
There shouldn’t be any problem getting them in the US. I am not in the US but I am not aware of any official supplier for them on Amazon or eBay so it was likely a reseller you found. If you go to the sipeed store on AliExpress you may be able to buy one. They have a lot more than just the tang primer 25k too.
Amazon US:
Sipeed Tang Primer 25K GW5A FPGA Development Board, 64Mbits Linux RISCV Single Board Computer, with MIPI 2.5Gbps Ethernet PMOD Port for FPGA Education, Support SDRAM HDMI Camera Module (SDRAM Bundle)
$38.99 + $11.98 delivery January 22 – 30
Most recent review is five stars and dated April 11, 2025
Hi Sammie Gee – this project is exactly the custom CPU designed for Tiny Basic VM as you suggested. But any number of other hardware implementations are possible. For example, “GL” (get line instruction) doesn’t prescribe where the input line buffer should be mapped into memory, how long it should be, how characters end up there etc – only that when ENTER is written into buffer, GL instruction should terminate and Basic pointer should point to the first character to be ready for parsing. In my CPU I chose to have parallel byte-wide ports, internal 16-bit memory pointer registers and a specific memory map. All of these could change is some other implementations. When designing the CPU I consulted existing implementations in C, as well as in 6800, 6502 and 1802 assemblers, but I was not bound by any of the constraints found there – for example 3 stacks and variable store needed by the VM are not memory mapped but are internal and in some cases operating in parallel.
Thank you for taking time explaining it better, this makes sense.
If I am to design things from scratch I’d probably start with the same steps.
Not sure if possible but if processors were designed to have all the memory safety features of rust it would save a lot of c code from being thrown out.
See Mill Computing’s processor, CHERI processors, CAP machines.