
I have always laughed at people who keep multitools–those modern Swiss army knives–in their toolbox. To me, the whole premise of a multitool is that they keep me from going to the toolbox. If I’ve got time to go to the garage, I’m going to get the right tool for the job.
Not that I don’t like a good multitool. They are expedient and great to get a job done. That’s kind of the way I feel about axasm — a universal assembler I’ve been hacking together. To call it a cross assembler hack doesn’t do it justice. It is a huge and ugly hack, but it does get the job done. If I needed something serious, I’d go to the tool box and get a real assembler, but sometimes you just want to use what’s in your pocket.
Why A Cross Assembler?
 You are probably wondering why I wanted to write an assembler. The problem is, I like to design custom CPUs (usually implemented in Verilog on an FPGA). These CPUs have unique instructions sets, and that means there is no off-the-shelf assembler. There are some table-driven assemblers that you can customize, but then you have to learn some arcane specialized syntax for that tool. My goal wasn’t to write an assembler. It was to get some code written for my new CPU.
You are probably wondering why I wanted to write an assembler. The problem is, I like to design custom CPUs (usually implemented in Verilog on an FPGA). These CPUs have unique instructions sets, and that means there is no off-the-shelf assembler. There are some table-driven assemblers that you can customize, but then you have to learn some arcane specialized syntax for that tool. My goal wasn’t to write an assembler. It was to get some code written for my new CPU.
For my first couple of CPUs I just wrote one off assemblers in C or awk. I noticed that they were all looking kind of similar. Just about every assembler language I’ve ever used has a pretty regular format: an optional label followed by a colon, an opcode mnemonic, and maybe a few arguments separated by commas. Semicolons mark the comments. You also get some pretty common special commands like ORG and END and DATA. That got me thinking, which is usually dangerous.
The Hack
The C preprocessor has a bad reputation, probably because it is like dynamite. It is amazingly useful and also incredibly dangerous, especially in the wrong hands. It occurred to me that if my assembly language looked like C macros, I could easily create a custom assembler from a fixed skeleton. Probably all of the processors I would target have relatively small (by PC standards) memories, so why not just use macros to populate an array in a C program. Then the compiler will do all the work and some standard routines can spit the result out in binary or Intel hex format or any other format you could dream up.
My plan was simple: Use an awk script to convert conventional assembler format code into macros. This would convert a line like:
add r1,r2
Into a macro like this:
ADD(r1,r2);
Note the opcode is always forced to uppercase. Labels take some special handling. When the assembler script finds a label, it outputs a DEFLABEL macro to a special extra file. Then it writes a LABEL macro out to the main file. This is necessary, because you might use a label before it is defined (a forward jump) and the assembler will need to know about them in advance.
The Result
Unlike a normal assembler, the output file from the script isn’t the machine code. It is two sets of C language macros that get included with the standard source code for the assembler. A driver script orchestrates the whole thing. It runs the script, calls the compiler, and then executes the resulting (temporary) program (passing it any options you specified). The standard source code just gets a buffer filled with your machine code and emits it in one of several available formats. You can see the overall process flow below.
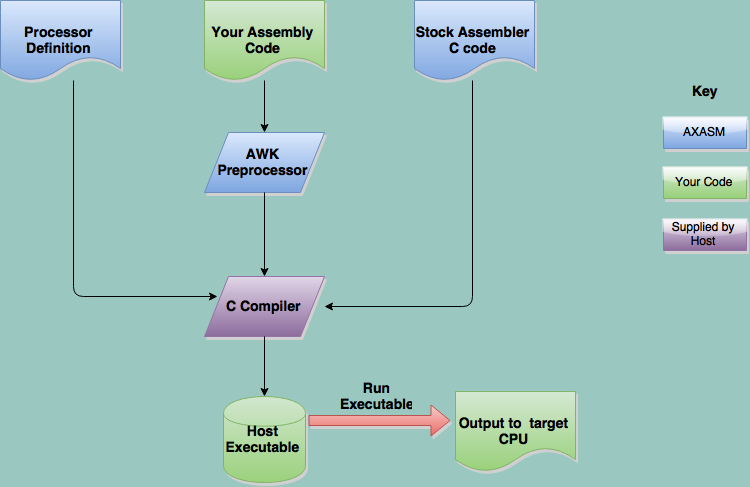
In case that wasn’t clear enough, the program generated has one function: to print out your specific assembly language program in machine code using some format. That’s it. You don’t save the executables. Once they run, they aren’t useful anymore.
The function the assembler uses to generate code is genasm(). The driver calls it twice: once as a dry run to figure out what all the label values are and the second time to actually emit the machine code. The genasm function is created out of your assembly code. Each processor definition has an ORG macro that sets everything up, including the genasm function header. The END macro closes it off along with some other housekeeping.
Configuration
The key, then, is configuring the macro files. Since the script converts everything to uppercase, the macro file has to use uppercase opcodes (but the program doesn’t have to). As I mentioned, you have to somehow generate the genasm function, so that usually takes an ORG and an END macro. These usually set up a fake address space (none of my processors have more than 4MB of program storage, so I can easily just make an array on the PC). Then I will define one macro for each instruction format and use it to define more user-friendly macros. The ORG macro also has to set some configuration items in the _solo_info structure ( things like the word size and the location of the machine code array).
Because ORG sets up things one time, you can’t use it repeatedly. That means I usually provide a REORG macro that just moves to a new address. Sometimes a hack requires a little compromise, and that’s one right there.
As an example, consider CARDIAC. This is a simple computer made out of cardboard that Bell Labs used to offer to schools to teach computing back in the 1960s (you can still buy some and I’ve recreated it in an FPGA, too). Here’s part of the ORG definition for CARDIAC:
#define ORG(n) unsigned int genasm(int _solo_pass) { \
unsigned _solo_add=n;\
_solo_info.psize=16; \
_solo_info.begin=n; \
_solo_info.end=n; \
_solo_info.memsize=MAXMEM; \
_solo_info.ary=malloc(_solo_info.memsize*_solo_info.psize); \
_solo_info.err=(_solo_info.ary==NULL)
The address is n (the argument to the ORG statement) and the program size is 16 bits. Right now the begin and end of the array is also n, but that will change, of course.
The __setary function loads machine code values in the array, and other instructions use that macro to make them easy to write:
#define INP(r) __setary(_solo_add++,bcd(r)) #define LOD(r) __setary(_solo_add++,bcd(100+(r)))
Because CARDIAC is a BCD machine, the bcd macro helps create the output numbers in the right format (e.g., 100 decimal becomes 100 hex). That’s not very common, but it does demonstrate that you can accommodate almost anything by writing a little C code in the definition file.
Running
Once you have your assembly language program and a suitable processor definition, it is easy to run axasm from the command line. Here’s the usage message, you’ll get if you just run axasm:
Usage: axasm [-p processor] [ -H | -i | -b | -8 | -v | -x ] [-D define] [-o file] inputfile -p processor = processor.inc file to use (default=soloasm) -D = Set C-style preprocessor define (multiple allowed) -H = Raw hex output -i = Intel hex output -v = Verilog output -x = Xilinx COE format -b = Binary raw (32-bit only) -8 = Binary raw (8-bit only) -o = Set output file (stdout default)
The -p flag names the definition you want to use. The program can output raw hex, Intel hex, Verilog, Xilinx COE format, and raw binary (use od if you want to convert that to, say, octal, for the 8080).
What’s the Point?
It may seem a little strange to pervert the C preprocessor this way, but it does give a lot of advantages. First, you can define your CPU instruction set in a comfortable language and use powerful constructs in functions and macros to get the job done. Second, you can use all the features of the C compiler. Constant math expressions work fine, for example.
You can even use C code to generate your assembly program by prefixing C lines with # (and preprocessor lines, then, have two # characters). For example:
##define CT 10
# { int i; for (i=3;i<10;i++) LDRIQ(i); }
That will generate LDRIQ instructions with i varying from 3 to 9. Notice the for loop doesn’t wind up in your code. It is generating your code. You can even define simple opcodes or aliases in your program using the preprocessor:
##define MOVE MOV ##define CLEAR(r) XOR(r,r)
Naturally, since AXASM works for custom processors, you can also define standard processors, too. Github has definitions for the RCA1802, the 8080, and the PIC16F84. If you create a new definition, please do a pull request on Github and share.
I’m not sure I want to suggest this hack as a general technique for doing text processing. Like dynamite, it is powerful, useful, and dangerous all at the same time. Then again, like a multitool, it is handy and it gets the job done. If you need a refresher on the C (and C++) preprocessor, check out the video below.














Wow! Like…
I’m still trying to get my head around it, but that is because I am so ignorant of C,
One of my early thoughts was… as AX-ASM (my hyphen) gets more refined will you change its name to
ChainSawAsm, TableSawAsm, BandSawAsm, and name a mini version HatchetAsm? B^)
Just please don’t change its name in honor of the ORG macro!
Rule 35
This:
##define CT 10
# { int i; for (i=3;i<10;i++) LDRIQ(i); }
Might be better as:
##define CT 10
##define LW 3 //lower range
# { int i; for (i=LW;i<CT;i++) LDRIQ(i); }
Or else why bother defining anything?
My bad! I changed that from a 0 to a 3 at the last minute just to be less boring. You are right, of course. The real code when from 0 to CT and I decided I didn’t like the zero in an example.
This reminds me TASM (table driven assembler). I used it to assemble Z80 sources to CP/M binaries on my CP/M computer, but also 6502 or 8080 sources for my old-cpu boards, but also 8051 projects. Different architectuers needed new definition table.
http://home.comcast.net/~tasm/tasmsum.htm
Very useful.
The author of that needs to find a better find a host for that website, since all “home.comcast.net” sites are going away soon…
Two pass assemblers were all the rage back in the day – it you didn’t have the right one for your processor, you could use MASM and a macro file to redefine the actual compiler directives themselves, which is sort of neat in a way. There also was a book out back in the early to mid eighties called “Universal Assembly Language” which described a generic set of instructions that would be converted using an intermediate macro replacement to define the topology of the processor (I sure there are many takes on that topic now). There was a lot of discussion back then about producing a product with base universal code and then compiling for the OS it would run on – so you could compile it for a MAC and then a PC, or a UNIX system, or a specific chip if you were doing embedded work. Of course they ran into problems, because most of them had hardware specific requirements that needed to be handled. A good example of this is the MAME32 environment for reproducing video game environments (if you don’t know about this open source product – go look at the source, it’s very cool stuff). It basically broke down the ‘closed’ blocks used (IO – Keyboard, joystick, disk drives, etc. and video, along with processor specifics) in video games – and was pretty close to being able to actually produce the ‘black box’ things need to run in, took the original ROMS from the original game itself, and ran it in this emulated system – almost a real processor emulator in true terms. I must confess, assembly was all I did for many years (since the product I worked on was a database written in assembly – 150,000 lines worth), and I still like it today – and yes, I have hand coded many processors over the years, may were radically different from each other in both their page addressing, registers, and their stack usage. Just ‘C’ heap usage is not a part of a dedicated embedded system (unless you write one of course). Now, it may be this is all foreign to most of you – this was a long time ago, when dinosaurs were coding software – and if you knew anything about anything – you were worshipped. Now a kid writes an e-mail bomb and people are impressed, makes me sad.
http://www.drdobbs.com/embedded-systems/a-universal-cross-assembler/222600279
Years ago, I used a universal cross-assembler called “PCMAC” written by Peter Verhaus. It used a macro language to define the nmemonics for the target processor.
http://peter.verhas.com/progs/c/pcmac/
It’s funny how programmers keep re-inventing stuff. I used Univac Meta-Assember on an 1108 back in the 1970s. I configured it for several different processors and used it productively to assemble code for them. I was surprised when a web search showed that it is still being used.
Ah Exec8 and…. CI I think? Bring me back. I did a lot of 1100 back in that same time frame but no cross compiled. That was all Avocet on Quasar QDP 100s in the early 80s.
Hi [Al Williams],
Most today don’t even use ASM, quite often the lowest level language people use is some derivative of ‘C’. So modern uC are optimised for assembled ‘C’ ie RISC type CPU’s as opposed to the CISC type CPU’s that many people that still assemble, started with.
So I have a question that I haven’t found an answer for and as you designs different CPU’s in HDL, I was wondering if there is some science or math or logic based way to evaluate a CPU’s total computational throughput ability as a function of analysing it’s instruction set. Is there some ‘ideal’ selection of logic functions (cmp, inc, dec, srl) a CPU can have that allow greater through put?
The only way I can think of to analyse this is to make several different complexities of state machines and use something like HDL synthesis to bring each of these to a minimum definition. And from the minimum definition convert these into assembly to run on the tested CPU designs. The amount of clock cycles to complete each state and state transition would indicate the CPU’s code efficiency.
A penny for you thoughts ?
I don’t know if there a universal way to quantify that, because I think it would depend on the task at hand. A video processor will have different needs than a database engine.
However, one of the things I’ve been very interested in, is a compiler that would take something like C++, evaluate it, decide that it would like to have 4 floating point units, 3 integer units, and 4 memory ports. Generate HDL for the “ideal” CPU, then compile the program for it. I’ve done a lot of work with Transfer Triggered CPUs because they would lend themselves to this very well but other than designing a TTA, I haven’t gone any further with that.
Good question, though.
That sounds a bit like some of the work our department was doing when I was an undergrad, and my final year project involved http://groups.inf.ed.ac.uk/pasta/ The basic idea is to automatically profile your target program to extract a CFG, then analyse this for bits of computation which are appropriate for generating specialised instructions, many of the ones detected are examples of common instruction set extensions e.g. multiply-accumulate, or parallel modulus/divide, but some applications will have more unusual features which make sense only within the specific application, like a random assortment of additions, shifts and subtractions, sharing some source registers and some constants. Now that you have these ISEs you need the compiler to recognise code patterns which can use them, and utilise them. This worked reasonably well in theory, but the CPU design was too limited in it’s memory bandwidth between the cache and pipeline (no direct memory access from the ISEs, so they had to be loaded into registers beforehand, and it only supported a single load per cycle). Compute kernels with a small diamond style data/compute flow worked well though, because the small data elements were leaded, they expanded into several intermediate values in-flight and kept in registers, then condensed back to a small number of stored values.
If I remember correctly a friend who tried to use the tools for encryption algorithms got good results, my attempts with the h264 algorithm were less successful.
@[Al Williams] I was more focused specificity on ‘computational throughput’ rather than ‘data throughput’. But to define even such a boundary (or distinction) would be in itself very difficult. I just read up on TTA and I will definitely be giving this a go in VHDL. It looks lake a small number of ‘config’ bits would allow a large range of custom instructions.
@[mm0zct] Thanks for the link. (PASTA) Very interesting reading.
I found this very interesting –
http://groups.inf.ed.ac.uk/pasta/papers/SAMOS10_JIT_DBT_ISS.pdf
The TLDR; is that their automated process: design CPU instructions, run simulation test, optimise, repeat –
was delayed by the very long times taken for gate level and cycle accurate simulation in a HDL synthesis engine.
So they create (on the fly) an instruction level cycle accurate *Interpreter* and greatly reduced the simulation time.
Unfortunately for me there is was no indication how one may find the ‘magic’ combination of instructions for optimum (general use) computational throughput. The processes used in the PASTA project are more like trial/error or successive approximation than pre-determination.
Thanks for the great article [Al Williams], I will definitely be trying my hand at TTA CPUs in VHDL.
[Rob] (sorry too lazy to find the diaeresis) — Have a look at: http://www.drdobbs.com/embedded-systems/the-one-instruction-wonder/221800122
Although it is in Verilog not VHDL
and
http://www.drdobbs.com/architecture-and-design/the-commando-forth-compiler/222000477
AXASM will handle the assembly for this CPU, btw.
[Al Williams]
Maybe the next step is the “High-level synthesis”?
http://www.ida.liu.se/~petel71/SysSyn/lect3.frm.pdf
http://www.xilinx.com/support/documentation/sw_manuals/ug998-vivado-intro-fpga-design-hls.pdf
Hi [Al Williams], these look very interesting but I got lost in the Verilog. I don’t think I will going as far with the ‘R’ of ‘RISC’ lol.
I’m off down another rabbit hole now looking for a good free Verilog to VHDL converter.
Obviously, instruction sets can be broken into categories, and some instructions take much longer to execute than others (usually math ones do…). If you look into what we used to call ‘micro-coding’ (I have no idea what it is called now), it is essentially the creation of another unique instruction for a given processor that is not part of the default set. In the day, manufacturers would create an instruction that only they knew the purpose of, which usually can be decoded eventually, but might take up way less code space or run faster than the equivalent code – but you get the idea. The actual process of fetching the instruction from the program pointer, and executing the instruction mask itself is interesting in that it defines the actual overlays that it performs. For example: you could create an instruction called ‘bob’, and it would overlay the accumulator on a processor with a value, and then shift the bits with ones of another register’s value of it’s choosing – kind of an encryption instruction. They did this stuff all the time, when you would try to decompile something, it would not decompile because of the micro-coded instruction, and you needed to find out what it did. Usually, they did this to save space or for security – since the instruction itself could have no parameters, or multiple parameters. But, it’s worth looking at the process to understand how an instruction actually works within the processor.
I’m asking this as an interested bystander… if you’re designing a CPU to fit a particular algorithm, why not just go the whole hog and use something like VHDL to do the whole thing in hardware? People use general purpose CPUs because computers do lots of different jobs. But for a particular algorithm wouldn’t there always be a particular hardware circuit that would be theoretically faster than software on a CPU? Given an identically performing set of gates.
It seems like the custom CPU + software is halfway between pure software and pure hardware. Is there a way of finding the ideal point between them? What should be dedicated hardware and what should be general-purpose, and how general-purpose, and what instructions it would need? How do you tell this? Is an automated way of working this out mathematically possible, or is it uncomputable?
Just asking out of curiosity, like. I’d just like a general sort of idea, don’t need specific answers to questions that might not be the exactly proper ones.
Synopsys (The CAE behemoth) has a tool like that (from an acquired startup) named ASIP that does exactly that.
AFAIK, it doesn’t decide on its own the CPU structure, but you tune the parameters and it spits out the CPU and the toolset for you.
https://www.synopsys.com/dw/ipdir.php?ds=asip-designer
wait… what about LLVM’s IR? it is well documented.
Are you suggesting translating IR to the target machine code? That’s what an LLVM back end does, right? But it isn’t really a cross assembler. A cross compiler, yes.
Its part of the compiler… but I’d argue that it is generic optimising assembler..
This does make me wonder if you could use LLVM’s ASMParser infrastructure (normally used for inline asm, etc) as a toolkit for making standalone assemblers…
I’ve seen a few posts about custom cpus but I have to admit that I don’t really understand what it’s all about.
Is it an exercise in doing something for the enjoyment/education of it, or does a custom cpu help solve a practical problem?
Don’t know about the others, but I built a few custom CPUs just for the fun and personal education. I can’t really think of any situation where it would be really needed to solve a problem. But once the situation arises, I’m ready ;-)
I have done commercial special purpose CPUs although most of the time you are as well off using a supported CPU and adding things to it. However, if you are doing research on new processor features…
You might want to check qhasm out.