
Inside every modern CPU since the Intel Pentium fdiv bug, assembly instructions aren’t a one-to-one mapping to what the CPU actually does. Inside the CPU, there is a decoder that turns assembly into even more primitive instructions that are fed into the CPU’s internal scheduler and pipeline. The code that drives the decoder is the CPU’s microcode, and it lives in ROM that’s normally inaccessible. But microcode patches have been deployed in the past to fix up CPU hardware bugs, so it’s certainly writeable. That’s practically an invitation, right? At least a group from the Ruhr University Bochum took it as such, and started hacking on the microcode in the AMD K8 and K10 processors.
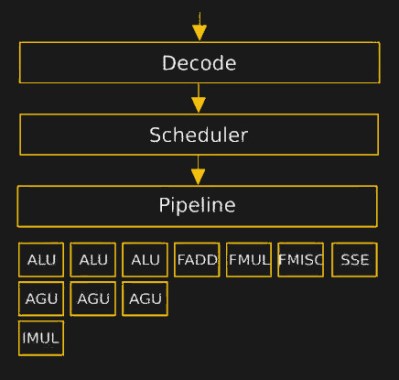 The hurdles to playing around in the microcode are daunting. It turns assembly language into something, but the instruction set that the inner CPU, ALU, et al use was completely unknown. [Philip] walked us through their first line of attack, which was essentially guessing in the dark. First they mapped out where each x86 assembly codes went in microcode ROM. Using this information, and the ability to update the microcode, they could load and execute arbitrary microcode. They still didn’t know anything about the microcode, but they knew how to run it.
The hurdles to playing around in the microcode are daunting. It turns assembly language into something, but the instruction set that the inner CPU, ALU, et al use was completely unknown. [Philip] walked us through their first line of attack, which was essentially guessing in the dark. First they mapped out where each x86 assembly codes went in microcode ROM. Using this information, and the ability to update the microcode, they could load and execute arbitrary microcode. They still didn’t know anything about the microcode, but they knew how to run it.
So they started uploading random microcode to see what it did. This random microcode crashed almost every time. The rest of the time, there was no difference between the input and output states. But then, after a week of running, a breakthrough: the microcode XOR’ed. From this, they found out the syntax of the command and began to discover more commands through trial and error. Quite late in the game, they went on to take the chip apart and read out the ROM contents with a microscope and OCR software, at least well enough to verify that some of the microcode operations were burned in ROM.
The result was 29 microcode operations including logic, arithmetic, load, and store commands — enough to start writing microcode code. The first microcode programs written helped with further discovery, naturally. But before long, they wrote microcode backdoors that triggered when a given calculation was performed, and stealthy trojans that exfiltrate data encrypted or “undetectably” through introducing faults programmatically into calculations. This means nearly undetectable malware that’s resident inside the CPU. (And you think the Intel Management Engine hacks made you paranoid!)
 [Benjamin] then bravely stepped us through the browser-based attack live, first in a debugger where we could verify that their custom microcode was being triggered, and then outside of the debugger where suddenly
[Benjamin] then bravely stepped us through the browser-based attack live, first in a debugger where we could verify that their custom microcode was being triggered, and then outside of the debugger where suddenly xcalc popped up. What launched the program? Calculating a particular number on a website from inside an unmodified browser.
He also demonstrated the introduction of a simple mathematical error into the microcode that made an encryption routine fail when another particular multiplication was done. While this may not sound like much, if you paid attention in the talk on revealing keys based on a single infrequent bit error, you’d see that this is essentially a few million times more powerful because the error occurs every time.
The team isn’t done with their microcode explorations, and there’s still a lot more of the command set left to discover. So take this as a proof of concept that nearly completely undetectable trojans could exist in the microcode that runs between the compiled code and the CPU on your machine. But, more playfully, it’s also an invitation to start exploring yourself. It’s not every day that an entirely new frontier in computer hacking is bust open.














“This means nearly undetectable malware that’s resident inside the CPU. (And you think the Intel Management Engine hacks made you paranoid!)”
Maybe history should have been economically different where FDIV didn’t cost money to fix.
FDIV was not a microcode problem. It stemmed from a separate PLA that was misprogrammed for one term of the lookup required in the Newton-Rapheson algorithm. Microcode existed in a separate ROM in the instruction sequencer, but in the case of the Pentium was not patchable.
The whole fdiv failure cost near to nothing for Intel.
In fact almost nobody send back their pentium for replacement..
I sent my P90 back.
No. Because linking the use of microcode to the bug is not only wrong but _very_ wrong.
Microcode is used in x86 because the architecture requires it (actually not but doing it in another way would still be similar). One example is the REP MOVSB instruction that moves n bytes between two memory locations.
In fact the 80486 aka i486 was the first Intel x86 processor moving away from using microcoding as the general decode/execute mechanism with simple instructions being executed directly while complex ones used microcode.
The Pentium bug was not in microcode but in a lookup table that was incorrectly pruned in order to reduce die area.
Why even bother making such a blatantly wrong statement, no CPU *requires* microcode in it’s implementation… even if it may be impractical without it. It just means you don’t have to live with the problems you might without it given the cost of silicon masks.
You can always just directly encode the sequencer as combinatorial logic and that is completely dissimilar to how it is actually done.
I love how security is finally shifting towards the hardware side of things. Without safe hardware, nothing else can be safe, yet the subject seems to have been neglected for a long time.
Unfortunately, the prevailing ‘solution’ seems to be “vendors should just cryptographically lock out everything they haven’t signed; because we all know that vendors are trustworthy, competent, and dedicated to supporting their products long after they would rather have you buy replacements!”
Depending on how readily exploited the prior standard of “nothing; but aggressively undocumented” security is; the zOMG Trusted Everything approach might be some improvement; but it has some rather nasty downsides.
Assuming “wisdom of the crowds” isn’t much better as 2017 demonstrated.
If they could write the microcode that handles the signatures without any bugs then they could just wire all of there microcode without any bugs so it would never need to be updated.
You do realize you’re talking about a single item out of a MUCH bigger system, right?
Also you can have bug-free code that’s a bit inefficient. Fixing that with microcode is cool with me.
I said that years ago and everyone thought I was crazy.
I wonder if they’ll stumble upon a few hardware based spying microcode routines.
I remember designing a ttl cpu in my late teens that stored all the microcode in loops of shift registers and could update them on the fly. Significant speed increase as opposed to simply decoding instructions straight from eeprom.
I know this is old but could you explain in n00b terms (but not too n00b, i understand ttl logic and electronics) how there was a speed increase in what in my mind is basically the same thing but one abstraction layer down?
Yup, I’ve been trying to think how you could make a secure system when you have no idea if the hardware is secure. I can only come up with a no. Also I have no idea if it’s even possible to make secure hardware.
Seems pen and paper is the best security. If someone has stolen the paper then the’re in your house and they have stolen everything and possibly killed you. LoL
There’s a good question–is totally secure hardware even possible? I personally doubt it. If data can be written or read by a person, then it must somehow also be possible for a different person to read and write data there. Unless quantum entanglement truly pans out in a big way, and I bet we’ll run across problems there too.
“yet the subject seems to have been neglected for a long time”
Most people are uncomfortable with the fact that all current platforms, that is, all desktop/laptop/netbook PCs and all cellphones/tablets are compromisable by design in a way that there is absolutely no way to make them secure by software alone. So most people either negate the problem or minimize it sticking their heads into the sand. Honestly I can’t blame them for that.
Link is down ?
the 68000 had microcode, before the 286!
This picture shows a type of microcode as well, for the IBM360, circa 1968.
The title is “fig130.jpg – Read-only storage unit and card. [CE installing 1401 emulation microcode on S/360 model 30.] ”
http://www.beagle-ears.com/lars/engineer/comphist/c20-1684/fig130.jpg
via http://www.beagle-ears.com/lars/engineer/comphist/c20-1684/
Yes, and System/360 before that… But microcode where generaly in ROM and can’t be updated after the production…
And the PDP-11 had microcode before that (going back to the late 1970s at least). It is a forgotten concept that has just been rediscovered with new applications and new possibilities.
On a positive note, if there were enough registers, local cache, and non-interruptable time available, one could theoretically design PKI functions in to single atomic instructions for the CPU. Note that encrypt and decrypt engines are commonplace even in many microcontroller CPU functions. So if you could trust that the instruction decoder couldn’t be updated, then you’d have reason to hope that your key management, encryption, and decryption, engines wouldn’t be tampered with.
Of course. It used a two-level microcode design.
The microcode concept was invented by Maurice Wilkes of Cambridge University (UK) and was first implemented for Cambridge’s EDSAC 2 in 1958. It goes back a long, long way!
https://amturing.acm.org/info/wilkes_1001395.cfm
Complexity means insecurity, apparently.
Because you can hide a lot of rubbish in a complex system.
Yeah it is like discovering the all of the “junk” DNA in your cells is not actually random and really encodes complete separate lifeforms other than “human”.
i think i’ve seen that episode of star trek…
I think most junk DNA is long repeating sequences, not very information-dense. And the way life evolved, it probably is just rubbish.
Actually, the entropy value for non-coding sequences is lower than coding sequences. In a strictly technical sense, they contain MORE information than coding sequences.
One thing that “junk” DNA is likely involved in is packing DNA into the remarkably small space in which it fits, and unpacking it when necessary, for specific short sections. There are other regulatory functions as well that for redundancy reasons can’t be superimposed of coding sequences.
> Actually, the entropy value for non-coding sequences is lower than coding sequences. In a strictly technical sense, they contain MORE information than coding sequences.
I think you have this backwards. Less entropy = less information. A sequence of repeating symbols (e.g. “00000000[…]0000”) has very little entropy, and hence very little information, for example.
Note that this isn’t a demonstration of insecurity as such. Any system that is accessible physically should be considered compromised.
Why not just change the BIOS to do something? Why not change the OS directly or indirectly to do something? Why not user software?
Very interesting and informative and easy to understand. Me likey!
This is super interesting. This of course has a level of complexity that is reserved for nation-states and researchers. Honestly, I’m far more concerned about 0-day attacks that replace the firmware on SSDs because that can be used to compromise everything else without ever being detected.
can it still run doom (or quake, eg. non-GPU renderers) without popping up a bazillion xcalc instances ?
Yes. They use very specific values.
“Yeah.. Don’t stand in that corner using a shotgun to kill that specific monster.. It will pop up xcalc and just annoy you..”
It just means we need open source hardware that we can check. Particular any roms/programmable parts of the system also need to be open source. Plus cryptographic checksum that we can check to make sure the firmware is unmodified. From was what load onto the device or what we load on the device. Sure signed ROM/Flash memory does that, but they are also black boxes, and people can’t load new or modified firmware with out the manufactures graces since it would be unsigned. All you need to keep track of a hash to ensure no malicious modifications are made.
I don’t see a way how this could be done. You need to trust a silicon fab with your design. I guess you could x-ray and decap samples afterwards, but it shouldn’t be too hard to hide modification in the compex and layered designs. You could have the chip output the expected results and never know something was wrong under the hood.
Even if you program your own FPGAs with a softcore you don’t know what else is lurking inside that package.
If your silicon is being altered it means they have altered the masks from your design, It’s usually easier to inspect the masks than the actual to chip. You could monitor the mask being used in production. However, if your worried about altered masks it basically means state sponsored or some one with deep pockets.
Honestly, I would be more worried about the the circuit layout of a finalized product being bugged as the process of doing so is much simpler altering an existing silicon design. Keep in mind changes to a chip design may effect yield so if yield so suddenly changes people are going to be looking at why.
If mask are tempered, which is very very very very unlikely, it won’t even pass the DFT test, so pretty much pointless…
I’ve always wanted someone to try and define a new instruction that just makes you RING0, but that’s got to be very hard to do.
SYSENTER?
https://www.theregister.co.uk/2015/08/11/memory_hole_roots_intel_processors/
https://www.blackhat.com/docs/us-15/materials/us-15-Domas-The-Memory-Sinkhole-Unleashing-An-x86-Design-Flaw-Allowing-Universal-Privilege-Escalation-wp.pdf
Ring0 is no longer sexy. Ring-1 and Ring-2 are the goals now. Running in the processor modes that take place before Ring0 are where you can hide malicious things without the OS being able to detect them.
Intel has been doing this to AMD for years with their compilers. You gonna hack it do it to Intel.
Temporary solutions include signed micro-code… That’ll be good for planned obsoletion as well, especially if Intel and/or AMD happened to conveniently “Accidentally leak” the private key, either because “they were hacked” or because they had “an insider” (Pun not intended).
The other idea is to have a speciffic sequence to fully activate “Micro-code upload mode” that can easily be catched by an anti-malware program…
For a start an instruction to begin the process of microcode upload:
mcupdmod #micro-code upload modethen have it require BX register to be zero before it and then have:
mov bx,ax # dump contents of bx into axand have that happen 8 times before repeating the whole sequence from the MCUPDMOD to the last MOV for a whole 8 times,
Then have the microcode to be uploaded (signed) and repeat the sequence above to confirm the upload.
That way an anti-malware could easily identify this chunk of code and if it isn’t from the Kernel or BIOS then could deal with the virus immediately, possibly even detect Kernel and/or UEFI modifications against known samples to detect tampering.
Additionally a hidden counter and internal salt/key could be used to verify all of the MOV BX,AX are in the correct order and detect the amount of times the sequence is repeated. Upon the exit sequence, the MOV instructions could be used to pass bytes at a time of the signing key from BX to AX and if any of the sequence is modified should invalidate the key because AX would have the old contents whilst the counter adds the garbage (previous data) to a key-register stack storage.
Further so any attempt at a user, kernel and/or malware reading either AX or BX during this sequence should cause the data to read FF in both AX and BX. Multiple attempts without running fault-checking interrupt routines should cause a platform reset (or halt), by the time the fault-tolerance routine is failed then the machine must already be in a very bad state and it is time to go to a safe haven
In x86 assembly, `mov bx, ax` transfers the value of `ax` into `bx`, not vice-versa.
Depends on the assembler. Intel syntax isn’t the only one.
“The result was 29 microcode operations including logic, arithmetic, load, and store commands” – then why not release K8/K10 as RISC processors featuring 29 simple commands?
Tech detail: AFAIK, there are more than 29 micro ops, but they’ve identified 29 so far.
The point: x86 assembly works for a lot of processors, even if they have different architectures. It makes code portable. After watching this talk, I have to think of x86 assembly as a higher-level language. It’s turtles all the way down. :)
Which is to say — you could run processor-specific micro-ops, I guess, and these folks have almost made developing something like that possible for one small family of chips.
And the micro-ops run from very fast on-chip ROM. To run them from system RAM would mean less dense code, which would be slower. Much slower.
That, and it’s likely the micro-code changes from one CPU type to the next, since it’s written to fit the specific CPU hardware. Which the user, ie anyone outside AMD, doesn’t need to know anything about. So you’d lose the compatibility which is the whole reason we have PCs in the first place.
“to run them from system RAM would mean less dense code, which would be slower” – not really; looking this way all RISC processor should be “much slower” than their CISC counterparts. While practice shows the opposite.
“you’d lose the compatibility” – of course I’m aware of this. Still it probably could be added by software, which would be slower than microcode-based solution, I agree.
I was just pondering, how much faster could be such “K8 RISC edition” than real K8.
Next you’ll be telling us the microcode is written in LOGO… Turtles indeed!
I guess it’s time for us to take a RISC and ditch x86.
So would it be possible to change the microcode to decode a different ISA ?
A 3.7 Ghz 6502 or 680×0 anyone?
Heard of the Amiga CPU-cards for the Amiga 1200 era?
Wouldn’t it be cool to have a 3.7Ghz (4.2Ghz turbo) emulated motorolla CPU with 256GB of RAM in an Amiga 1200?
(OK, I know… not possible, Intel management engine/AMD-FSP is required to set up the CPU, the main data bus would be incompatible: Intel quad-pumped-FSB and AMD Hypertransport, etc….)
The Nvidia Denver architecture is nearly there. it uses microcode in a different form: binary translation. The various optimization levels allow translation of the macro instructions (ISA) to internal control words (microcode equivalent). Right now it’s optimized for ARM, but there’s probably little preventing a 6800, 6502, or even X86 code base. Plus, it’s very fast. Neither AMD nor Intel have this developed to anything like this degree.
How does the Transmeta Crusoe compare to what you just described?
Nope. The reason for partially reprogrammable microcode is for fixing bugs which means there are n instructions that can be trapped to µcode. Those instructions are partially decoded by fixed function hardware that uses the x86 format.
The internal micro-ops are also designed to execute x86 instructions.
I have an AMD motherboard around with an option in the BIOS:
“Microcode updation: Enabled/Disabled”
I used to laugh at that perfectly cromulent word. I’m not laughing anymore.
TL;DR A programmable mechanism can be programmed.
Wow this brings back some memories from college where we had to projects with the PDP-8 microcode.
Well in this situation I think about what is already embedded there in the micro code (NSA CIA etc etc) …
A strong argument pro RISC, as long as that means that (nearly) all computation is done under the control or at least knowledge of the owner.
Furthermore, especially knowing of meltdown and spectre, a strong argument pro knowledge of the _very_complete_ hardware, not leaving details open which could become important later on (as, for the mentioned attacks are the (inexistent) stack segmentation and page protection or in the discussed area the very code execution flow details).
how to fix broken psp? mine is broken from installing windows 7 on a windows 10 only machine. i need help its effecting display driver and other things
Great work sir. Can I borrow your content for my new security blog? I will tag this website’s URL in the reference.
Eagerly waiting for your reply.
A deep dive into the Cell BE Processor on the Sony PlayStation 3 console, and why developers disliked developing games for the system despite its powerful architecture. i like it for building a bc cpu and gpu ram ssd mobo software drivers and better hardware designs for ai programming for game devs on consoles and on the pc and mobile devices in cpu and gpu and all other computer part hardware/software designs after fixing the uv lighting nano copper writing on the circuit boards and chipsets on the motherboards to tame the tdp/cooling issues here also improving port I/O.