
With more and more embedded systems being connected, sending state information from one machine to another has become more common. However, sending large packets of data around on the network can be bad both for bandwidth consumption and for power usage. Sure, if you are talking between two PCs connected with a gigabit LAN and powered from the wall, just shoot that 100 Kbyte packet across the network 10 times a second. But if you want to be more efficient, you may find this trick useful.
As a thought experiment, I’m going to posit a system that has a database of state information that has 1,000 items in it. It looks like an array of RECORDs:
typedef struct
{
short topic;
int data;
} RECORD;
It doesn’t really matter what the topics and the data are. It doesn’t really matter if your state information looks like this at all, really. This is just an example. Given that it is state information, we are going to make an important assumption, though. Most of the data doesn’t change frequently. What most and frequently mean could be debated, of course. But the idea is that if I’m sending data every half second or whatever, that a large amount isn’t going to change between one send and the next.
Compression
The most obvious answer is to use some type of compression. If you have the time to run a compressor on the data and then decompress it all inside your window, then that’s probably the answer — or at least part of it. The problem, of course, is that these programs take time to run. Another problem is that sometimes data doesn’t compress well and if you add the overhead of the compression, you might not get any reduction in data or it can even cause you to send more data.
I’m going to propose a very simple run-length encoding scheme for our system. It will treat the entire state array as a sequence of bytes. It will then send a bunch of packets that consist of a count and a payload. If the count is positive, then that’s how many bytes are in the payload and they are just copied to the output. If the count is negative, then the magnitude is one less than a count of the payload byte (that is, -1 is a repeat count of 2). I arbitrarily limit the repeat size to 256. A count of 0 marks an end of the state information.

As compression schemes go, this is pretty poor. My state array has 8,000 bytes in it (1,000 entries). If I use the compression algorithm on a random state array, it fails badly, taking about 10-12% more bytes to send than just sending the whole thing over.
The Fix
By now you are laughing and thinking what good is a compression algorithm that fails by 10% most of the time? But what if there was one simple thing you could do to fix it? In particular, the reason the algorithm fails is that not enough data repeats to make this compression worthwhile. Even if you use a “real” compression algorithm, they will almost always perform better if the data to compress has more repeating sequences. This is one reason why file formats that are already compressed don’t compress well — any repeating sequences were already removed.
So how do we get more repeating data? After all, the state is what it is, right? You can’t arrange for temperature and humidity and position data to all line up in repeating sequences, right? If you think of the array as fixed in time, that’s probably true. But if you start thinking about it in time, maybe not.
Remember how I said I’m assuming the state array doesn’t change much between transmissions? That’s the key. Here are the steps:
- Send the first state array compressed. It will probably be larger than the rest.
- Before sending the second state array, XOR with the previous one. Since not much changed, this will change most of the state array to zeros. Repeating zeros.
- Compress and send the second state array.
- Repeat for the third, fourth, and all subsequent arrays.
I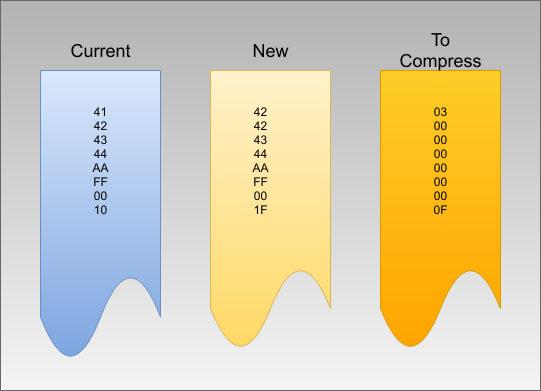 f you are used to using programs like rsync, this is the same idea. Don’t send everything, just the parts that changed. On the receive side, you simply reverse the XOR operation using the current state array. Even if you use another compression algorithm, changing your data to be mostly zeros is going to help the compressor.
f you are used to using programs like rsync, this is the same idea. Don’t send everything, just the parts that changed. On the receive side, you simply reverse the XOR operation using the current state array. Even if you use another compression algorithm, changing your data to be mostly zeros is going to help the compressor.
There are a few caveats, though. First, unless your connection is perfect, you need a way to tell the sender you didn’t get the last state update, so it needs to send a full array again. You could also add some overhead to mark when you send a full frame (and maybe send that uncompressed). You could also make the sender periodically send a full array to aid in synchronization.
A Simulation
To test this idea, I wrote a simple simulation you can find on GitHub. Since the sender and the receiver are really the same program, I didn’t simulate doing an ack/nack type handshake nor did I make provisions for resynchronizing. You’d want to add that in real life.
I wrote the simulation to use a test driver which — in a fit of originality — I named test. However, there are two test drivers, and you can select one by setting TEST_MANUAL to 0 or 1. When set to 0, the code uses two different sets of state data that you can set in the setstate0 and setstate1 functions. This is great for trying out a specific case for debugging. To keep things simple, I only populated the first four elements, plus the 800th element and the last element of the state array. This lets me keep debugging output short while still being able to tell that things work. The first four are just handy. The one at 800 shows that expanding data doesn’t get out of sync and the last one is good for catching corner cases where you overflow the buffer.
However, I also wanted to test on a broad set of conditions, so I wrote the other test driver. It randomly makes changes to the state array over 100 iterations (no more than 20 changes per iteration). You can supply a seed on the command line to get the same run of random values for testing.
In addition to a seed, you can prefix the seed with a caret (^) to suppress the XOR processing. If you don’t want to do the XOR, you won’t have a lot of runs in the data and your percentage will be very high — possibly more than 100%, indicating you sent more data than just sending the bytes in the regular fashion. For example, here’s a run that took almost 11% more bytes to send than normal without using the XOR.
alw@enterprise:~/tmp/state$ ./state ^143 TX/RX=8000000/8863392 (110.79) Done
With the XOR in place, the same run was at 2% meaning it was 98% smaller than the original data.
You can read the code to see how the above ideas are implemented. There are a few key data structures and functions you should know:
- state – The current state to transmit
- target – The current receiver state
- tx_prev – The previous state used by the transmitter
- rx_prev – The previous state used by the receiver (see below)
- receive – The simulated receiver
- xmit – The simulated physical transmitter (that is, all code that wants to transmit to the receiver calls this function)
- transmit – Send current state to the receiver
I debated about using the rx_prev buffer. This holds the previous state so you can XOR with the current data upon reception. However, you could XOR the data in place and save the buffer. The only problem is then you couldn’t use efficient calls like memcpy. Granted, even after memcpy you have to go do the XOR if you are doing the XOR at all. So it is probably as broad as it is long. If you were implementing this in a real system, it would be something to think about.
Both test drivers use memcmp to validate that the receivers buffer is the same as the transmitter’s. The random test driver also computes the percentage of data sent which is the bytes received divided by the total bytes sent times 100.
Limitations
As I mentioned, I don’t account for resynchronizing in the simulation. I also don’t do any integrity checking like a checksum or CRC. Those could be related in real code. It is easy to imagine a receiver computing a CRC, comparing it, and sending an acknowledge or a negative acknowledge. It would also be easy to imagine the transmitter sending some sort of sync header and flag to show that the contents are XOR’d or not. You could even use that mark to indicate the sent data is not compressed at all, which would allow you to send the initial reference state with no compression. That should make the algorithm even more efficient in most cases.
Results

The randomize function changes a random number of items on each pass, up to 20 at once. For 1,000 records that is a 2% change. Unsurprisingly, then, the amount of data sent compared to the data received is about 2% as you can see in the above graph. The correlation isn’t perfect, because the data is random, but in general, the algorithm will do well until so much of the state array changes each time that the overhead kills any benefit.
Still, many projects won’t have state that changes very often and this is a great way to send only changes. This works for any sort of data structure. However, as I proposed it, you could look at which topics have changed and work out a way to send only the changed topics. Note, however, that in my example, the topics are just more data and they change too so that would be harder in that particular case. My point is that there are many ways you could approach this problem.
Sometimes it seems like there is nothing XOR can’t do. There’s lots of compression tricks out there including squozing if your data can survive it.














“Most of the data doesn’t change frequently. ”
Lossless, vs lossy.
“Most of the data doesn’t change frequently (at all).” is lossless, “Most of the data doesn’t frequently change by a large value.” is lossy.
No. “Lossless” vs. “lossy” is whether the reconstruction is *precisely* equal to the source, or just [somewhat/nearly/almost exactly] like it.
Sounds like a rough equivalent of i-frames and b-frames in video. It does a good job overall, though you get the downside of having to weigh your desired bandwidth against your maximum allowed duration of inaccurate data (ie, how long you’re willing to go without sending an i-frame).
That’s the part I mentioned I didn’t show. If you might drop an i-frame (to use your words) you need a way to recover it. However, most real systems like this will have an ACK/NACK so you can always say after a NACK send an i-frame.
More like sending diffs, really.
Repeat after me.
Compression is :
* modeling, followed by
* entropy coding.
And the art thereof.
Well, keep in mind. I’m not really promoting the RLE compression scheme. My point to all this is that by doing the XOR between data frames — and assuming the entire frame doesn’t change each time — you wind up with a lot of repeating zeros that compress well using any of a number of compression schemes.
I found your method interesting, and would replace your compression with a Huffman encoding after the XOR.
Having only numbers, and most of them being zero, Huffman would make short work of it.
Yes, there is an endless number of ways to compress it. The key is having all the parts that didn’t change go to zero.
A roughly similar (in packet size) approach would be to simply have a header containing some bitmapped register indicating which pieces of information are being updated, and follow it with only those bytes.
There are many ways you could do this including tagging each element. Many many choices.
Similar to DPCM instead of PCM… instead of storing the absolute level at each time-slice, store the change from the previous value. Now a sine wave near the peaks looks like “…2, 2, 2, 1, 1, 1, 1, 1, 1, 0, 0, -1, -1, -1, -1…”. Huff-encoding works fantastically on this.
i am faced with this exact problem encoding a temperature series over time, and the XOR hack is just stupid enough i think i’m gonna use it thanks
that’s the sort of continuous data stream that can be processed with the 3R (recursive range reduction) compression algorithm I’ve been designing for a while now :-)
My favorite use of compression was this:
I was developing for an 8051 based device, that used a classic 8-bit parallel 128×64 display.
The worst part of the development was uploading, as it was done through a 9600 baud serial connection.
As the program binary reached 32k, flashing started to take considerable time and i decided i had enough and to do something.
I noticed that the display used only the 6 least significant bits in a byte thus wasting 2 bits per image.
I immediately thought about packing those bits, and then immediately changed my mind as who cares about a 20% compression… if i’m going to compress i have to compress above 50% (in theory at least).
What i ended up doing was using the 2 unused bits as an RLE counter.
This allowed me to pack up to 4 ‘raw’ bytes into one, allowing up to 75% compression, that’s more like it.
In practice the best compressed screen was ~50% and the worst ~30% so definitely better than the bit packing approach.
Although in the end i am not sure if i gained or lost time, that compression trick had brought me more satisfaction than the rest of the project.
one could regularly send a hash of the state table, to see if an update needs to be requested by the receiver.
Now my other favorite XOR trick is https://patents.google.com/patent/US9438411B1
The idea is simple: If your packet size << 256 then there are some bytes you aren't using in any given packet. So you identify a non-zero byte that doesn't appear in the payload and XOR that byte with all the other bytes. Then you use 00 as a start byte, followed by the "key" byte you used, followed by the XOR'd packet. This ensures that if you see 00 it is the start of the packet without requiring an escape byte (which causes the packets to be possibly different sizes each time).
There are variations. For example, if the packet has no 00's and you send the inverse of the key, you can skip the XOR and send FF as the inverted key (that means you can't use FF as the key either).
Lojeck's improvement to the algorithm is that if your packet size is much less, you can always pick the key byte from a set and use which set you pick from to identify the type of packet, further saving room since you probably had to send that anyway. In other words, say you have 10 byte packets. You select 11 keys and call that set A. Then you pick 11 different keys and call that set B. Say set A is 10-1A and set B is 20-2A.
Because there are only 10 bytes, have to be able to find at least one good key in each set. So if you see a packet:
00 15 ……..
That is an "A" packet with a key of 15
But if you see
00 29 ……
That's a "B" packet with a key of 29
Depending on the size of the packets, you can have several more types.
This isn't for compression, but it does mean you can get perfect sync if you know you always get a full byte with no overhead of a "sync pattern" or escape bytes/byte stuffing. It doesn't help if your communication channel cannot figure out where the start of a byte is, though.
Seems similar to https://en.wikipedia.org/wiki/Consistent_Overhead_Byte_Stuffing
Same reason for existing but the algorithm is different. In COBS you remove zero bytes and replace them with a byte count so you “know” the byte at the end is zero. And the size stays constant because you removed the zero and added the count. Then you get your added overhead in the way of a byte marker at the end and the initial pointer (2 bytes). The above algorithm converts the 0 in place but requires two bytes of overhead, same as COBS. However, if you can replace the type marker using the Lojeck improvement, that recovers your extra byte anyway — something you could not do with COBS. Well… maybe you could if you traded upper bits of the count for packet size which is sort of what the Lojeck does too. In other words, Lojeck packet ID doesn’t work if your packet is maximum sized anyway so I guess COBS could trade bits (that is, packet size <127 then 09 is an offset to the first zero in a packet but 89 is the same offset in packet type "B"). COBS claims one byte of overhead but it is because they don't count the 0 frame separator as part of the protocol So both add one byte plus the frame separating zero.
One of the minor disadvantages to COBS is that — at least conceptually — you replace a zero at the end of a subpacket with a count at the start of the subpacket, so the data in an implementation tends moves around with no particular pattern. With the XOR method byte 17 in the data stream unencoded is byte 19 in the encoded stream. And since the offset is at the front it is very easy to store byte 17 as byte 17. But you do pick up one extra byte of overhead and reduce the maximum packet size down by one, too.
Another advantage to the above algorithm is that you can use a slight modification to avoid doing any encoding or decoding in packets that do not contain the frame separator (which actually doesn't have to be zero for either algorithm, I think). For my algorithm, you do this by agreeing that the key is sent inverted. This makes 00 a legitimate key. If the packet contains no 0s, you send FF as the key which is really 0. An implementation can detect that and avoid applying XOR to the buffer or a naive implementation can XOR every byte with 0 which is fine, too. COBS isn't that different, I suppose. If you realize you don't need any zeros, your jump byte is 254 (or whatever your packet size) and you just skip everything.
So, like anything more than one way to skin the proverbial cat. COBS is one way. The key method is another. But the overarching result is the same (0 separates bytes; 0 appears nowhere else; fixed-sized packets with two extra bytes per packet in overhead). But the detailed results are not (homogenous processing of each byte in place plus a fixed offset vs special processing of certain bytes with bytes sliding around at decode/encode).
Not to say one is better than the other, just different.
To be fair, I think I’m also the one who figured out how to have non-zero start-of-message indicators. ????
(Considering how much of that patent was Al’s work, I have to hold onto my few contributions… ????
I can say, though, that in an FPGA, where we don’t always have the flexibility of memory assignments that a uProc does, that patent made “the program we worked on” really come together in a beautiful way.
Ah, I didn’t remember that but I’m sure you are right. Also, you are probably the world’s most experienced implementor of the algorithm ;-)
2nd place is likely a summer intern at Moog.
You know that’s the second time Buffalo has come up today.
A 64:1 compression rate can be achieved by using bit fields instead of “doubles” for acquisition/processing of discrete signals in systems based on matlab/simulink – and there is a hell of a lot of such beasts all around!
Sweet job, Al.
The tradeoff is often worth it, and of course if the main issue is the link BW and not the power use at the receiver end, you can sanity-check plenty…the link need not be bidirectional if “enough” key frames are sent for the application.
Soo… why is xor-ing rather than subtracting a good idea?
Fundamentally, you want to subtract. That’s the point: your data is mostly static, so the distribution of values is tight around some central value, but different central values. If you subtract off that central value (that’s what the xor is crudely doing), you’re starting to normalize the distributions. But a subtract really *does* start to normalize them (it gives them the same mean) whereas the xor takes the distribution, makes the most *likely* value 0, but the remaining values are all over the place.
As in, if your values fluctuate between 0 and 1, the xor fluctuates between 0 and 1. If they’re 1023 and 1024, the xor will fluctuate between 0 and 2047. If you subtract, both fluctuate between -1, 0, and 1. Even in the crude RLE encoding, subtracting should still have a minor advantage.
If you’re doing this in an FPGA, the xor might make sense, but in a microcontroller/CPU, there’s likely little to no advantage between xor and subtract.
I think it depends on the nature of your data. If you have a bunch of flags or bit fields the XOR will cleanly show what changed. The subtract won’t. If you have values that fluctuate a little you really doing a delta and that might have some value. It would be interesting to change the logic in the test code (ought to be simple) and see if there is any advantage.
The disadvantage is you get into signedness and borrows which I think complicates things. XOR on unsigned is “in place” there’s no carry/borrow generation. Realistically with this scheme if it isn’t zero it isn’t likely to matter that it is “close” unless lots of things are the exact same delta in a row.
You don’t really get into signedness — you operate on unsigned values and allow over/underflow.
And subtraction (delta predictor) has huge advantages if you use Huffman or LZ compressors. See also TIFF, PNG, PSD, etc.
The LZW patent has expired and it’s easy to implement.
LZW was the compression algorithm used in GIF that caused a patent fiasco resulting in PNG.
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch
Ah so it is pronounced penj
Couldn’t resist. They will never make me pronounce it jif haha.
There are two ways to compress this stuff –
1) within the one ‘packet’
2) across time
And you address both. However, I would guess that for most of the embedded programming stuff the best benefit would be across time – which you are doing with your XOR..
The trouble is that if you are doing across time (as per the comment above with video and i- and b- frames) the big issue how reliable the transmission is, how you know if you have every packet, how to request a new base packet if requires, or how (and if) to have a re sync period…
That’s where most of the work and fiddly stuff is, and in analyzing the data over time to see what the best encoding strategy will be (or indeed, to make it an adaptive one..) :-)
So the places I’ve seen this used in the past have all been where you have a transport layer that is handling things. For example, if I have two computers where one is trying to be a backup to the other and I have a TCP connection to them, then I know I’m getting the packets. I just want to minimize the amount of data going across the (possibly slow) TCP connection.
If you’re dealing with video, just go with MPEG. A pile of *real* experts worked for a long time on it, and it’s really efficient. In fact, it uses, one after the other, nearly every compression technique mentioned in these comments. Plus a couple more.
No, the comments above about I-frames from the other poster were just an analogy. This isn’t video related.
yep
That poor cat-bot does…not…want.
This is great, Al. I always like lightweight and clever over the typical “You know, this has been solved with Kalman filters”-type replies. BTW you were one of my favorite writers back at Nuts & Volts.
–Dan
Nice article. I’ve been trying to get my head around asymmetric number systems and this code is a nice example of an finite state entropy encoder.
Another approach is to send state information at times when the state diverges enough from the received value
rather than sending updates with regular intervals. These approaches are recently being investigated in the
community of information theory, you might want to check some research papers about the Age of Information research
such as:
https://arxiv.org/abs/1701.06734
http://www.ece.iisc.ernet.in/~htyagi/papers/PM-PP-HT-isit18.pdf
http://ece.iisc.ernet.in/~parimal/papers/wcnc-2017-2.pdf
https://infoscience.epfl.ch/record/224587/files/MG11_ARQ_Long.pdf
https://ieeexplore.ieee.org/abstract/document/7786178/
https://arxiv.org/abs/1806.06243
I didn’t understand a damm thing of this post but I came here looking for a way to compress realtime data from ISCSI server to guest device connection.
Any toughts on it?