In a world with finite storage and an infinite need for more storage space, data compression becomes a very necessary problem. Several algorithms for data compression may be more familiar – Huffman coding, LZW compression – and some a bit more arcane.
[Labunsky] decided to put to use his knowledge of steganography to create a wholly unique form of file compression, perhaps one that may gain greater notoriety among other information theorists.
Steganography refers to the method of concealing messages or files within another file, coming from the Greek words steganos for “covered or concealed” and graphe for “writing”. The practice has been around for ages, from writing in invisible ink to storing messages in moon cakes. The methods used range from hiding messages in images to evade censorship to hiding viruses in files to cause mayhem.

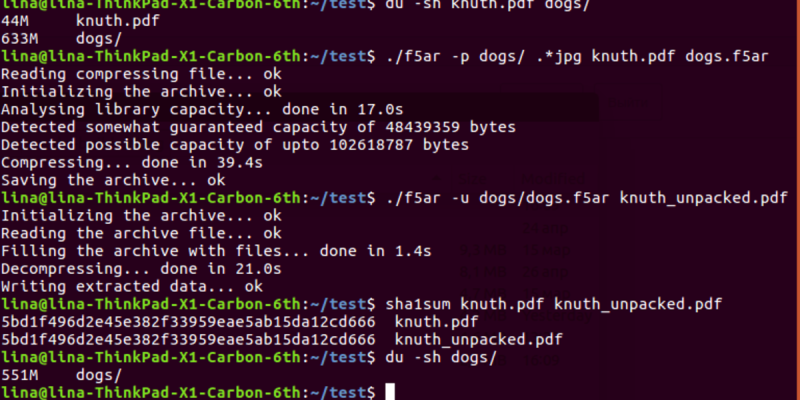
The compression technique they ended up implementing is based on the F5 algorithm that embeds binary data into JPEG files to reduce total space in the memory. The compression uses libjpeg for JPEG decoding and encoding, pcre for POSIX regular expressions support, and tinydir for platform-independent filesystem traversal. One of the major modifications was to save computation resources by disabling a password-based permutative straddling that uniformly spreads data among multiple files.
One caveat – changing even one bit of the compressed file could lead to total corruption of all of the data stored, so use with caution!













Re: the xkcd comic.
Sometimes PNG is warranted. Most of the time people try to upload their holiday photos as 20 megabyte PNG files. Also, good JPEG compression is indistinguishable.
It’s not about being indistinguishable, it’s about getting the maximum quality for the smallest file size.
Also, even if it’s indistinguishable you’re still destroying information. As the xkcd comic says, stick with PNG for logos/etc and JPEG for actual photos.
Data is not the same as information. If you can’t tell the difference, then all the relevant information has been retained.
The other complaint is “generation loss” where you lose data every time you save the file again.
https://www.youtube.com/watch?v=jjhomJ04S18
Well, turns out if you save a decent quality JPEG, it takes about a hundred generations before it starts to show up.
And, PNG does really badly with any sort of uncorrelated noise and random features. Anything that even _resembles_ a photo, like graphics out of a computer game, or screenshots in general, don’t really compress well. You will do better with JPEG and the result will be the same for almost all intents and purposes.
For example, scan a page off of a book. Which compression works better? Naive answer would be “It’s text, so PNG”. Try it. Do both, then compare results. The PNG file will be horribly bloated for no visible difference in quality.
If you do some very simple post-processing (enhance contrast to saturate white and black, posterize, etc) then the PNG file will be smaller.
scan a page off of a book. Which compression works better?
– TIFF..
OCR
I don’t know, for a logo, I would think SVG would be better than PNG. Since you can scale the hell out of it with no pixelation artifacts (or compression artifacts that you would get with a JPEG).
I always picture natural scenes with few high contrast sharp edges – Joint Photographic Experts Group (JPEG)
Man made artificial scenes with high contrast sharp edges – Portable Network Graphics (PNG)
Something that you want the ability to look well as say a 32×32 icon and equally well at lets say 16K resolution (15360×8640) – Scalable Vector Graphics (SVG).
I don’t know of any forums that accept SVG. The other image standards they do, usually JPG, and sometimes the others.
As an example, jpeg is really really bad at text and lineart in both quality and compression.
So it just stores the information of one file in the smaller fourier coefficients of many jpeg files? Its not exactly crystal clear from either this or the linked article..
Which raises the obvious question if that is the case, how much space would have been saved if he had simply compressed the jpegs harder?
Hey, great news! A new compressor with higher compression rates. And I can do even better, with a few lines of shell script. Faster, better compression, and guaranteed result:
#!/bin/sh
echo -n x > output.lossyzip
Output size won’t exceed 8 bit, even when feed with gigabytes of data.
Runtime is constant, even when feed with gigabytes of data.
There are only two edge cases: Zero-length input wastes 8 bit, and for some strange reason, if input consists of a single “x”, it won’t be compressed at all.
And unlike that funny tool, my compressor has a nearly 100% success rate at damaging data.
that comic is 100% _not_ from xkcd.
This looks like the author:
http://lbrandy.com/blog/2008/10/my-first-and-last-webcomic/
Exactly what I thinked….
The text in their medium post is painful to read, it looks machine translated. Could someone please sum it up in a few readable sentences in one of the common human languages?
Certainement…
C’est une forme de déduplication très compliquée et peu efficace.
Merci Jonathan, cela résume très bien l’article.
Merci!, C’est clair comme de l’eau de roche ;)
“One caveat – changing even one bit of the compressed file could lead to total corruption of all of the data stored, so use with caution!”
My kingdom for a correct bit.
My laugh for the day. It compares to the old 8 inch disks that would have a single read with a bad CRC and would fail the entire disk. Ahhh, the old days. But this new one gives fond memories of lost source and days of work – I can’t wait.
This technique is almost exactly identical to simply saving the JPEG at a lower quality factor, which (ta-da!) also makes the file size smaller.
The F5 steganography worked by decrementing the absolute values of DCT coefficients toward zero. That was meant to make it difficult to detect (although detection turned out to be pretty easy) but it also had the side effect of increasing the file compression at the cost of image quality.
So I am sorry, but what these researchers did is about the same as proving that water is wet.
It is not really the same – changes density is way smaller. But everything else is totally correct. This was just a fun and original (have you ever heard about something alike?) way of exploiting “water being wet” :)
Back in the day of dial up modems and faxes a company put out a really nice bit of software that was used to encode large documents and embed the data in to an image. You could then print the image, fax it to someone and they would scan it and use the application at the other end to retrieve the data. I played with the application a few times and it worked well, given the limitations that were imposed with dial up back in the day and the fact you were charged for data transmission and local calling was free we were able to send files this way at a fraction of the cost of sending the same file via email. It was made even easier when you had a modem that would handle fax and could send the fax directly so someone else.
IIRC is was around 1984 we were playing with this concept.
It was called “3D FAX”. Best results were obtained by using a FAX modem to send to another FAX modem so the transmission would be in clean 1 bit TIFF.
It’d still be useful to send files to places without an internet connection and without cell phone service. Could store all your word processing documents offline and impossible to copy via digital means, yet still be able to scan them in and make changes then print them back out as the 3D FAX images on paper.
after reading the above article, this reminded me of some bit fiddling I did some time ago while fuzzing monitors EDIDs ( mainly to alter existing data & update checksum, after reversing some code found online to extract said data – that is: manufacturing month & year, name, company name, s/n, .. )
For the steganography-inclined readers, here’s some fun: will you be able to decode the following ?
0x1d 0x0e 0x0f
hints: to make sure your decoding is right, decoding the followings should return the same stuff as “0x1d 0x0e 0x0f”
0x1c 0x0d 0x4e
0x1b 0x0c 0x8d
0x1a 0x0b 0xcc
0x19 0x4a 0x0b
0x18 0x49 0x4a
0x17 0x48 0x89
0x16 0x47 0xc8
0x15 0x86 0x07
0x14 0x85 0x46
0x13 0x84 0x85
0x12 0x83 0xc4
0x11 0xc2 0x03
0x10 0xc1 0x42
;p
Also, if someone has a hackety trick in mind to ‘store’ 2 numbers from [0..27] within one number of [0..255], don’t hésitate to respond :)
“The developer explains that since every file is just a bit sequence, observing files leads to the realization that a majority of bits will be equal on the same places.”
What the hell are they talking about? Yes every file is a sequence of bits but I have yet to find “that a majority of bits will be equal on the same places.”
It sounds more like they are talking about a revision control system that saves changes as diff;s
I find it hard to believe that the jpeg lossy compression engine would (1) be capable of giving you the data back out that you put in, and (2) work effectively on what is effectively random data as it counts on finding elements in pictures that are represented as data that it can simplify. It is tuned for a specific type of input. I suspect if you framed audio data so it could be fed through jpeg, the resulting file would not sound real good. I also suspect that if you framed graphical data and used mp3 to compress it, that it would not look real good. It would be interesting to see and hear, but while jpeg and mp3 do similar things as far as using lossy compression to make files smaller, I think they make different assumptions as far as what kind of input data can be simplified or scrapped. If I recall correctly zip for lossless compression had a few different tricks it could pull, some of them being file type specific.
That image isn’t from XKCD but is in it’s style. I tracked it down and it’s from here: http://lbrandy.com/blog/2008/10/my-first-and-last-webcomic/