
When talking about remote machines, sometimes we mean really remote, beyond the realms of wired networks that can deliver the Internet. In these cases, remote cellular access is often the way to go. Thus far, we’ve explored the hardware and software sides required to control a machine remotely over a cellular connection.
However, things can and do go wrong. When that remote machine goes offline, getting someone on location to reboot it can be prohibitively difficult and expensive. For these situations, what you want is some way to kick things back into gear, ideally automatically. What you’re looking for is a watchdog timer!
Watchdogs
The concept of a watchdog timer is simple. When attached to a system and enabled, the watchdog timer starts counting down from a preset time. The embedded system or computer is then responsible for sending a “kick” signal to the watchdog at regular intervals. This resets the watchdog back to its maximum time value, and it begins counting down again. If the “kick” is not received before the watchdog timer reaches zero, the watchdog reboots the system.
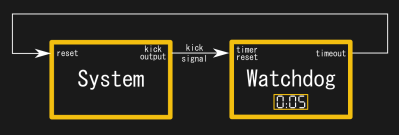
Getting the watchdog interval right is important. Set it too short, and a heavily-loaded system may fail to respond with a kick in time and an unnecessary reboot will be caused. Set it too long, and the system could be down for a significant period before the watchdog gets things up and running again. Careful analysis of the system and its proper behavior is needed to tune this appropriately.
It’s a handy way for dealing with crashes, kernel panics, and system hangs in a remote machine. Rather than having to send a technician out to hit the reset button, the machine can reboot itself when it gets stuck. Watchdog timers are crucial in applications where sending out a human could cost thousands of dollars, or even be impossible, such as in satellites and other space applications.
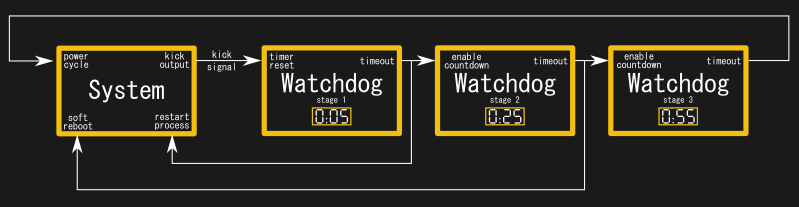
More complicated designs are possible, too. Multi-stage watchdog timers involve several timers cascaded in series. In such a design, when the first watchdog times out after not receiving a “kick”, it takes a corrective action and starts a second timer. If that does not rectify the situation, eventually the second timer will time out, firing a further corrective action, and so on, until all stages have fired. This can be useful for more complex applications. The first stage timer could institute a simple process kill command to a server, the second a software shutdown command to the OS, while the third could execute a full hard reset with a power cycle.
How Do I Implement One, Though?

Implementing a watchdog on a given system is highly dependent on the application in question. An exhaustive breakdown of specific watchdog designs is beyond the scope of this article. Instead, we’ll look at a couple of pitfalls, and outline a couple of different cases that highlight the varying scopes of watchdog designs.
Pitfalls
Note that these cases all refer to proper hardware watchdogs. Ideally, for maximum robustness, the watchdog should be an entirely separate piece of hardware capable of rebooting the main system of interest. Some microcontrollers and SoCs do include internal watchdogs that run with varying levels of independence, and these can be usable, too. However, they must usually be triggered appropriately by the main code loop. Using an interrupt to trigger a watchdog can be fraught with danger. The main loop can crash but as long as the interrupt still fires, the watchdog will never reset the system.
Also important to note is that “software watchdogs” are often anything but. For example, creating a process to watch other processes on a computer system can be helpful. It can catch a broad range of minor faults and issues and restart those other processes where needed. However, in the event another process crashes the whole machine, or creates a lower-level issue such as a kernel panic, the software watchdog will be helpless to act. Generally, a proper watchdog should be largely independent of the system it is monitoring.
Case Study 1: Home-Built Tank Monitor
Let’s say you’re deploying a homebrew Raspberry Pi project far from home to monitor levels in a few water tanks. It’s nothing mission critical, nor will it risk life or limb if the system goes down. However, the system is battery powered with solar charging, and you want to avoid having to drive out to reboot the system if there are issues when power levels get low or if something else causes a crash.
In this case, a simple solution can remove a lot of headaches without a lot of added complexity. Something as simple as an Arduino Uno or similar could be installed to implement a watchdog quite easily. The Raspberry Pi could be configured to send GPIO pulses or serial messages to the Arduino to indicate that it’s still running properly. If no signal is received in a set period of time, the Arduino could reboot the Raspberry Pi by simply cutting the power with a relay. This period of time can be minutes, hours, or even longer if the system isn’t critical. The trick is not making it too short, otherwise if the system is temporarily heavily loaded, the watchdog might time out despite the system not actually having crashed.
Having an Arduino in the system could bring further benefits, too. It could send commands to the Raspberry Pi to safely shut down in the event that the battery voltage starts getting low. Additionally, it could command regular soft reboots of the Raspberry Pi on daily or weekly intervals to head off any potential glitches in processes that could crash from running for extended periods.
I’ve implemented similar systems on mobile robots out in the field, and they can work surprisingly well. It’s important, however, to make sure that the watchdog operates correctly. For example, a primary process on the Raspberry Pi could get stuck without bringing down the whole system. If the watchdog service process responsible for signalling the Arduino is able to keep going independently, the system will remain powered up despite the fact that the main process is no longer working. The way around this is to have the watchdog service check that other processes are running properly prior to sending the kick signal to the external watchdog. If you’re writing all your own code, this is easy to do! Checking whether other programs are running properly can be harder, however. This is where regular pre-emptive soft reboots can be a sneaky workaround. For homebrew stuff, it’s often good enough.
Case Study 2: Remote Pump Controller
When machines are allowed to take actions on their own, rather than merely reporting data, things can get more complicated. For example, imagine a system responsible for controlling water pumps to fill tanks from a dam or other source. The system can be monitored and manually controlled over cellular data link, but otherwise operates independently, round the clock.
In this case, far more rigor may be needed to avoid disaster. If the system were to crash while pumps are enabled, the dam could be emptied, leading to the pumps running dry and causing expensive damage. Alternatively, tanks could be overflowed, or flooding could occur. Depending on scale, this could cause a mess in a shed or destroy crops, homes, and livestock.
Thus, a more rigorous watchdog must be implemented in these cases. For example, it may not be enough to simply reboot the pump controller in the event it stops sending kick signals to the watchdog. In this case, the watchdog may instead be configured to first switch the pumps to a failsafe off condition to minimise the chance of damage. The system may then be rebooted, and when back online, remote operators notified that a restart must be triggered manually due to the failure. This avoids the system simply rebooting and instantly failing again in the event that there is an ongoing problem.
In these cases, particularly where expensive equipment or even human lives may be at risk, a simple Arduino probably isn’t going to serve as a suitably reliable watchdog. Multiple redundant watchdogs may be required in some cases to provide a greater chance of stopping the system in the event of a failure. At the highest levels, code reviews and risk assessments will be required along with specially certified hardware across the board. But if you’re working on a watchdog system for a municipal-level dam or other safety-critical installation, you’re probably not looking up how to do it. If you are, please reach out to a supervisor or other official and tell them you need some help.
Summary
The aim of this article is to explain the basic concept of watchdogs, and why they’re useful for remote systems. Hopefully, the ideas presented here are enough to help you implement watchdog timers to improve the uptime and serviceability of your own projects. After all, there’s nothing cooler than being able to show off your rugged and reliable remote project to everyone at the Hackerspace. There’s also nothing worse than having your live demo fail because you can’t reboot a failed remote machine. Thus, get your watchdogs up and running and show off what a great hacker you really are!














Good information, thanks!
But I feel compelled to note that implementing a watchdog isn’t a hack — it’s engineering!
Funny, whenever I talk about my reading HaD to non-tech types, I refer to it as “one of my engineering sites.” I never really thought about it, but most of the hacks on here are actually engineering things. I enjoy both, and so HaD fits my needs/desires pretty well. ;-)
Not only are CPU watchdogs engineering, but classical. We used an external watchdog in embedded systems over 40 years ago, as the now venerable 8085 lacked one. Later, I rolled my own for the top dog 8051 in a 13-cpu telecommunications unit (A 2.048 Mb/s primary rate PCM multiplexer). It then supervised the other 12, as well as system vitality and transmitted alarms, reporting them to maintenance staff. So, an 8051 just for system monitoring, in turn supervised by a watchdog.
The integral watchdog in AVR microcontrollers handily reduces chip count, and is pretty easy to use, I find.
The primary gotcha is to not placate the watchdog in the scheduling loop or a task of secondary importance, but do it in a vital task or one which actively supervises the others.
In my experience I find that the newer processor internal watchdogs can be problematic and so I use external watchdogs as well. For whatever reason the newer processors I have been using are not nearly as robust as the ones of old. For the old processors their internal watchdogs were effectively subsystems that ran independently except for power… and for a mechanism to set up and tickle the watchdog. What was important is that once the older processor watchdogs were configured they could not be disabled… until the next power cycle. The new processors seem to be different and so there is a chance where rogue could disable internal watchdogs. These days I always, always use an external watchdog in conjunction with internal ones.
What you need is a variable watchdog that stretches in relation to the system workload, but that is indeed easier said than done. I’m theory one could implement a stand alone watchdog to listen to the rf from the processor and when it looks busy extend the timeout delay on the reset. Perhaps even having an additional override, so the processor can temporarily switch off the watchdog for certain tasks.
That seems to just add too much complexity – more points of failure that won’t ever recover from, especially if the processor can just switch it off – if it has to send a correctly encoded ‘secure’ message to request x (where x is less than critical time) extra watchdog timers before starting the long task it is almost alright, acceptable enough as incorrectly doing so or accidental shutting down becomes hard, but if its just the processor sets a bit/pin that turns it off outright and then it crashes the watchdog can’t function, because its off and was never reactivated…
I know it’s semantic, but “kicking” the watchdog makes me cringe inside. In all the code and documentation I’ve seen, you FEED the watchdog, you don’t kick it. You don’t harm animals, even if that’s just a name for them.
You have some interesting luck. I do see feed/pet/tickle on some recent articles, but kick was the original term and is still the most common by a large margin. Not that I like it any better, but claiming to have never seen it beggars belief.
20 years in the industry, and my gut feel is 99% is “feed the watchdog” if the text is in English.
This also makes more sens semantically. If you kick a dog, it bites back. I.e. it does the action you expect of the watchdog, but at the wong moment.
Whereas when you feed the watchdog, it will be content for some time. Only when you *don’t* feed it, does it activate.
In my case the metaphor is feed the watch cat.
I have on in real life for reference sake. If I don’t feed it every so often it starts meowing, gradually loud enough to break me out of any concentration loop I’m in, and eventually, if nothing else works, jumps up on the bench to hard reset whatever I’m working on.
Kicking a dog doesn’t necessarily harm it. See it as a little nudge to a guard dog that is about to fall asleep. As soon as the dog falls asleep the burglars come out. Or something.
The analogy is quite bad since nothing bad happens right away when a dog falls asleep, isn’t fed in a while or isn’t pet in a while.
People are too sensitive these days. Just be glad the term isn’t called “whipping the slave”. That would obviously be bad.
Now being liberal with dogs?
To me it’s yet another example of a large category of historical engineering terms that are insensitive, harmful, or violence-based. Terms like blacklist/whitelist (vs blocklist/allowlist), killing the parent/child (vs removing), master/slave (vs primary/secondary or source/replica), master branch (vs main branch or primary branch), war-room (vs situation room).
I find it ironic (and frustrating and sad) that parts of the engineering community that are so focused on innovation and change can also be so resistant to updating just a set of words to not be harmful or insensitive to others.
I have a project here for the outboard part of the watchdog that actually power-cycles the target.
https://hackaday.io/project/168150-reboot-o-matic
There is no need to implement a watchdog because dedicated devices already exist! One need only search “watchdog” on their part distributor of choice to find various kinds of watchdogs. They have some for voltage (low battery warning) and some are timers (automated reset).
They’re all good dogs, Brent.
I forgot to mention there are thermal watchdogs too!
It’s often cheaper to restart your service every now and then, than it is to isolate and fix your leaks.
A watchdog doesn’t only protect against software errors, such as leaks. It also protects against software crashing due to hardware errors, such as flipped bits in memory or errors with clocks/PLLs ( a windowed watchdog protects against the latter). Even perfect software can crash due to imperfect hardware or imperfect conditions.
A brownout detector can reset a target when the voltage dips to inform and/or reset the software before it crashes.
There’s another kind of watchdog type circuit that’s useful for things like heaters or pumps that have a problem if they fail in the *on* state. Make a simple one-shot timer circuit so that a pulse from your processor turns the device on for a small amount of time. If the pulse output locks in the high or low state, the timer turns off, failing safe. If your device can’t handle a rapid on-off-on cycle, add a second retriggerable timer that keeps the output on for a short time after the first timer goes off.
The processor can monitor the output of the timers to make sure everything is working properly. I would also use something like an opto-isolator to monitor the high voltage/ high current output to the heater or pump.
What an interesting article. I work so much with watchdogs on PLC’s for industrial products and alarms I never gave much thought to them conceptually. Overall a great article.
Noone suggesting a 555? I’m shocked! :)