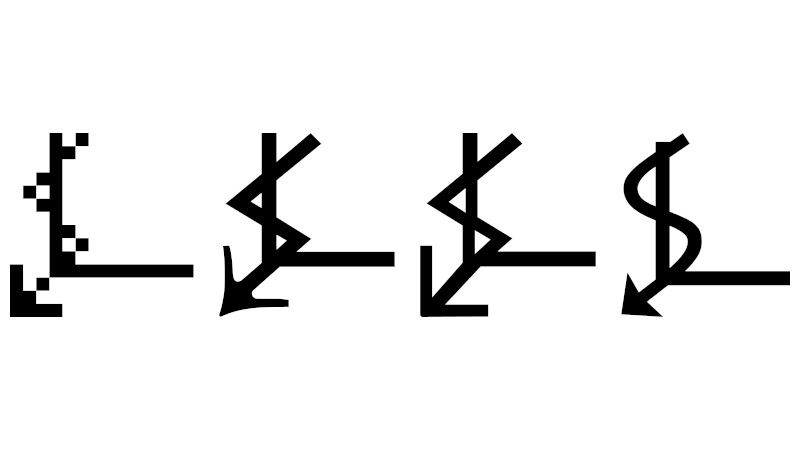
For anyone old enough to have worked with the hell of multiple incompatible character sets, Unicode has been a liberation; a true One Character Set To Contain Them All. We have so many Unicode characters to play with that there’s a fascinating pursuit in itself in probing at the obscure corners of what can be rendered on screen as a Unicode glyph. With so many disparate character sets having been brought together to make the Unicode standard there are plenty of unusual characters to choose from, and it’s one of them that [Jonathan Chan] has examined in detail.
U+237C ⍼, or the right angle with downwards zigzag arrow, is a mysterious Unicode symbol with no known use and from an unknown origin. XKCD featured it as a spoof “Larry Potter”, but as [Jonathan]’s analysis shows it’s proving impossible to narrow down where it came from. Mystical cult symbol? Or perhaps fiscal growth in an economy in which time runs downwards? Either way, when its lineage has been traced into the early 1990s with no answer to the question it appears that there may be a story behind it.
Hackaday readers never cease to amaze us with the breadth of their knowledge, ingenuity, and experience, so we think it’s not impossible that among you there may be people who will turn and pull a dusty computer manual from the shelf to give us the story behind this elusive glyph. We’d love to hear in the comments below.
Meanwhile if Unicode sparks your interest, we’ve given it a close look in the past.
Thanks [Jonty] for the tip.














I call it the LiteCoin Elliptic Curve Symbol
As to modernizing them, maybe lightening in its different stages.
Sin of a solid angle (in stradians)?
I look at it and can’t get out of my mind the idea that this is related to ‘whistlers’ and in particular, ‘helicons’.
My tutor at Uni was deeply into such things.
https://en.wikipedia.org/wiki/Whistler_(radio)
I think I found the meaning…
* The L stands for Logic. (Cos that’s so logical!)
* The downward zig zag for contradiction. (A contradiction makes your mind go zig zag into a downward spiral, sometimes insane…)
https://en.wikipedia.org/wiki/Contradiction
The downward zig zag is used as electrolysis symbol as well as for logic contradiction (but why?).
I guess someone wanted a more less ambiguous symbol for logic contradiction that doesn’t remind them of electrocution hazards, power man or electrolysis…
Its 42
That’s correct. Here’s another article: https://en.wikipedia.org/wiki/Proof_by_contradiction#Notation
High frequency traders be like.. I scalped your gamma
Well, maybe we can get the meaning from the context.
Unicode characters are added in groups.
2200–22FF are mathematical Operators
2300–23FF are Miscellaneous Technical
so it would be a technical symbol
https://en.wikipedia.org/wiki/Miscellaneous_Technical
going from the others around that, i would assume it is something in the same group or range.
there is also something like a “bell” or “square wave form” near that, maybe its for circuit diagrams in text form.
This is the prevailing hypothesis.
This is definitely the best prediction for the character yet.
I don’t like the bloated unicode coding scheme…
And me I don´t like red cars, and also pickled olives.
it might feel bloated and in some ways it is, but it’s designed for more than just regular usability it’s designed to be a universal coding scheme. if the character might have been used in a document, or an ancient manuscript somewhere it should be in unicode so everything could be saved in unicode format
All well and good, until they started including emojis.
Once you start using what are effectively bitmaps of objects, then you have to include all possible objects. US states petition to get their state bird as an emoji, emojis have become political (“gun” emoji and “poop” emoji and “pregnant man” emoji), and the list is never ending.
They should have stopped at 100 or so common emojis, used as emotional accents on text.
Emojis were originally ascii constructions, and unicode doesn’t even include all of these: there are ASCII emojis for “total recall” (NSFW), and zoidberg, which aren’t in the unicode standard.
The count of unicode characters is now never ending, as they add more and more emojis to the mix. (They’re now adding different color variations of emojs as separate characters.)
What’s the unicode for an image of Mohammed? e.g. (((:-{)>
Trans woman Mohammed? e.g. (((:-{)>8
‘They’ surely won’t approve of it. Existing emojis will have to be repurposed.
Afaik the colour variations are not seperate characters, but combining ones?
You might want to brush up on your emoji history there. Emoticon ala :-) started as ascii constructions, but emoji developed in Japan. With the text encoding schemes for the three Japanese text systems there was a bit of extra space for some bitmap images. Which is why the initial release of emoji included such classic american symbols like an onigiri or love hotel.
Different colored emoji are handled with zero width joiners combining the default glyph character and the color character, not as separate characters for each color instance.
Unicode needs to be never ending for actual linguistic purposes, people have been, and continue to develop new writing systems for languages that currently do not have a writing system. New languages will also continue to develop and writing systems will continue to develop alongside them and will need to be represented on computers.
It might feel bloated because it kind of is. It’s not made to be efficient it’s designed to be universal. Do you want to sent a text message with emoji, yep, do you want to archive a document from the 1980’s from some old character scheme that was abandoned, you got it, do you want to digitize an ancient manuscript found in a chest at the bottom of sea, probably, but if not they can add more to cover if
i don’t understand the objection. i think utf-32 is a negligible overhead for text…if you’re really warehousing vast quantities of text you’re probably gonna compress it anyways and i imagine gzip does a good job on content that is 3/4ths 0x00 in a regular pattern. and utf-8 is downright clever.
i just don’t understand a practical or philosophical opposition to it. i mean, in this comment i’m typing right now i’m not gonna use but 2^6 = 64 characters, but i’m still using an 8-bit encoding. such waste!
You’d hate the alternative mutually-incompatible standards mess even worse. Unicode isn’t bloated because it’s poorly designed, it’s bloated because supporting the sum total of human orthographic systems is an incredibly difficult task.
I tend to agree. If we could have left it with just the standard 0-255 . All would be good :) . It would be a ‘universal’ language if was left at that point. But no, had to ‘mess’ with it and add unicode :rolleyes: to complicate the heck out of it. Glad I don’t have to mess with Unicode in my programming world (other than deal with the headaches of dealing with functions and such that expect it) !
256 characters doesn’t even cover all the variations in the Latin alphabet – ISO 8859 has ten different variations of the Latin alphabet alone. Then there’s Greek, Arabic, Cyrillic, Thai, Devangari and Hebrew and you have a total of 16 different variations of ISO 8859, and they don’t even touch Chinese, Japanese and Korean.
Math is a language in and of itself, with it’s own alphabet/symbols. Add in Cree/Ojibwe/Inuktitut syllabics. For ancient languages you need heiroglyphics, hieratic, demotic, coptic, meroitic, phonecian, cuneiform, and runes, to name just a few.
65,536 distinct symbols is actually barely sufficient to handle human languages.
You’re missing the point. If ASCII became the worldwide standard, everyone would just use English and the problem would be solved. Software shouldn’t have to adapt to human inconsistencies when there’s an easy fix on the user end.
Ok, let’s test your hypothesis. Just start using a character set you don’t know but is everywhere, like wingings, and tell us when your easy fix takes hold.
You missed the /s from the end of your post.
You are being sarcastic, right?
you’re missing the point if computers were invented in thailand everyone would just use thai and the problem would be solved except for karen from comptability who already struggles in english and guess who would be the first to bitch about it yeah you. It’s so easy to say “everybody should use a language im familiar with and a charset im familiar with” but the second somebody tells you the most powerfull advancement in the entire human history is only reserved to people who speak a language that is wildly different from anything you’ve ever seen you’ll understand that this isnt a viable option.
Computers shouldnt adapt to their users we would use way less ressources if we used compact punchcards that only give you the information you need instead of fancy ass displays with 8,294,400 datapoints by frame 60 times a second its 1990656000 bites per second of wasted data that could be dots on a reusable piece of cardboard almost unreadable but im sure you would get used to it
just to be inclusive of autistic people the last paragraph was sarcasm
Someone tried to smuggle the Ellis sigil in there?
I had never ever heard of that symbol,
but a casual web search makes me think you are correct,
except for “tried”, apparently they succeeded B^)
The ellis symbol is from 2004
this is the only comment ive seen that actually matches 100%. i just searched it up, and it looks exactly the same, no argument.
why is this sigil even here-
I think it is supposed to be something like: https://image.shutterstock.com/z/stock-vector-stock-icon-on-white-background-flat-style-financial-market-crash-icon-for-your-web-site-design-1356471056.jpg
But the artist who designed the reference glyph misunderstood what was intended by “downwards zigzag arrow”
They also have that, as a different character:
1F4C9 – Chart Decreasing: 📉
It looks like the zig-zag used to indicate that something that can be inferred has been omitted to save space on the page, in combination with the bottom corner of a chart. I think it means “graph continues but is omitted for space”.
I just asked around and got a suggestion that it’s an outdated symbol for a lightning arrester in radio setups. This was from a long time ham operator and former (1970’s) Army electronics instructor which lends it some credibility, but that’s balanced by the fact that he wasn’t sure, he just knew he had seen it before in that sort of context.
This is the sigil of Ellis the linking sigil.
Reminds me of an architectural style wiring diagram.
Maybe (concealed) electrical wiring behind wall/ exiting wall?
FWIW, this glyph is not listed in my copy of the December 1990 draft Unicode 1.0 document. In that document, the page, titled “Unicode 2 3 _ _ Hex Draft 9/30” only has glyphs for 0x2300 – 0x233B. The other code points on that page (0x233C – 0x23FF) are empty.
https://math.stackexchange.com/questions/4424967/what-is-%e2%8d%bc-used-for/4426967#comment9267095_4424967 says it’s from economics.
You mean “some random person on the internet looked at it and made a guess as to what it meant”? Pack it up boys, nothing more to research here, we can just make stuff up!
Yeah, It’s my sign.
My favorite stack overflow answer, replete with unicode:
stackoverflow (dot) com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags/1732454
Read it and find out exactly why you can’t parse XHTML with a regular expression, and it will bend your brain if you try.
Hilarious.
Thanks!
Added to my list of favorite SCPs :)
For crying out loud, you mean to tell me that no one here has ever seen a schematic with a phase shunted flux recticitor?
Somehow it makes me think “into the page right hand rule” …
reference link https://charbase.com/237c-unicode-right-angle-with-downwards-zigzag-arrow
It means Unicode is screwing with us! :)
Incoherent ramblings about APL and bob’s your auntie.
You have obviously met my Aunty Bob Newton.
The APL didn’t fall far from the ttee there.
Somehow it makes me think of stray currents in large electrical installations, or railway electrification. But that’s an awfully specific thing.
Doesn’t everyone know that one? It’s Samuel L Jackson’s favourite symbol: snake on a plane
Since we’re all still in the guessing phase…
I would use it as an icon to depict a Von Leyden jar.
https://en.wikipedia.org/wiki/Leyden_jar
Your laptop battery is leaking (electrolyte [curved version] / electrons [zig-zag version]) into your backpack.
Stylized version (second from the left) — It’s so far gone that you now own a boat anchor.
Finally there’s a code for my brand, the lightning L !!!!! Amazing
Pfft it’s simple
It’s NFT market share and profitability
What about “Download graphics” ?
Personally we should leave all symbols to the symbol minded.
See George Carlin youtube videos
Half as interesting just released a video on this:
https://m.youtube.com/watch?v=cCoed5Oo_J4
When seeing it, I thought of the Bourbaki dangerous bend symbol. See:
https://en.wikipedia.org/wiki/Bourbaki_dangerous_bend_symbol
So my guess is that it means: “Dangerous square angle ahead!” LOL.
oh man you really dont know what it is. it is the LS Linking Sigil the power of Magick and The masses made it come TRUE UNICODE BEFORE SHE WAS CREATED really cool. search for it. LS Linking Sigil