Watching an anthill brings an air of fascination. Thousands of ants are moving about and communicating with other ants as they work towards a goal as a collective whole. For us humans, we project a complex inner world for each of these tiny creatures to drive the narrative. But what if we could peer down into a miniature world and the ants spoke English? (PDF whitepaper)
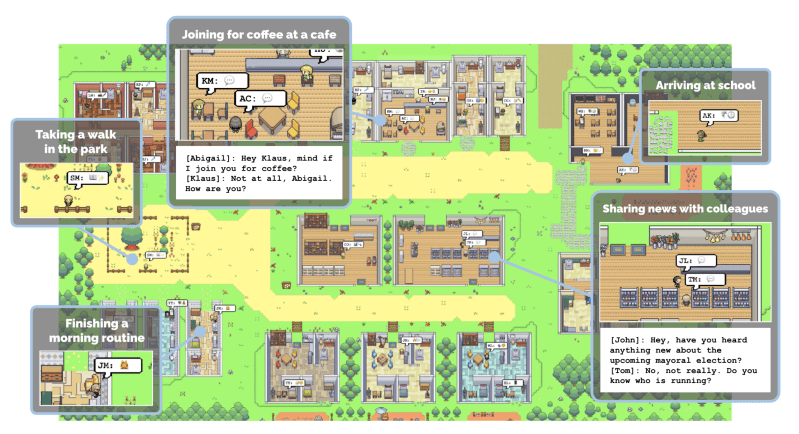
Researchers at the University of Stanford and Google Research have released a paper about simulating human behavior using multiple Large Language Models (LMM). The simulation has a few dozen agents that can move across the small town, do errands, and communicate with each other. Each agent has a short description to help provide context to the LLM. In addition, they have memories of objects, other agents, and observations that they can retrieve, which allows them to create a plan for their day. The memory is a time-stamped text stream that the agent reflects on, deciding what is important. Additionally, the LLM can replan and figure out what it wants to do.
The question is, does the simulation seem life-like? One fascinating example is the paper’s authors created one agent (Isabella) intending to have a Valentine’s Day party. No other information is included. But several agents arrive at the character’s house later in the day to party. Isabella invited friends, and those agents asked some people.
A demo using recorded data from an earlier demo is web-accessible. However, it doesn’t showcase the powers that a user can exert on the world when running live. Thoughts and suggestions can be issued to an agent to steer their actions. However, you can pause the simulation to view the conversations between agents. Overall, it is incredible how life-like the simulation can be. The language of the conversation is quite formal, and running the simulation burns significant amounts of computing power. Perhaps there can be a subconscious where certain behaviors or observations can be coded in the agent instead of querying the LLM for every little thing (which sort of sounds like what people do).
There’s been an exciting trend of combining LLMs with a form of backing store, like combining Wolfram Alpha with chatGPT. Thanks [Abe] for sending this one in!














Sounds like something to add to the Sims.
I’d like to see someone drop a Halo team into Sim City.
B^)
I like this new Pokemon game !
I definitely thought it was the gen 3 engine from a distance
I’m having “Little Computer People” flashbacks
The mode of thinking they’re simulating is known as opportunistic behavior. Rather than having internal thought processes, these software agents have stored information which combines with external information and cues to produce behavior.
It’s kinda like, when you walk into a room, and because of some distraction you forget why you went there. With your original intent missing, you stand there in the room and see a letter on your desk. You open and read the letter, you see it’s a bill, you know what to do with bills, so you open your banking app and pay the bill. You never planned or thought about doing that, but since you were there, and the letter was there… ping goes the pinball machine and the ball bounces towards the next interaction.
The LLM uses a statistical model which tries to predict the next logical step from the present situation, so it is exactly like this. If you’re in a bathroom, brush your teeth. If you’re in the car, drive to work, etc.
This is a good way to think of it, because the prompts to the LLM are always self contained “one-shots”, but they do try to account for the obvious failure mode of “I forgot why I came to this room! Oh well, I guess I’ll just “, and (hopefully) get the agents to maintain cohesive long-term personalities, plans, and routines by storing/including a self-image, goals, tasks, etc.
It also tries to provide all “relevant” memories to the current context, ranked by a combination of the age of the memory and other details like who/what/where from the memory.
There are also different types of small prompts that review/organize/summarize all these different internal details stored “in the agent”, which are called at different times as needed. Lots of small “introspection” updates like “summarize this conversation” or “break this goal down into tasks”, besides the main “What do you do next?” prompt.
The full paper on arXiv is very approachable, fairly math-light (if you understand basic ideas like “key:value pairs” you’ll be fine), and absolutely fascinating to read. The overall experiment is really a test of whether any of the techniques they try actually help create agents that feels “cohesive”, and they even try removing different subsystems to see the effect on the agents’ intelligence.
This is just the game Rimworld lol. Or Dwwrf Fortress
Urist McHacker cancels Debug: Job item lost or destroyed.
Urist McHacker is throwing a tantrum!
Somebody should script this into Stardew Valley; fans would have a field day.
Abigail is already there!
“The University of Stanford?” Do you mean Leland Stanford, Jr. University, AKA Stanford University?
Ants in a computer? https://discworld.com/management/wp-content/uploads/2014/10/Anthill-Inside1.png
Funny at first sight. Having read Zuboff [1], this sends chills down my spine. One step further into Skinner’s dystopia. But that’s Google’s (and Apple’s, and Microsoft’s, and Palantir’s… ) job.
[1] https://en.wikipedia.org/wiki/Shoshana_Zuboff#Surveillance_capitalism