Although Moore’s Law has slowed at bit as chip makers reach the physical limits of transistor size, researchers are having to look to other things other than cramming more transistors on a chip to increase CPU performance. ARM is having a bit of a moment by improving the performance-per-watt of many computing platforms, but some other ideas need to come to the forefront to make any big pushes in this area. This startup called Flow Computing claims it can improve modern CPUs by a significant amount with a slight change to their standard architecture.
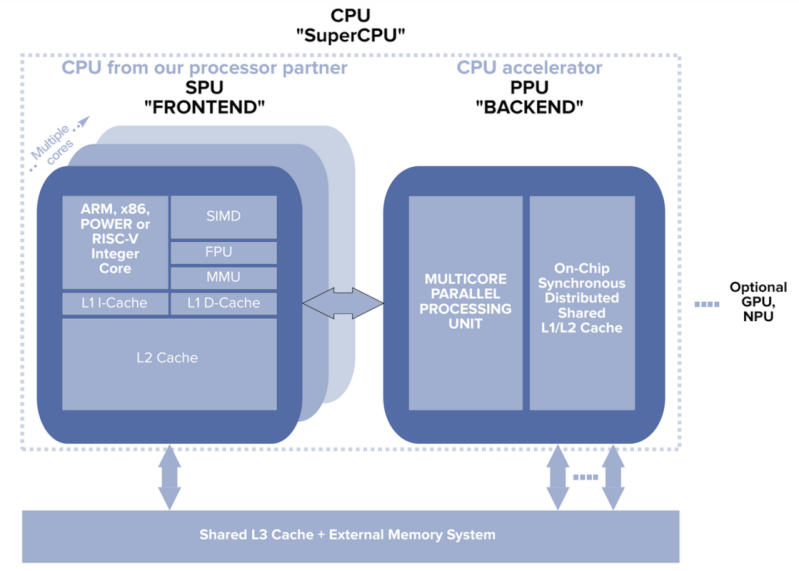
It hopes to make these improvements by adding a parallel processing unit, which they call the “back end” to a more-or-less standard CPU, the “front end”. These two computing units would be on the same chip, with a shared bus allowing them to communicate extremely quickly with the front end able to rapidly offload tasks to the back end that are more inclined for parallel processing. Since the front end maintains essentially the same components as a modern CPU, the startup hopes to maintain backwards compatibility with existing software while allowing developers to optimize for use of the new parallel computing unit when needed.
While we’ll take a step back and refrain from claiming this is the future of computing until we see some results and maybe a prototype or two, the idea does show some promise and is similar to some ARM computers which have multiple cores optimized for different tasks, or other computers which offload non-graphics tasks to a GPU which is more optimized for processing parallel tasks. Even the Raspberry Pi is starting to take advantage of external GPUs for tasks like these.














Not sure if vaporware or we have reached glorious times where small startups are actually working on new silicon
This sounds strangely familiar. Like we already have massively parallel co-processors that we offload calculations off to. By George, they re-invented the GPU. There may be a novel idea in there somewhere, and this is what we get after the marketing team and patent attorneys have worked on it.
Probably closer to the Cell processor in the PS3 but yeah this doesn’t sound like new ground being broken.
Agreed. Just need software, other than machine learning, that can use the GPU to good effect.
everything old is new again, we have just reached the point where transistor density means we have to split dies out again and such designs are back in vogue. big iron has had dedicated co-processors for I/O and parallel processing for ages, and it takes the form of a GPU either bonded on the same substrate or reachable via a fast bus on personal computers today, we seem to go through the cycle of nobody knows how to write compilers lets punt some of it into hardware over to the limitations of the physical compilers are holding us back, lets pull it out to software and back every other decade or so.
what would be useful, is generalising the concept so you could swap the frontend out for x86, ARM, PowerPC, VAX, SPARC, etc so you could run all the workloads you need without having to swap the hardware out.
> generalising the concept
This also already exists. AXI for example.
A high speed interface, to general peripherals.
Why design it, when you can buy out a company with a working version?
Isn’t this why AMD bought out Xilinx? And Intel bought out Altera?
Will we get any side-channel attacks with this new idea?
If it came with a “Turbo” button like my 386 had, I’ll buy it!
Their design is an alternative to GPUs for computing big vectors of floats. It does not help regular single-thread computing at all. The PR announcements and whitepaper are vague. The whitepaper points at many years of academic papers about their ideas. The most recent one
https://www.sciencedirect.com/science/article/pii/S0141933123000534
describes their current Flow Computing idea pretty deeply, beyond what I can follow.
They’ve run a prototype via FPGA. Until very recently it was just 3 researchers.
If the presence of this silicon on die or on-package leads to less L2/L3 cache capacity for the CPUs, that would lower the speed of the CPUs for all normal computing.
>Moore’s Law has slowed at bit
What does that even mean?
“The regularity that we observed earlier is not happening anymore, but we still talk like it’s happening”. Moore’s Law is a classic case of shifting the goalposts and still talking like the original assumption is descriptive of anything.
i guess i don’t understand what you’re saying? what’s the “original assumption”? moore’s law described an observed doubling in a certain measure of time. today, we can observe the same doubling but the time is longer. so people say moore’s law is slowing.
there’s a lot of things unaddressed by this observation, especially the fact that it may be slowing asymptotically in such a way that it should be described as ‘stopping’. but it seems to be true *and clear* as far as it goes?
If something is doubling, but the rate of doubling is constantly changing, then it’s not really doubling is it? You’re describing the phenomenon as 2^x but it’s really 2^f(x) or something else entirely.
It’s like saying, “I’m walking in a straight line – I’m just gradually changing my direction over time.”
Are you?
To be clear, everything that grows at least twice as big can be said to “double” – there’s nothing special about finding twice the original amount or number, and even if you don’t, you can always extrapolate a rate of doubling even where it won’t actually happen.
So, to “observe the same doubling” isn’t really saying anything. What’s important is that the rate is actually constantly changing, therefore Moore’s Law doesn’t apply here anymore. Moore’s Law is dead. Moore’s Law shouldn’t be used to describe the case because we know it’s going to make wrong predictions – it’s just using the wrong map for the territory.
You can’t keep a “Law” by continuously changing the constants to make it fit whatever data you happen to have. That’s nonsense.
You know how a magnetic compass points to a certain declination away from true north? And this corrective constant varies from year to year and from location to location, so if you planned to use one you should get a recent map of the area you plan to be in? It’s the same here.
The function (processor speed as a function of time) isn’t chaotic and it’s still fairly predictable. Speeds always increase over time, and each successive increase doesn’t generally add a fixed amount of speed, but instead improves the speed by a certain percentage. A series of multiplicative improvements (if we pretend the percentage was constant) is an exponential function, and 2^xt is the same function as 1.414^2xt, so if you’d like to base things on a doubling of performance instead of a sqrt(2) of performance, that’s entirely reasonable. Obviously, we’re agreeing the original function doesn’t hold anymore. But the character of the function is still fairly close, and if we stop for a moment and look at the real world it’s predicting, the statement about the law slowing makes even more sense. These processors come out in generations, and (ignoring paper releases and rebadges, which can come out just in time for sales cycles but don’t really mean much) they need to offer enough improvement each time that people want to buy the new stuff, even if it takes longer. So if we say the law is slowing, we may mean that the original function is still the right general shape, so that describing things as exponential can be an accurate approximation in a local region of a few years, but it needs to be adjusted to the current rate in order to stay close enough to be useful, and that adjusted rate is slower than the initially proposed one. The next better function may well be easiest to guess at by using the same x but making a function of t that raises t to some exponent a little less than 1, to represent slowing a bit over time. You could probably make a simple approximation for the magnetic declination too, which would be wrong, but would let you project forwards and backwards an approximately correct value for a greater number of years than the constant. Right now the north pole is accelerating past Canada out towards the Russians if I recall.
> It’s the same here.
Not really. It’s a different problem that has to do with what a “law” or a model means.
>The function (processor speed as a function of time)
That’s not Moore’s Law. It deals with the number of transistors on a chip at the most economical size (by process cost and yield) to manufacture. Moore predicted his original law to last for ten years, if I recall correctly, then after ten years he revised the prediction for the next period. At these times we weren’t nearly at the limits of manufacturing, so the observation and predictions were generally correct – things were progressing at approximately exponential rates. After that, things took a different turn and by the 90’s we hit diminishing returns, and Moore’s law was no longer useful – and it is at this point that people started making up different “versions” to fudge the point.
The point here is that the character of the original function is no longer fit to describe the underlying phenomenon. We can see that by the rate of chance of the constants that we need to adjust to make the prediction “work”. If we have to admit that the law is “slowing down”, it means we’re admitting that the constants have started to shift within the period of time that we’re trying to predict, which means they’re not constants and the model is missing something. In this part your North Pole analogy is more apt: as we get closer to the pole, the compass becomes less and less useful as a navigation aid because it’s pointing the wrong way. In effect, we need to know where we have arrived in order to figure out where the compass should be pointing next, and we have to keep correcting as we go using other points of reference like the sun and the stars.
If you have a law that “works” by tuning the constants as you go, then your model is actually in the function that defines these constants. That function may even fix a “law” that is entirely incorrect for the case and transform it into an different model, for example by turning exponential growth (Moore’s Law) into a linear growth (not Moore’s Law).
Fixing your model by continuously tuning the constants is a way of being “always right”. You can start with just about any assumption and then modify it as you go. Pretending that it’s still the same model has some clever name in the list of logical fallacies and scientific mis-thinking, but I forget what it was.
>That function may even fix a “law” that is entirely incorrect for the case and transform it into an different model.
An example of this. Suppose your model is f(x) = e^nx and you find that your predictions are overshooting, and you find that in order to make the prediction meet reality your constant n needs to be defined by a function: n(x) = ln(x)/x
Is this still an exponential function like you started with? No. If you simplify, it becomes f(x) = x. You can’t claim you’re still observing exponential growth when your actual model of it is really describing linear growth.
This is why you generally don’t try to “fix” your models by special fitting to data. When you keep changing the constants, you are performing this special fitting function that changes your original model into something else. You’re just fooling yourself by pretending that your original hypothesis was correct instead of abandoning the idea and trying to find out what’s really going on.
However, such fitting is useful when you are trying to find out what’s really going on, because by observing how you are changing the constants, you can find the actual model that you’re supposed to be using. It’s just that you can’t claim credit to the starting hypothesis, which is clearly incorrect.
Found it:
https://en.wikipedia.org/wiki/Simpson%27s_paradox
Basically, suppose we take individual 5 year periods and observe that within each period, we see exponential growth. We might conclude that we’re observing exponential growth all over. However, each five year period has a different rate of growth that keeps diminishing over time, such that when taken as a whole, we’re not heading towards infinity but some limit.
Each individual 5 year period so far may suggests “Moore’s Law”, but all the 5 year periods may actually reveal a logistic growth function, in other words, “not Moore’s Law”.
This is possible because the exponential function e^x has a derivative e^x while the logistics function has a derivative e^x/(1+e^x)^2 where for low values of x the dividing part (1+e^x)^2 is very close to 1. This is back when Moore made his original prediction. If e^x is small, then the derivative of the logistic function looks like the derivative of an exponential function and we may not recognize the difference just by looking at the data – but it will start to diverge.
When we say “Moore’s law is slowing down”, we are actually observing that divergence in the derivative and correcting for it manually by changing the exponential growth rate every few years. We are effectively performing a logistic function but calling it an exponential function by ignoring what is really happening.
Yeah, alright, you’re right that Moore himself went with transistors, but we already co-opted it to talk about speed a long time ago.
But part of this is that if the amount you have to modify the model is small enough to still leave it closer to its original form than any other pithy function, it may still be apt and we may not be fooling ourselves that badly. For instance, you said that if we corrected the model enough we could go from exponential to linear. I agree, but I think we’re way closer to exponential than linear, and so exponential is the better simplified approximation even if it isn’t the best final one. Though at some point the true variability of marketed products puts enough noise on the short term and the flaw in the model may end up with enough error in the long term that it does become worthless, it’s not that bad yet I think.
As to your second comment, I did say stuff relating to exactly what you’re talking about. I expressed in other words that we feel like it’s slowing down over time, and our revised constants may bear this out, and that as a consequence maybe we should revise the model in a way consistent with that. Admittedly when you want speed as a function of time and someone hands you an equation in terms of time raised to a fractional exponent, that’s undesirable. At least it’s compact and calls back to the original law, instead of replacing a “constant” with a function of time.
In the compass example, while you’re not wrong I’d use the example of if hypothetically the pole began to accelerate and become unstable to the point that a certain declination figure was only accurate for a few months and the next one was unpredictable and needed to be measured, that’s what would make things hopeless. Anyway we already know that endgame, we’ll run up against harder and harder problems for scaling, a simple example being that silicon is made of atoms, and I wonder how long we’ll go before the hard problems are all that’s left and no model blindly projecting forwards could possibly get it right, even if it had been right for every data point so far.
Okay, yes I can see some of that perspective, and can believe a logistic function may be apt for this as it is for other real situations. If we were without such a function as an option, perhaps for reasons of not being pithy enough, I would probably still go for exponential with bounds instead of linear or various others, but that’s a good point. I don’t think it’s perfect either of course, I don’t see us hitting a 100% complete limit like that, but still.
>I would probably still go for exponential
One effect of using exponential instead of logistic, or some approximation of it, is that you will under-estimate short term growth and over-estimate long term growth. It starts to look like we’re “getting ahead of Moore” with innovations that arrive earlier than predicted, but then stalling out towards the end of the predicted period.
>we already co-opted it to talk about speed a long time ago
Mixing up transistors and clock speeds and “performance”, and other poorly defined metrics by whoever happens to be talking, have really made such talk mostly meaningless. You lose your point of reference and ability to compare and predict entirely when you’re talking apples and oranges.
>it’s not that bad yet I think.
It started diverging in the 90’s – one reason being that we started reaching electrical power density limits with processors getting too hot to run. It’s at that point that other people started changing the metrics and measuring different things while still calling it “Moore’s Law”.
The issue is that Moore’s observations from before aren’t relevant to these new metrics, and mashing them together creates a fake trend that seems to extend all the way back to the 60’s. With this kind of “prediction”, we really don’t have any idea what is happening – just that people come up with new ways to add numbers on the chart.
“You can’t keep a “Law” by continuously changing the constants to make it fit whatever data you happen to have. That’s nonsense.”
I wish someone would explain that to the Biden administration.
B^)
In politics, it’s important to measure whatever you can measure, and ignore whatever you can’t measure, because what you can’t measure your opposition doesn’t know either, and can’t fault you for it.
Then, for what you can’t measure, you pretend that it doesn’t even exist, so you can claim to know everything.
The “backend” described here is more or less how SIMD units are implemented already. They share the CPU cache and some of the other resources, and run semi-independently thanks to out of order execution.
I think that there are so many interesting question in this whole area.
What if you had 1024 CPU’s (32×32) ,how about 10,2400 CPU’s (320×320), or 10,240,000 CPU’s (3200×3200), or 1,024,000,000 CPU’s (32000×32000) how should you connect them, how would you have them process data. Would they all share access to the same data pool, or each have local storage to access and process different data. How would they update each other, how many data buses or network links between cores or clusters of cores. Would there be one or more data buses, how about address buses, or control buses. Would the data flow in one direction only a TX only link, a RX only link (data diodes, or unidirectional networking). Would all data travel with forward error correction (ECC). What about security, would cores have to authenticate with each other, to validate authorization for access to data and leave an audit trail. Would packets of data traveling along dynamic links be more energy efficient than dedicated links that are always powered up but mostly idle.
I was hoping that the new startup referred to some famous OS being patched in some way. In the past 40 years my computer has gained a speed improvement of 3000x (from 1MHz to 3000MHz) and a memory improvement of 500000 (64kB to 32GB) but it it doesn’t feel my word processor loads much faster. I do have plenty of options to choose from, many options I never use, somehow the ribbon interface never worked for me, how is that easier than a dropdown menu of items. I ca read a word, but if I don’t know what a certain icon means, I’m lost completely. Most of the icons don’t even fit onto the ribbon, so I need to expand the ribbon with another symbol, it’s confusing. But then again, I guess it’s just me, getting to old for this .
The bottom line is that typing a letter on my old retro 8-bit machine is just as fast as typing it on a new “state of the art PC” (printing might be a bit slower and noisier though). Come to think of it, typing a letter on a typewriter might have been even faster, considering that it uses the print-directly-as-you-type technology. Come to think of it, it even has “emotion sensing” capabilities, as letters typed in an angry manor (hitting the keys hard) results in a much clearer/darker/deeper print. Come to think of it, I must still have such a device, hmm… I think I’ll be in the attic today, searching for it…
And typewriters do not print their serial number on every page, unless you choose to do so, much more private than a printer.
ref: https://en.wikipedia.org/wiki/Machine_Identification_Code
ref: https://www.eff.org/pages/list-printers-which-do-or-do-not-display-tracking-dots
ref: https://www.youtube.com/watch?v=izMGMsIZK4U
The speed a word processor works is basically down to your typing speed…
But yes, I know what you mean. My old MacSE/30 runs MSWord 6, to all intents as fast as O365 runs on my M2 silicon, and I think still saves to a compatible format.
There’s a number of reasons:
– things are actually faster. I remember loading apps off tapes and floppy disks. That was crap.
– they’ve added more stuff, which whilst not strictly functional, is useful. From better UI to auto-saving to the cloud, to spell/grammar checking, to hinted retina fonts, to larger screens. None are killer, you might not want them all, but they’re all there
– computers now do a lot of work to protect against attacks – from firewall to disc encryption to sandboxing to malware detection etc. plus just basic multi-user security stuff. Yes the threats are worse, but computers are a lot more resilient, and I can’t remember when anyone I know last had a virus.
– stuff isn’t necessarily as well written as it used to be. Cough electron cough.
> Cough electron cough.
Oh boy. Was helping my nephew put together a gaming rig a couple years ago. Despite it being no slouch, I could saturate an entire core just by holding down the spacebar in Discord chat.
I feel like we’ve trained at least a couple generations with a disproportionate focus on the Web, and so now we have the “everything is a web page” approach. When your only tool is a hammer, I guess.
i notice this same trend and it really bums me out. my android phone hardware keeps getting faster but most operations are actually slower (or MUCH slower) than the palm Vx i had in 2001. there’s a splash screen to amuse my eyes while i wait for google’s stock Clock application to load! every few years i run into a web browser innovation which leads to me typing faster than the thing can display characters on the screen, a real MS Word 6.0 flashback moment for me.
but there’s a counterpoint…if you use old software, like if you run Linux and use the same userspace programs you’ve used for decades, then the hardware really is fantastically fast! there really is progress, if you strip away the anti-progress.
My trouble with the old menu’s versus the ribbon isn’t with the concept of menus but the fact that it takes longer to hover over a sequence of five different menu items than to just click the label that’s already on the screen. Often I want something whose key combination I don’t have memorized but which I am going to want more than once in a session, so having to go back through the tree every time is poor design. Of course, unintuitive icons with no text are no good, but usually that’s not what you have and you can hover over an icon to be told what it is.
You certainly have a point.
I guess that what’s intuitive or not is what you are already accustomed to and in the end the plain old hot-key is the best option for super users. The advantage with textbased menus was that the hotkey description (in many cases) was noted inline with the menu item. Allowing you to learn them by using them (without reading a manual).
The kind of architecture reminds me on the “Mill-CPU” witch I think was proposed some years ago here on Hackaday
https://millcomputing.com/docs/
Interesting to see that they are still progressing.
ref: https://millcomputing.com/topic/yearly-ping-and-see-how-things-are-going-thread/
Yeah, interesting. After such a long time I thought they gave up.
or just write faster freaking software.
Yeah, I was thinking they got the speed increases by cutting out the bloatware.
B^)
This reminds me of my seminary thesis of using multi-8051 system for distributeted PASCAL interpretor, whrere one micro – Orchestrator tasked others – Minions to interpret and execute commands in parallel. It did not work because of memory bus congestion. In the end I rather married my wife and dropped out of the college :-)
This again – co-processer speedup claims? The biggest slow-down problems in embedded systems are caused by greedy on-die busses like the ubiquitous Advanced Microcontroller Bus Architecture (AMBA) [1] and their myriad evil spawn. Then there are commutated multi-processor architectures that try to get around the slow on-die bus problem (DMA can help, but only if stand alone).
The Parallax Propeller v1 processor comes to mind.[2] I have a lot of experience with this commutating multi-processor on die chip. It is impressive – for the right application. To realize the advantage of the commutating multi-processor architecture of the Parallax Propeller v1 chip, you need to program in Parallax Assembler (PASM, which is fast but difficult to learn), not the native (and very slow but easy to learn) Parallax SPIN interpretive language.
There are plenty of other multi-processor chips and FPGA cores available out there that mimic this model. This subject has so many years behind it, a title like “Startup Claims It Can Boost CPU Performance By 2-100X”, just doesn’t ruffle my feathers – sorry.
Aside: Processor speed also involves moving data around as fast as possible. The concept of lossless compression in the data pipeline is important. Look at Run Length Encoding (RLE) for a start.[3]
* References:
1. Advanced Microcontroller Bus Architecture (AMBA)
https://en.wikipedia.org/wiki/Advanced_Microcontroller_Bus_Architecture
2. Parallax Propeller Version-1
https://www.parallax.com/propeller-1/
3. Run-Length Encoding (RLE)
https://en.wikipedia.org/wiki/Run-length_encoding
Need to push the processing into the ram. No idea how that would work. But we waste so much time pulling the info from somewhere else, do a little work on it, then put it back. Why not just take the tools to where the data is and work on it there.
The Picochip will have one last gasp!
We knew how to solve this problem in the 1980s with the Transputer which married a parallel processing architecture with a multiprocessing capability and an inherently concurrent language (OCCAM 2). At the time, you could put together a number of 20MHz Transputers could compute Mandelbrot sets in a few seconds.
It’s mind boggling how people are still working on inferior attempts to address the same problem while at the same time relegating the Transputer to near total obscurity.
https://en.wikipedia.org/wiki/Transputer
Isn’t that kinda like instruction pipelining and hyper threading is essentially?
I think the next big thing in computing will be a in-memory computing, memory being basically an block memory rich FPGA reconfigured on the fly according to the specific instruction being executed. Only the final results will be flushed into the classic RAM from time to time for later use.
I guess these guys did not read about the architecture of the CDC 6600 or CDC 7600. Seymour Cray built these systems before the staff at Flow Computing was born.