Buy a computing device nowadays, and you’re probably getting something that knows x86 or an ARM. There’s more than one architecture out there for general purpose computing with dual-core MIPS boards available and some very strange silicon that’s making its way into dev boards. lowRISC is the latest endeavour from a few notable silicon designers, able to run Linux ‘well’ and adding a few novel security features that haven’t yet been put together this way before.
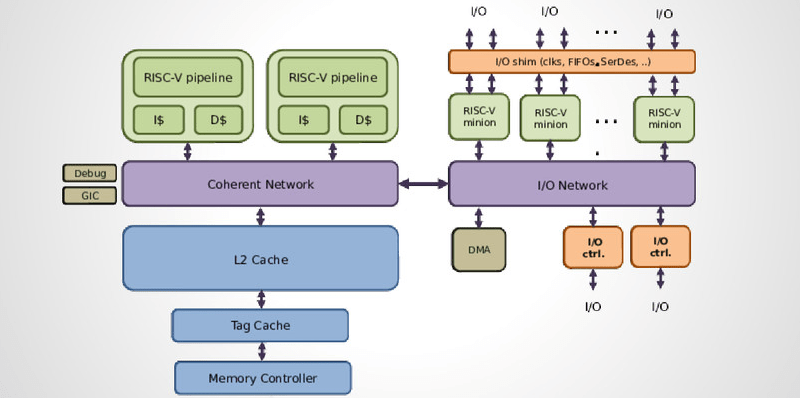
There are two interesting features that make the lowRISC notable. The first is tagged memory. This has been used before in older, weirder computers as a sort of metadata for memory. Basically, a few bits of each memory address tag each memory address as executable/non-executable, serve as memory watchpoints, garbage collection, and a lock on every word. New instructions are added to the ISA, allowing these tags to be manipulated, watched, and monitored to prevent the most common single security problem: buffer overflows. It’s an extremely interesting application of tagged memory, and something that isn’t really found in a modern architecture.
The second neat feature of the lowRISC are the minions. These are programmable devices tied to the processor’s I/O that work a lot like a Zynq SOC or the PRU inside the BeagleBone. Basically, they’re used for programmable I/O, implementing SPI/I2C/I2S/SDIO in software, offloading work from the main core, and devices that require very precise timing.
The current goal of the lowRISC team is to develop the hardware on an FPGA, releasing some beta silicon in a year’s time. The first complete chip will be an embedded SOC, hopefully release sometime around late 2016 or early 2017. The ultimate goal is an SOC with a GPU that would be used in mobile phones, set-top boxes, and Raspi and BeagleBone-like dev boards. There are enough people on the team, including [Robert Mullins] and [Alex Bradbury] of the University of Cambridge and the Raspberry Pi, researchers at UC Berkeley, and [Bunnie Huang].
It’s a project still in its infancy, but the features these people are going after are very interesting, and something that just isn’t being done with other platforms.
[Alex Bardbury] gave a talk on lowRISC at ORConf last October. You can check out the presentation here.














Sounds like something might be useful for IP/router type of applications too – tagged memory and Minions.
The core might be targeting beyond the $100 (or below) of FPGA eval boards. :(
yeah we remember cadrs and lispms too
“something that isn’t really found in a modern architecture.”
The death of the iapx432 and the rising of the x86 from its ashes is the biggest reason.
We could all be using nice secure systems if Intel had not decided to cripple their systems to run MS-DOS.
The x86 development was concurrent with the ‘432. It was a 16 bit stop-gap to allow intel to maintain a growth roadmap while the ‘432 was still being developed. The x86 was shipping while intel was still struggling to comlete the ‘432.
It was just an accident of history that x86 was adopted by IBM for the PC. Imagine how things would have been different had they gone with the 68K.
But we should honestly acknowledge how far the world has been able to stretch the x86. 20 years ago, many people were thinking that the x86 architecture would die within a few years, as it was not really a ‘clever’ architecture. I saw it as a brute force and unelegant. Well, I still see it as brute force and unelegant. But I think we have all been surprised at how far brute force can actually get you. :)
It’s a pity that Motorola was not able to maintain the elegance of the 68K and couple it with brute force. But I guess that the advent of high-level programming languages simply nullified the need for elegant instructionset architectures.
I feel fortunate to have worked on the Amiga and the CD-i, which used a 14MHz 68K processor. In that time, we did things with that CPU that was impossible on the x86. We needed to program certain things in assembly, to get the most out of the systems. But it was always a pleasure to do that. In contrast to having to program assembly routines on the x86… Argh, the horror of trying to create smooth animations with data that was larger than the segment size. :x
“But I guess that the advent of high-level programming languages simply nullified the need for elegant instructionset architectures.”
Surely, it’s the opposite. The sheer amount of x86 assembler code; partly due to the lack of decent 1980s compilers; largely due to the high-level inadequacies of the 8086 architecture pushed it to a 95% level market domination.
The x86 was built on binary/assembler level compatibility: 8-bit 8080 assembler code could be easily converted to 8086 object code; the original 8088-based IBM PC was too slow to support compiled languages well and the 8086 was a poor target for high-level languages, at least compared with the 68000. All of this contrived to put the 8086 into a dominant position, it was too much of a hurdle for people to shift applications to other architectures.
Consequently, the investment available for brute-force performance improvements on the x86 was available, but with only 5% of the market, this wasn’t possible for Motorola with the 68K.
High-level languages in themselves are designed to level the architectural playing field; the whole point is that you can retarget the code at different processors, because binary compatibility no longer matters. In addition, the whole point of elegant RISC architectures is that they’re *more* suited to high-level languages, because it takes less effort to write a compiler when you don’t have to deal with all the idiosyncrasies. This is why ARM, the world’s most popular RISC, can make major inroads into a number of different markets.
To sum up: The x86’s awful 16-bit design: terrible for high-level languages; terrible for accessing large amounts of data needed by businesses should have meant meant it didn’t stand a chance. But it won because of the pre-existing application investment in its 8-bit predecessor the 8080 and because in 1981, no one ever got fired for buying IBM.
As a side note, AArch64 also supports tagged memory, although I don’t think it has hardware-assisted bounds checking.
Hi,
ok, to demystify a bit: Things being around in x86 for quite some time:
“Basically, a few bits of each memory address tag each memory address as executable/non-executable,”
http://en.wikipedia.org/wiki/NX_bit
” serve as memory watchpoints”
http://en.wikipedia.org/wiki/X86_debug_register
Ok, given, these are x86 architectural features rather than memory address tags, but considering that any OS first of all enables paging on x86, the difference between tagging a page and a memory address is not very meaningful.
“It’s an extremely interesting application of tagged memory, and something that isn’t really found in a modern architecture.”
Well, unless you call virtual memory something modern. Then, a significant part of a memory address encodes things like access rights, and is checked by the CPU/OS on access.
The NX bit on x86 is not quite the same as memory tagging on the lowRISC. On x86, the NX bit and r/w bits apply to the whole page, while on lowRISC, tag bits can be used for every address.
I actually do agree; however, I really don’t see how that is functionally relevant on a modern system without significant changes in how OSes work; to illustrate: When asking for memory, your kernel gives you a 4KB page, and hands it over with a virtual address attached. You then use this address as base for your own processes’ operation. Tagging each address is not really helping much if the granularity of memory you can request is actually a page. I’m not absolutely sure, but I must assume that some aspects of the virtualization-oriented instructions on modern x86 kind of do that, allowing the supervisor to interfere whenever a guest requests a specific address, at least on a nested page translation level. If someone with a compiler and virtualization background would comment on this, it would be greatly helpful.
In fact, https://speakerdeck.com/asb/lowrisc-a-first-look even addresses the insufficiencies of the NX bit — but basically doesn’t explain why going from page to address (aka Byte) granularity actually solves this problem.
I see a lot of problems arise from this fine granularity; think of SIMD loading instructions, tag updates always thrashing the pipeline, SMP concurrency etc. However, if they can come up with a solution that is performant enough if working in a classical way, and allows for this high level of precision, that would be awesome. So far, this is highly developed vaporware, so I’m really looking forward to them releasing crucial parts of the
The idea of the tags is that before you call a function the calling function tag the returning address on stack to protect it from being overwritten which in turns make sure that no function being call can hijack the original program by overwriting return address. The NX bit only protect against a sub-class of this kind of attack.
The NX bit apply to page and is only meant to block attack which try to jump to code into data which content is under attacker control. This block a whole set of attack but not all of them. For instance attacker can still for return address to some know libc function with attacker crafted arguments. Which the tag per word can forbid.
That’s exactly it, thanks for clarifying.
Good and long awaited for MIPS, but the features enabled by memory tagging already exist in both x86 and ARM worlds. Buffer overflows still exist there; I suspect the same will be true on this.
Minions seem interesting. I’ve wanted Intel CPUs with such a thing for a while, but I wonder what the power/performance curve will look like on these.
Actually, the summary is a bit misleading. They don’t plan to use tagged memory to implement just NX, they want to use it to make efficient CFI implementations possible. That’s more interesting.
CFI (control flow integrity) basically means that arbitrary attacks which corrupt the expected call graph are detected at runtime, typically causing the program to abort. Those attacks could be buffer overflows, but they could also be ROP or integer overflows or what-have-you. The technique is interesting for just this reason: you don’t have to anticipate what your attacker will do, only know what they’re trying to accomplish. That’s a big potential win.
The lowRISC paper points out that this will involve compiler work, which is an understatement; essentially all CFI work today focuses on the compiler, and it’s an active area of research. Whether it will remain one when this ships is a larger question, as CFI implementations like those currently checked into LLVM have recently become quite performant. The overhead predicted by the lowRISC group anyways is in the same neighborhood as compiler-only work done recently by teams of researchers operating independently at Google and FireEye/Mandiant. Could this yield a performance edge? Maybe, but probably not enough to overcome Intel’s current performance advantage. Maybe power/ or price/performance will be better.
Good stuff.
wow – I missed this news. It would be great to get tagged memory back. It was super useful on the lisp machines and allowed FPU ops to be typed automatically so floats went through a diff process than ints when adding and casts were automatic. Goodbye to overlfow attacks as a side effect.
The extra tricks you can pull with garbage collection were great too. Many users machines were never rebooted and had very long uptimes due to the ephemeral and dynamic garbage collection system.
The Symbolics lisp machine had a 40 bit word of which 8 was tags.
I’ve been waiting for years for someone to implement this.
There is another RISC-V (or Cortex M3) based project, where a smart multicore solution enables virtual peripherals. Check this out:
https://www.indiegogo.com/projects/arduissimo-reloaded-multicore-cortex-m3-arduino
Just to clarify the concept of tagged memory: the memory address is used to look up both data, and this extra metadata (the tag). Reading a 64-bit word would actually result in 66 bits (a 64-bit data word and 2-bit tag). The tag cache logically extends the word width from memory to 66-bits to accommodate this.
This is a different idea to using some bits of a memory address to encode information about the value being pointed to. Commonly, some of the least significant bits are used for this. As whitequark mentioned, AArch64 specifically allows the most significant 8-bits to be ignored in address translation so they can be used arbitrarily for user code.
Those “minions” remind me of the peripheral processors on old CDC mainframes.
Come to think of it, this system will probably have about the same level of raw processing power, if it gets into silicon.
Or we could stop putting data on the stack.
Or we could stop using memory-unsafe languages.
Why the fuck anyone considers continued use of C acceptable is beyond me.
because this is embedded, and OOO/functional programming is too abstract for low level stuff. In C you look at the source and you know how the machine code will look like.
Hahahahahaha.
Let’s try it with some very simple code. For example:
void x(char *restrict a, char *restrict b, size_t c) { for(int i = 0; i < c; i++) a[i]=b[i]; }
So how will the machine code look like? Describe all possible results in rough detail.
memcpy?
mov al,byte ptr [esi]
add esi,1
mov [edi],al
add edi,1
sub ebx,1
jnz loop
I dont see the point of even writing that :/ You dont need all possible machine code variations, you need exactly one that you can be sure of when debugging.
Whats so funny? that you are unable to account for compiler optimizations in your head? Discount optimizations and think lower level.
Well, there are at least eight realistic variants that could be translated, not counting the various decisions the code generator may take when vectorizing the loop. (jump/call to memcpy, loop by byte, word, loop with SIMD, last three backwards) All of them have different, sometimes wildly, behavior with regards to performance and side effects.
My point is that the C spec, which the compiler follows, has practically nothing in common with practical architectures. It specifies behavior of a C abstract machine, which doesn’t even have *stack*. As long as the behavior is identical modulo the C a.m., the compiler is allowed to perform any transformation it desires. You cannot possibly predict what the machine code will look like. Arguably, C is one of the most abstract languages when it comes to code generation.
In contrast, say, ocamlopt’s code generator (of a functional language!) is simple and predictable. The worst thing it could do is inline a function.
Anyway, the claim that OO/FP is somehow too abstract for embedded development is absurd. C++ and Rust are well suited for embedded, if they have other issues.