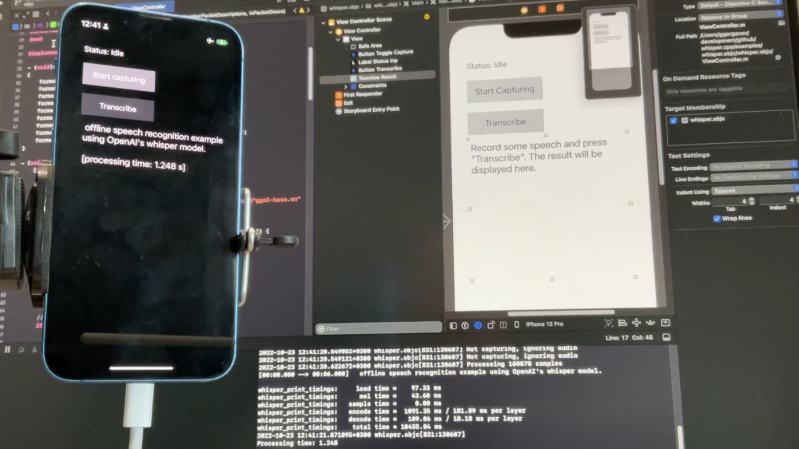
[Georgi Gerganov] recently shared a great resource for running high-quality AI-driven speech recognition in a plain C/C++ implementation on a variety of platforms. The automatic speech recognition (ASR) model is fully implemented using only two source files and requires no dependencies. As a result, the high-quality speech recognition doesn’t involve calling remote APIs, and can run locally on different devices in a fairly straightforward manner. The image above shows it running locally on an iPhone 13, but it can do more than that.
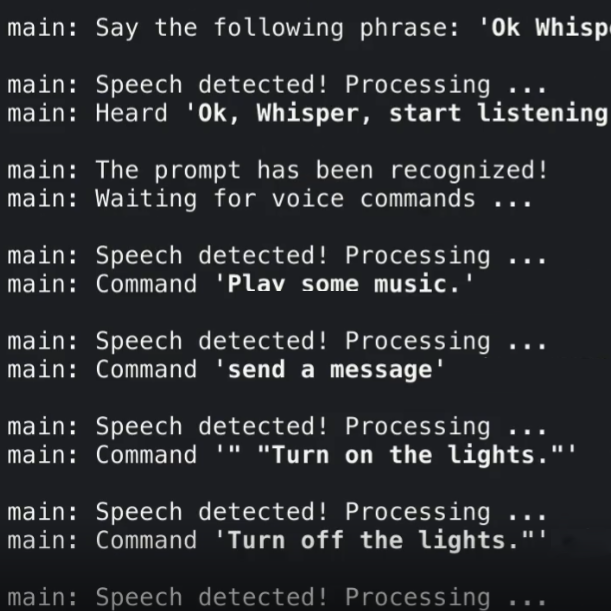
The usual way that OpenAI’s Whisper works is to feed it an audio file, and it spits out a transcription. But [Georgi] shows off something else that might start giving hackers ideas: a simple real-time audio input example.
By using a tool to stream audio and feed it to the system every half-second, one can obtain pretty good (sort of) real-time results! This of course isn’t an ideal method, but the robustness and accuracy of Whisper is such that the results look pretty great nevertheless.
You can watch a quick demo of that in the video just under the page break. If it gives you some ideas, head over to the project’s GitHub repository and get hackin’!














Local ! Yisssss…. now to dig out my IBM Home Director lol
Yeah, mine’s been buried for a decade or so…
I remember when some folks made AI that learned voices of polish voice actours from Gothic II game. Then they used this AI to dub very vulgar adult movies. Original voice actours go angered so hardly that they sued for damage and even got those poor nerds imprisoned for improper use of AI.
Thats a pretty impressive transcription – at least as good as I what I would do as a human, and a damn side faster!
That’s so awesome. I’ve always wanted a voice controlled computer assistant, but I will never, ever install some closed source, monetized, “we send everything you say to our servers” wiretap.
Maybe this technology has finally disseminated enough that that can be done without a PHD in artificial intelligence.
Check your pocket.
I assume you’re talking about a smartphone. If it’s “in your pocket” as you say, then it’s unlikely to be able to hear very clearly, especially with its constraints on bandwidth, CPU and ultimately power. I get your point but a smartphone is very different from Alexa or google home. Not to mention it’s still possible to walk around without a smartphone, or even a phone at all!
Works like a charm on Debian 11 running on an AMD Ryzen 7 5700G. I tested all of the examples and it was perfect, not a single issue. Many thanks to all those involved in the project.
Wish I could say the same for the AVX2 version running on an 8th gen core i7. Consistently 10x slower than the Apple ARM metrics given in the README. Real time dictation = forget it! Still a nice piece of work. Maybe it’s a sign I should switch to an M2.
Try building it under Clear Linux? That is Intel optimised. I forgot to mention I am using the 6.1.0-0-amd64 Linux kernel. Also play with the -t option I found 8 threads was optimal even when I have 16 cores.
Simple C libs and progs are the right way to make software. I’ll check this out.
Ingenious work ! Thank you. Great toy for further playing with.
Thats awesome! Thank you [Georgi] (and OpenAI) for the work & HaD for sharing!!
Ok, how long till it gets wrapped up for a python library :D
Would be cool compile this targeting WASM and then doing real-time subtitles on videos in the browser. Complete edge processing
yeah, please, a plugging for vlc or whatever should be perfect for people with hearing problems so they can enjoy their old family videos.
My mom could use this soo much
Great idea, but I don’t know about anyone else, but my family videos have a lot of people talking over each other. ;-)
My family home videos are super-8 films on 7″ reels.
How did you accomplish this? Do you have the code for this? I really need the code for understanding pov cause i have a minor project coming which is based on the same context model you have shown over here. Pls help me if possible