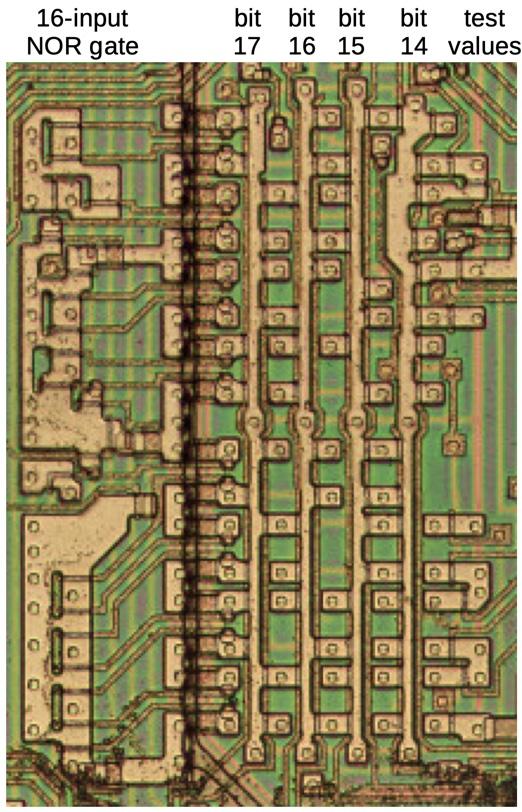
As simple as a processor’s instruction set may seem, especially in a 1978-era one like the Intel 8086, there is quite a bit going on to go from something like a conditional jump instruction to a set of operations that the processor can perform. For the CISC 8086 CPU this is detailed in a recent article by [Ken Shirriff], which covers exactly how the instructions with their parameters are broken down into micro-instructions using microcode, which allows the appropriate registers and flags to be updated.
Where the 8086 is interesting compared to modern x86 CPUs is how the microcode is implemented, using gate logic to reduce the complexity of the microcode by for example generic parameter testing when processing a jump instruction. Considering the limitations of 1970s VLSI manufacturing, this was very much a necessary step, and an acceptable trade-off.
Each jump instruction is broken down into a number of micro-instructions that test a range of flags and updates (temporary) registers as well as the program counter as needed. All in all a fascinating look at the efforts put in by Intel engineers over forty years ago on what would become one of the cornerstones of modern day computing.














I have “fond” memories of developing microcode for a made-up processor back in graduate school in the late 80s. With such training, you get a near close as possible understanding of bare metal computer processors. This was a bit easier for me given my EE undergraduate training. It believe it would be beneficial if a higher percentage of software developers understood what was happening at the assembly, microcode, hardware level of computers.
Driver and BIOS developers.
IMHO I am still employed at my advanced age because I studied all those down-in-the-weeds topics obsessively in my youth. My co-workers seem impressed, but my “secret” is no more complicated than having a fully internalized understanding of the basics.
That said, all that “deep underlying knowledge” is not enough. Another reason I’m still employed is being up to date on current techniques and technologies. For a guy who started out on PDP-8, 8008 and TTL logic, the modern world of computing is every day a grand adventure.
I missed the lab lecture on microcode 38 years ago, never really figured it out.
Reading [Ken Shirriff]’s blog has helped quite a bit (not that I understand 1/4th of it.
I’m a little late but the way my undergrad university courses present it is as a state machine. You have part of the microcode which represents the next state (hardware uses logic gates to flip 0s in the next state to 1s for branching) and the other bits are used as control signals.
You can see the state diagram: http://users.ece.utexas.edu/~patt/22f.460n/handouts/state_machine.pdf
And how it’s implemented in hardware: http://users.ece.utexas.edu/~patt/22f.460n/handouts/appC.pdf
All in all pretty interesting stuff
The sophistication of compilers, processors and their secret microcode make this an impossibility. However, it seems like new programmers are cranking out javascript code, so while depressing, there is another layer of uncertainty there. They seem to work under the auspice of having unlimited resources.
>It believe it would be beneficial if a higher percentage of software developers understood what was happening at the assembly, microcode, hardware level of computers.
*agree*
Maybe we would have less bloatware if people looked more at at least assembly. And it’s fun too! (sometimes)
(not saying one should code in assembly, but at least be aware of what the compiler really does with your single line of whatever high-level-language)
I can easily state that my understanding of assembly helped my career as a software developer. I even found a bug in the Borland C++ compiler when it compiled 16 bit code in a 32 bit environment. It actually changed the order of evaluation for when doing this evaluation (the code was crap, don’t misunderstand me) =>> array[number++].
Compiled on a Win16 the increment was evaluated before the array position.
Compiled on Win32 the array position was evaluated before the increment.
This would cause an array position error as some dummy set number
to -1 before the loop this line of code sat. Only found it evaluating the assembly code while debugging. The assembly code was completely different for this line.
I too have had to get down to assembly, to debug things – one of the major ones was in the 80’s when I found a bug in the PL/1 compiler – it took two weeks to figure out what was going on with our program as sometimes when it compiled it worked, and some times it didn’t.
Look at the assembly, and then machine code, was the only way to figure it out….
The other reason to do assembly/machine code is speed – I agree compilers are pretty good nowadays, but you can still beat them on small bits of critical code.
And yes, understanding assemble definitely helps you program (I’m not counting the JavaScript writers).
However, I’m not sure going down to the microcode would help many people… I think assembly/machine code level would be better for almost everyone…
Same here… I was able to find and characterize a bug in the Data General COBOL compiler only due to understanding the details.
I escaped COBOL to PL/I a year later, and to C (oh what a gift…) a few years after that.
@Mike
Sorry, this is nonsense. x++ is post-increment, so it’s clearly specified what happens when. First use (i.e. address the array slot) then increment. My hunch is that the Borland compiler was crap (why am I unsurprised?).
To all the others whinging “software devels aren’t what they used to be”: it’s not them, it’s the hamster wheel they’re put in, turning faster and faster. Blame capitalism.
I “blame greed” or “blame the laziness of the powerful”. My point here is to avoid oversimplifying serious problems in human nature that appear to be unresolved despite millennia of trying.