Today it is pretty easy to build a robot with an onboard camera and have fun manually driving through that first-person view. But builders with dreams of autonomy quickly learn there is a lot of work between camera installation and autonomously executing a “go to chair” command. Fortunately we can draw upon work such as View Parsing Network by [Bowen Pan, Jiankai Sun, et al]
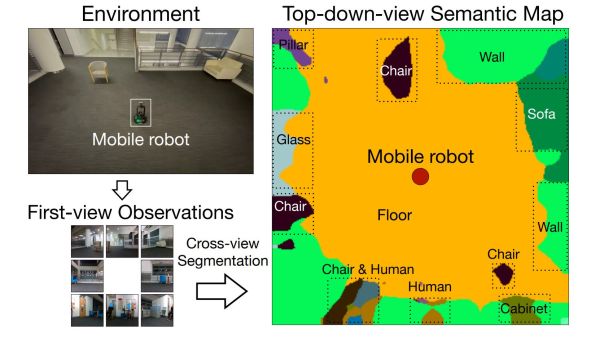
When a camera image comes into a computer, it is merely a large array of numbers representing red, green, and blue color values and our robot has no idea what that image represents. Over the past years, computer vision researchers have found pretty good solutions for problems of image classification (“is there a chair?”) and segmentation (“which pixels correspond to the chair?”) While useful for building an online image search engine, this is not quite enough for robot navigation.
A robot needs to translate those pixel coordinates into real-world layout, and this is the problem View Parsing Network offers to solve. Detailed in Cross-view Semantic Segmentation for Sensing Surroundings (DOI 10.1109/LRA.2020.3004325) the system takes in multiple camera views looking all around the robot. Results of image segmentation are then synthesized into a 2D top-down segmented map of the robot’s surroundings. (“Where is the chair located?”)
The authors documented how to train a view parsing network in a virtual environment, and described the procedure to transfer a trained network to run on a physical robot. Today this process demands a significantly higher skill level than “download Arduino sketch” but we hope such modules will become more plug-and-play in the future for better and smarter robots.
[IROS 2020 Presentation video (duration 10:51) requires free registration, available until at least Nov. 25th 2020. One-minute summary embedded below.]
Continue reading “Robots Learning To Understand Their Surroundings”











