
Hacks don’t have to be practical but it helps if they are educational or clever or amusing, as [Ray Foss] demonstrates with his auto-docking Steam Controller.
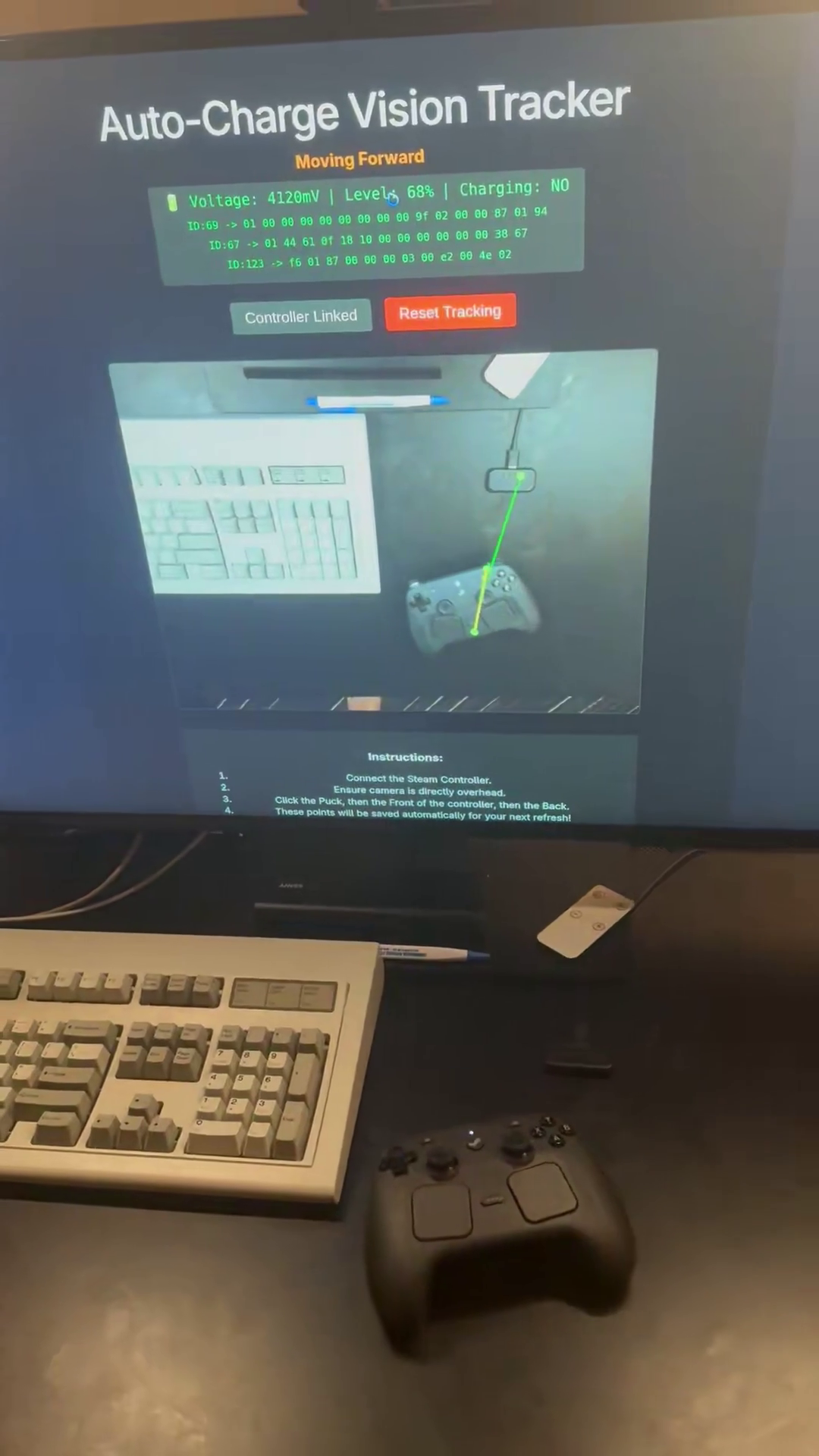 It’s an open-source web application that combines a camera, a Steam Controller, and some clever software for the sole purpose of saving the user from the tyranny of having to manually set the controller onto its magnetic charging puck. Instead, one can simply lay the controller down nearby and let the computer do the rest of the work.
It’s an open-source web application that combines a camera, a Steam Controller, and some clever software for the sole purpose of saving the user from the tyranny of having to manually set the controller onto its magnetic charging puck. Instead, one can simply lay the controller down nearby and let the computer do the rest of the work.
First one fires up the web interface, ensures a webcam has a good top-down view of both the charging puck and the controller, connects wirelessly to the controller, then clicks a few points on the camera view to tell the system where things are.
After that, the system buzzes the controller’s haptic feedback motors to make it skitter across the desktop until — guided by the camera and implementing obstacle avoidance — it docks successfully with its magnetic charging puck.
It may not be super practical and may even seem a bit Rube Goldberg-esque, but it’s fun and demonstrates a few interesting things. One is moving a controller via slip-stick friction by asymmetrically pulsing the feedback motors. Another is automatically reducing the pulse frequency to make smaller movements when it gets close to the charging puck, for finer control.
The computer vision part also ignores anything in expected cable locations, removing the need to deal with them algorithmically. WebHID via the browser takes care of talking to the controller, and confirming a successful docking by watching messages to detect when charging has begun.
If this seems a bit familiar, it’s because this project was inspired by the work of [Very Lazy Pixels] which we covered previously.















