Star Trek has its universal language translator and now researchers from Facebook Artificial Intelligence Research (FAIR) has developed a universal music translator. Much of it is based on Google’s WaveNet, a version of which was also used in the recently announced Google Duplex AI.
 The inspiration for it came from the human ability to hear music played by any instrument and to then be able to whistle or hum it, thereby translating it from one instrument to another. This is something computers have had trouble doing well, until now. The researchers fed their translator a string quartet playing Haydn and had it translate the music to a chorus and orchestra singing and playing in the style of Bach. They’ve even fed it someone whistling the theme from Indiana Jones and had it translate the tune to a symphony in the style of Mozart.
The inspiration for it came from the human ability to hear music played by any instrument and to then be able to whistle or hum it, thereby translating it from one instrument to another. This is something computers have had trouble doing well, until now. The researchers fed their translator a string quartet playing Haydn and had it translate the music to a chorus and orchestra singing and playing in the style of Bach. They’ve even fed it someone whistling the theme from Indiana Jones and had it translate the tune to a symphony in the style of Mozart.
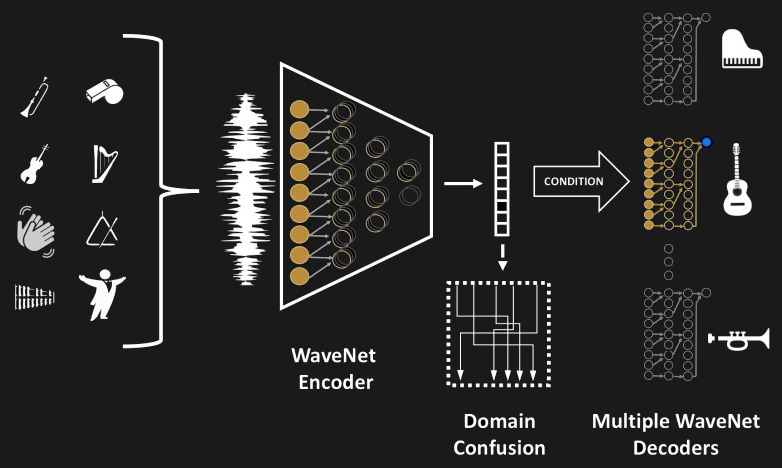
Shown here is the architecture of their network. Note that all the different music is fed into the same encoder network but each instrument which that music can be translated into has its own decoder network. It was implemented in PyTorch and trained using eight Tesla V100 GPUs over a total of six days. Efforts were made during training to ensure that the encoder extracted high-level semantic features from the music fed into it rather than just memorizing the music. More details can be found in their paper.
So if you want to hear how an electric guitar played in the style of Metallica might have been translated to the piano by Beethoven then listen to the samples in the video below.
And while you discuss this work in the comments below, enjoy the following full translation of sample #13, where a Midi rendering of Elvis Presley’s version of Always on My Mind was translated to a symphony in the style of Mozart.














The model seems to add in a whole lot of notes that aren’t really there. I wonder if they added an intermediate sheet music or midi layer and some kind of statistical filter they could remove some of these. Or better still, maybe the model could consider the context of each note in the rest of the song and the music genre and use this to fill in the gaps. The other thing I notice is that the model doesn’t seem to separate between melody, harmony and bass voices, so they all end up pulsing together. Still pretty cool though.
What I’d love to see, is this printed out as sheet music for someone to actually play on a real piano.
Might be a challenge hitting all those notes all at once however.
Ditto!
Not for Lord Vinheteiro. The man’s a legend. Do yourself a favour and check out his YouTube channel.
Now pass it through the translator a dozen times and see what you come up with. Might be as interesting as Google Translate Sings ‘My Heart will go on’ https://www.youtube.com/watch?v=957K58gMbPA&t=0s&index=11&list=PLGnYtw5ezZI-BnVCUhMOcBqi9KggS1fhD
Cool concept, but the outputs somehow sound ugly. I guess it will improve.
https://www.youtube.com/watch?v=E51-2B8gHtk
“Star Trek has its universal language translator and now researchers from Facebook Artificial Intelligence Research (FAIR)”
FAIRly replacing musicians since 2018.
If that is a hack it is in the same class as “… to death with a meat cleaver.” It stands to reason that the symphonic source would provide the most flexibility as it has the greatest frequency and tiberal range, followed by the human choir, however it still sounds really odd, like a radio station fading in and out and phasing at the tame time, in a distinctly rhythmic way, like somebody was waving the antenna around.
Seriously underwhelming, and they probably just let us hear the samples which worked “best”.
What, you were expecting some Rick Astley done as as a Mozart symphony?
(Actually, a colleague is doing a “Kokoda Challenge” walk in the Mt. Coot-tha forest this weekend… so a sample of “The Proclaimers – 500 Miles” rendered via this translator would be a handy thing to stir him up with.)
I’d find it more useful if I could hum a tune & the system could tell me what it is. Shazam can’t do this, it needs actual samples of music.
?? I haven’t tried Shazam for a long time, but I seem to remember that one of the most impressive features was that you COULD hum a tune and possibly get it identified. Am I thinking of a different service?
SoundHound maybe?
very impressive. but first i was distressed by the briefness of the clips.
then i was distressed by the representation of an spectrum as a fake waveform, and i want these guys’ license to play with sound to be revoked.
Imitone.com
The output still needs some work, but looks like they’re on the right track. First Lyrebird, then this one: impressive!
In a few years we’ll have dead artists estates battling for the use of their clients voice, music, style and image, until the point their data will be made available to media companies to create say an original concert where Elvis duets with Freddie with Jimi, Stevie, Jaco and Keith as musicians. And of course movies too. There’s a potential huge load of money driving development in that field, so “less than 10 years” for first useable results wouldn’t sound so exaggerated.
Which brings us to the point: the more you put of yourself online, the more data someone will have at disposal to create a digital copy of you that could be used to do something you wouldn’t.
https://www.youtube.com/watch?v=cQ54GDm1eL0
It’s a cool idea but the output or results gotten from a music when played isn’t that clear. It would be better if lyrics and notes could be generated as music plays
Coming to a supermarket near you….
Or an elevator.