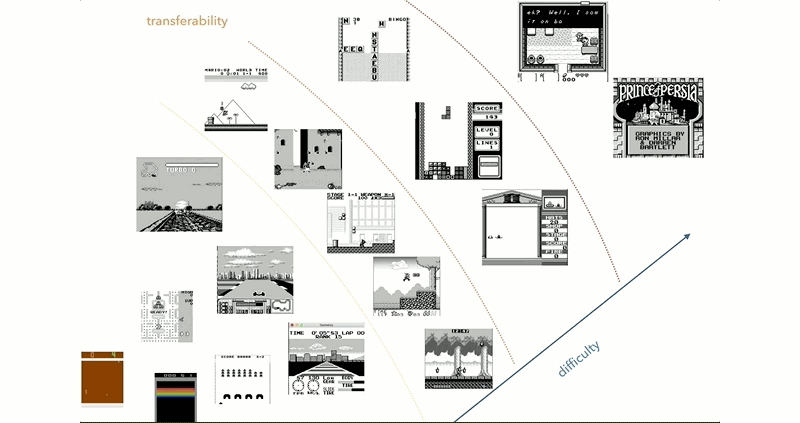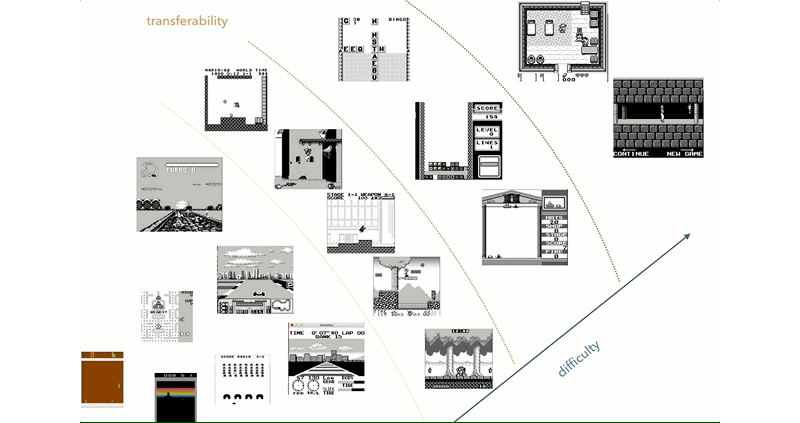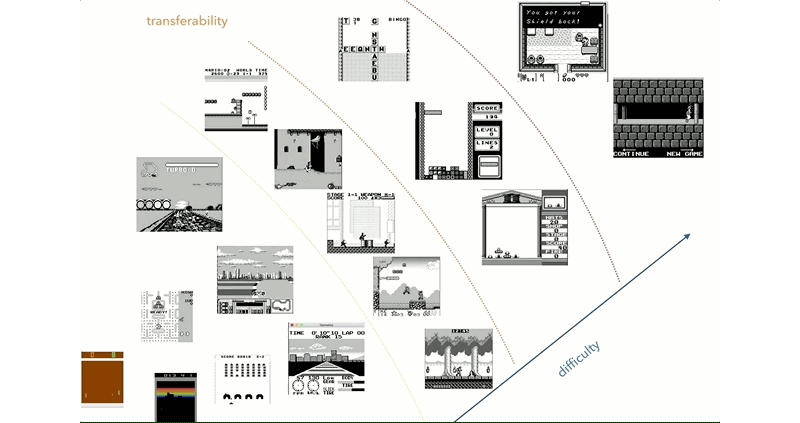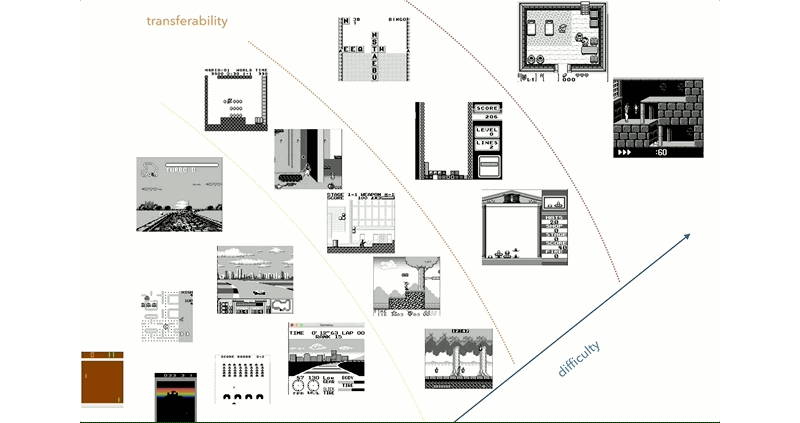
Reinforcement learning has been a hot-button area of research into artificial intelligence. This is a method where software agents make decisions and refine these over time based on analyzing resulting outcomes. [Kamil Rocki] had been exploring this field, but needed some more powerful tools. As it turned out, a cluster of emulated Game Boys running at a billion FPS was just the ticket.
The trick to efficient development of reinforcement learning systems is to be able to run things quickly. If it takes an AI one thousand attempts to clear level 1 of Super Mario Bros., you’d better hope you’re not running that in real time. [Kamil] started by coding a Game Boy emulator in C. By then implementing it in Verilog, [Kamil] was able to create a cluster of emulated Game Boys that enabled games to be run at breakneck speed, greatly speeding the training and development process.
[Kamil] goes into detail about how the work came to revolve around the Game Boy platform. After initial work with the Atari 2600, which is somewhat of a defacto standard in RL circles, [Kamil] began to explore further. It was desired to have an environment with a well-documented CPU, a simple display to cut down on the preprocessing required, and a wide selection of games.
The goal of the project is to allow [Kamil] to explore the transfer of knowledge from one game to another in RL systems. The aim is to determine whether for an AI, skills at Metroid can help in Prince of Persia, for example. This is arguably true for human players, but it remains to be seen if this can be carried over for RL systems.
It’s rather advanced work, on both a hardware emulation level and in terms of AI research. Similar work has been done, training a computer to play Super Mario through monitoring score and world values. We can’t wait to see where this research leads in years to come.














This is excellent work but I think a better and likely faster approach would have been to use static recompilation AKA transcompilation. Using one of the CPU+FPGA hybrid chips would have provided a faster execution environment while providing the FPGA environment desired. The only issue is that some programs (games) use computed jump instructions that a difficult to translate but those are easy to identify beforehand.
Anybody found the code? This repository is empty: https://github.com/krocki/gb
https://github.com/krocki/gb/tree/be2e15831f5d3daa169c64f4da59571c03c55f39
I don’t know if Metroid skills are applicable elsewhere, but a large hand cannon surely is.
>” If it takes an AI one thousand attempts to clear level 1 of Super Mario Bros., you’d better hope you’re not running that in real time.”
Actually, you’d better run that in real-time anyways. The downside of training AIs on fast-forward is that AI researchers now claim intelligent programs that would actually take the age of universe to figure something out if they were running at the speed of the real event. They’re producing AIs that are essentially just blind chicken pecking away at the problem at random until they find the correct seed that leads to the accepted solution. That doesn’t show they’re intelligent – it just shows computers have gotten so fast they can find solutions by Monte Carlo methods without any understanding of the problem at hand.
In other words, if you had a peg-in-board toy, and an empty oil drum in a big paint shaker, the current argument for AI is that if you shake the oil drum with the parts inside, eventually the pegs will go in and “intelligence” is just a matter of shaking it faster. Of course, you might recognize that mere random search isn’t sufficient, so to make it seem different you make a computer shake the drum in different patterns and record which pattern makes the pegs fall in the fastest, and call that intelligent (How it decides which patterns to try: Throw dice.).
In machine learning the AI is not randomly trying things until it arrives at “the solution.” Rather it adjusts its internal setup until it comes up with a good response to all kinds of inputs. Once trained, the AI *doesn’t* shake the drum, it identifies the shape of each peg, finds the matching hole, and puts it in there. And it does that faster and better than a human, whether the task is recognizing faces or speech, picking the best next move at chess or Go, playing real-time strategy, adding new details to an image in the style of Van Gogh, …
AI training is certainly slow and far from human performance: humans can learn a new letter shape after seeing it once, we can pick the mechanics of a new video game in minutes, we can read instructions instead of fumbling around. But AIs don’t learn by “Monte Carlo methods” or “throwing dice,” that’s a misdescription of gradient descent and other algorithms that are advancing rapidly towards things like concept reuse, generalizing from experience, preferring exploration over repetition, etc.
>”Rather it adjusts its internal setup until it comes up with a good response to all kinds of inputs.”
And how does it do that?
If there’s a programmed method for discovering the solutions, then it’s just following a formula. It’s repeating the intelligence and deductive abilities of the person who programmed it – in other words, the intelligence of the “AI” is outsourced to the people who made it.
If there isn’t a programmed method, how does it decide which parameters to try? Of course, by random. How else?
What you’re doing there is just explaining the same thing in different words, and thinking it leads to different results. This is exactly the fallacy of AI that I’m talking about. A rose by any other name…
Honestly, it doesn’t work that different in biological intelligence. We exist at a point that arrived after millions and millions of years of not only intelligence but just plain trial and error and luck. We have a bunch of DNA filled with knowledge, we have parents, siblings, peers, rivals, media, society, all teaching us. These AI systems don’t.
Did you always play games all alone? Nobody ever helped you or told you what to do? You never even read the manual? These AI systems are doing just that, going in so dark they don’t even know what the concept of jumping is, and then within an hour it’s figured the whole game out.
Biological intelligence works *exactly* the same way, but it DOES happen in real time and takes MILLIONS of years. This is doing it in hours. It only seems so different because the time differential is almost incomprehensible. It’s like comparing a 1970s calculator to a 2019 smartphone… at its most basic level, they’re both just some logic circuits on a board doing simple math. Obviously the smartphone is a zillion times faster compared to a calculator, so they seem to have only superficial similarities, but in fact they are more identical than not at their most fundamental building-block level.
In a funny way, it mirrors society. Once human beings started working together, it was like humanity became a multi-core processor, lol!
>” that’s a misdescription of gradient descent and other algorithms ”
Those would be examples of the programmed methods. You make an assumption about how the problem should be solved, program it in, and lo – the program does it a far as your assumptions apply to the case. Is this intelligence?
>”picking the best next move at chess or Go”
Regarding this, the “other algorithm” and the Monte Carlo method: If you have a deterministic method of traversing your problem space, such as gradient descent, you run into the problem of getting stuck at local minima/maxima. Your algorithm can drop into a hole in the function that evaluates the merit of the solution, and it can’t get out because every way out is immediately worse than the solution it found. Hence why, the algorithms like AlphaGo and its variants actually do use random solutions to explore the problem space to find other solutions they might have missed. After all, they’re not quantum computers – they can’t try every possibility at once.
They essentially throw dice to find out strategies that their human counterparts will have missed, because no human can play the equivalent of 800 years of gameplay. Fundamentally, these algorithms are exceedingly dumb – not intelligent – they’re just brute-forcing it in a slightly more efficient fashion.
Or, it’s kinda like the problem of finding the deepest part of the ocean, by plumbing the depths with an 1800’s sailing ship and a spool of rope.
Any method you have will likely miss the correct answer, unless you drop your line over every square feet of the ocean floor. There is no systematic method of finding the deepest spot that would qualify as “intelligent” on the merit of finding the spot without resorting to brute force, either through exhaustion or luck, or a combination of both.
In order to be intelligent, the solution would have to go past the problem of simply measuring the ocean floor. Instead, you have to understand what the ocean floor is, why it is, so you can make intelligent guesses about where the deepest spots might be – because you know that there cannot be a 100 mile deep hole on a continental shelf etc.
If you give the algorithm that information as a limiting factor for where to search, you’re still relying on an external intelligent agent to provide that data to the dumb algorithm that simply does the measurements. How does the external agent come up with the information? If you can answer that, you define intelligence.
When you try to answer that, it soon becomes apparent that no current “AI” can be intelligent because they simply lack the means to seek information beyond the problem they’re tasked to solve. They can’t in and of themselves obtain the necessary knowledge to narrow their searches to the relevant areas of the problem space – they have to be told how/where to search, or simply come by the information by random.
…..Would you like to play a game? Y/N
Thoughts of the classic War Games comes to mind. I remember the iconic atom bombs flying and the X’s and O’s too at wicked speeds until the machine figures out that there was no way to win. …good stuff, actually. :-)
In the year 1987 I wrote an Apple ][ basic program that played Tic-Tac-Toe and started knowing nothing about how to play. It learned based on the prinicple of simple conditioning where, of course, winning was good and reinforced and losing did the opposite. Most recent plays were impacted the most while prior ones less so all the way to the start. Through multiple games the machine quickly learned how to block your moves but never quite figured out how to win most of the time so it sort of got “depressed” but overall it worked pretty good. It got me an A in computer programming in my High School days. :-)