
Recently Air Canada was in the news regarding the outcome of Moffatt v. Air Canada, in which Air Canada was forced to pay restitution to Mr. Moffatt after the latter had been disadvantaged by advice given by a chatbot on the Air Canada website regarding the latter’s bereavement fare policy. When Mr. Moffatt inquired whether he could apply for the bereavement fare after returning from the flight, the chatbot said that this was the case, even though the link which it provided to the official bereavement policy page said otherwise.
This latter aspect of the case is by far the most interesting aspect of this case, as it raises many questions about the technical details of this chatbot which Air Canada had deployed on its website. Since the basic idea behind such a chatbot is that it uses a curated source of (company) documentation and policies, the assumption made by many is that this particular chatbot instead used an LLM with more generic information in it, possibly sourced from many other public-facing policy pages.
Whatever the case may be, chatbots are increasingly used by companies, but instead of pure LLMs they use what is called RAG: retrieval augmented generation. This bypasses the language model and instead fetches factual information from a vetted source of documentation.
Why LLMs Don’t Do Facts
A core problem with using LLMs and expecting these to answer questions truthfully is that this is not possible, due to how language models work. What these act on is the likelihood of certain words and phrases occurring in sequence, but there is no ‘truth’ or ‘falsehood’ embedded in their parameter weights. This often leads to jarring situations with chatbots such as ChatGPT where it can appear that the system is lying, changing its mind and generally playing it fast and loose with factual statements.
The way that this is generally dealt with by LLM companies such as OpenAI is by acting on a negative response by the human user to the query by essentially running the same query through the LLM again, with a few alterations to hopefully get a response that the inquisitive user will find more pleasing. It could hereby be argued that in order to know what ‘true’ and ‘false’ is some level of intelligence is required, which is something that LLMs by design are completely incapable of.
With the Air Canada case this is more than obvious, as the chatbot confidently stated towards Mr. Moffatt among other things the following:
Air Canada offers reduced bereavement fares if you need to travel because of an imminent death or a death in your immediate family.
…
If you need to travel immediately or have already travelled and would like to submit your ticket for a reduced bereavement rate, kindly do so within 90 days of the date your ticket was issued by completing our Ticket Refund Application form.
Here the underlined ‘bereavement fares’ section linked to the official Air Canada policy, yet the chatbot had not cited this answer from the official policy document link. An explanation could be that the backing model was trained with the wrong text, or that a wrong internal policy document was queried, but the ’90 days’ element is as far as anyone can determine – including the comment section over at the Ars Technica article on the topic – not something that has ever been a policy at this particular airline. What’s also interesting is that Air Canada has now removed the chatbot from its site, all of which suggests that it wasn’t using RAG.
Grounding LLMs With RAGs
LLMs have a lot of disadvantages when it comes to factual information, even beyond the aforementioned. Where an LLM is also rather restrictive is when it comes to keeping up to date with new information, as inside the model new information will have to be integrated as properly weighed (‘trained’) parameters, while the old data should be removed or updated. Possibly a whole new model has to be trained from fresh training data, all of which makes running an LLM-based chatbot computationally and financially expensive to run.
In a run-down by IBM Research they go over many of these advantages and disadvantages and why RAGs make sense for any situation where you not only want to be able to trust a provided answer, but also want to be able to check the sources. This ‘grounding’ of an LLM means effectively bypassing it and running the system more like a traditional Internet search engine, although the LLM is still used to add flavor text and the illusion of a coherent conversation as it provides more flexibility than a chatbot using purely static scripts.
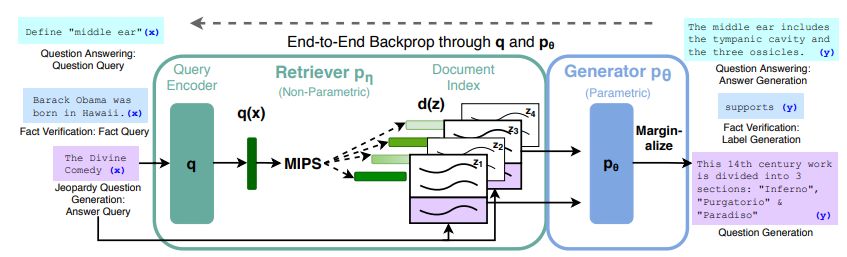
The idea of using these more traditional methods with LLMs to keep them from going off the rails was first pitched by Meta (née Facebook) in a 2020 paper, in which they used a neural network-based retriever to access information in a vector index of Wikipedia. This supports a range of different types of queries, including questions, fact verification and generating trivia questions. The retriever component thus only has to be trained to be able to find specific information in the prepared documents, which immediately adds the ability to verify the provided information using these documents rather than rely on a highly opaque parameterized model.
In the IBM provided example, they paint a scenario where an employee asks a number of questions to a company chatbot, which pulls up the employee’s HR files, checks available vacation days, matches the request against company policies and combines the resulting information into a response. Of course, in the Facebook paper it is noted that RAG-enhanced LLMs are still very much capable of ‘hallucinating’ and need ‘fine-tuning’ to keep them in line. On the bright side, a result of using RAG is that sources can be provided and linked, so that said employee can then check those to verify that the response was correct.
LLMs Are Still Dumb
The problematic part with chatbots is that unless they have been carefully scripted by a human being (with QA validating their work), they are bound to mess up. With pure LLM-based chatbots this is beyond question, as the responses provided range between plausible to completely delusional. Grounding LLMs with RAG reduces the amount of made-up nonsense, but in the absence of any intelligence and comprehension of what the algorithm generates as a response, there also cannot be any accountability.
That is, the accountability (and liability) shifts to the entity which opted to put the chatbot in place, as was succinctly and rightfully demonstrated in Moffatt v. Air Canada. In the end no matter how advanced or complex the system and its algorithms are, the liability remains with the human element in charge. As the Civil Resolution Tribunal’s judge who presided over the case states in the ruling: “It should be obvious to Air Canada that it is responsible for all the information on its website. It makes no difference whether the information comes from a static page or a chatbot.”
In light of such a case, a company should strongly question whether there is any conceivable benefit to having a chatbot feature on their public-facing website rather than a highly capable search functionality which could still use natural language processing to provide more relevant search results, but which leaves the linked results to human-written and human-validated documents as the authoritative response. For both Air Canada and Mr. Moffatt such a system would have been a win-win and this whole unpleasant business could have been avoided.














If Watson is the retrieval engine does that mean Sherlock is the LLM – or is it Moriarty?
Sherlock, Moriarty is the hallucination.
Real citations are great. The Bing AI still hallucinates on me but now it takes seconds to verify. But we’ll be in deep doodoo when the AI starts citing AI-written articles
Firstly, they already do. Secondly you’re missing the underlying problem. These systems are not capable of being truthful, or checking the veracity of a statement. Even if layers are added that try to do this, these facts remain.
At the end of the day these are search engines that regurgitate statistically likely sentences.
The article doesn’t address the most interesting part of the incident: in the court case, Air Canada’s defense was that the chatbot is responsible for its actions. The court decided otherwise – quite rightly in my view.
One problem with the current crop of AI is that there’s no real way to debug it. You can’t set breakpoints in the ANN’s and trace the execution as it answers a prompt, looking for where the program deviates from your mental model of what it should be doing. (Which is how we debug computer programs currently.)
Another problem is that, even if we *could* set a breakpoint in specific ANN’s, there’s no way to interpret what it’s doing. I don’t mean interpret whether it’s correct or not, I mean interpret *anything* about the process – the LLM is completely opaque front to back and there’s no meaningful information in any of the internal workings.
An even more insidious problem is that people don’t want the LLM to report reality, they want a modified LLM that tilts reality towards their political ideal. This was thrown into the public spotlight recently when Google’s AI would refuse to generate an image of a white couple (by prompt), but had no problem generating a black couple. Asking for an image of a pope, or viking, or Nazi soldier had hilarious results.
And finally, I’ve recently been hobby-researching the amount of disinformation on the internet. Setting aside mass media lies and hallucinations for a moment, I’ve been looking over the comments attached to news reports for some news aggregators I follow. Setting aside the shit-posting, the number of people who post simply incorrect facts is nothing short of astounding! Taking EV’s as an example, the amount of incorrect information responses is huge, all of which are easily debunked by a quick search.
(Such as that EVs catch fire easily. Statistically speaking, ICE vehicles are much more likely than EVs to catch fire.)
We’re in Plato’s cave, and don’t know it. It’s no wonder that LLM AI’s are unreliable.
>Air Canada’s defense was that the chatbot is responsible for its actions.
Got to love that argument… Nothing is ever our fault!
Now if they were pointing to their technical outsourcing company as the guilty party, assuming one was involved… I’d then agree its not your companies fault – though you should treat your customer as if you were at fault and expect the same from the tech company that made your systems..
” Got to love that argument… Nothing is ever our fault! ”
So machines are learning our habits? Big surprise there.
“Air Canada’s defense was that the chatbot is responsible for its actions.”
AC: Well, obviously the plane wanted to crash itself into the mountainside… we’re not responsible for the plane’s actions.
Deferred responsibility is literally one of the main goals of corporate investment in “AI”, right next to reducing labour to unpaid migrant interns who need the job to stay in the country.
>Taking EV’s as an example, the amount of incorrect information responses is huge, all of which are easily debunked by a quick search.
But do you then verify THAT isn’t the nonsense? The trouble is, a lot of people don’t make a difference between a corporate written advertisement pieces, sensationalist clickbait journalism, and original sources like scientific papers and publications when judging the reliability of information sources online. Heck, kids these days figure that tiktok is a reliable source of information.
Take greencarreports for example. They link to their own previous articles as sources for claims in their articles, which then refer to other news sources, which refer to other sources… They’re playing a game of broken telephone where you can pull off multi-level spin on any piece of information by subtly changing the message to keep a positive outlook on whatever you WANT to be true.
>(Such as that EVs catch fire easily. Statistically speaking, ICE vehicles are much more likely than EVs to catch fire.)
That’s abuse of statistics. Whether one type of car catches fire more often statistically speaking can have nothing to do with the ease of setting it on fire. That’s because the mechanisms for doing so, the circumstances and even the sample groups used for the statistics aren’t comparable.
For example, did you know that the third most common reason why cars burn is because people set them on fire on purpose? Now, are people commonly in the habit of torching their new expensive EVs? Are there many old clunker EVs with electrical problems (second most common reason for car fires) on the roads? Remember that the market is rapidly expanding, so the age distribution of EVs is heavily skewed towards younger cars, which obviously have fewer problems.
Turns out, it isn’t such a simple thing to fact-check by a google search – unless you just want to dig up some meaningless factoid to back yourself up with.
The most common reason why cars burn of course is fuel leaks, but there as well you have the apples to oranges comparison between different demographics of vehicles and vehicle owners IF you were to compare ICE vs. EV on statistics alone.
The real question would go something along the lines of: “If you put a screwdriver through a car’s fuel tank, or an EV’s battery, to simulate a crash situation of some sort – which one is more likely to go up in flames?”.
Your mileage will vary according to the test criteria you set.
As we all know, correlation isn’t causation. If you don’t know why, you don’t know anything.
Well written article! Succintly captures why so many people in the AI field are focused on various systems to keep LLMs on the rails.
I don’t get the customized LLM thing. You need the whole Large Language to get the starting Model right? So how would anyone expect it to stick to the later training data?
you hire employees with their lifetime of experience.
You provide them with your companies SOP and other materials of pertinence.
Despite their educational or vocational histories you expect them to confine their actions and interactions to the acceptable protocols provided them.
This is how you would expect a chatbot with a LLM backend and appropriate RAG to “stick to the later training data”
The LLM functions as “how to understand:” and the RAG provides appropriate responses. Easy Peasy….when it works
It takes a great deal of compute power to build an LLM. I read an online estimate that it takes about $75 million to do the initial run.
Then the LLAMA database leaked online a year ago, and about 10 years of improvement happened in the next 2 months due to open source contributions.
One of the results was that, given a trained LLM you can add new model information fairly cheaply. A beefy laptop running over a weekend would add new information to the LLM.
I don’t know the mechanism, but probably the feedback learning rate is bumped up in this case, so that the new information is learned more strongly than the original information was learned. Or it could be that basic text is so complex that it takes most of the effort, and that once you have the basic text the amount of new information above and beyond the syntax and grammar is so little that it can be learned more quickly.
This was one of the potential benefits of the LLM systems: many companies have transcribed call logs of customer service requests, you can feed all of that into an LLM and train it over a weekend, and you’d have a chatbot that knows the answers to most of your customer service requests.
You can’t actually add new data easily, that’s not how the OSS models were developed. A trained model is like a video encoded using the lowest possible quality settings to save space, you can’t just shovel more in without risking artifacts that are self-compounding.
In other news, Klarna (a buy now, pay later racket) just yesterday boasted that their AI chat bot handles 2/3rd of all support requests, which let them sack 700 employees.
What could possibly go wrong?
If we’re lucky, the LLM will warn people they’re being scammed!
Worse case, it lies to customers, which is probably what was already happening.
Let’s build AI to use for skilled labor so that humans have to do the menial stuff! Wait, why does that sound wrong…
> In other news, Klarna (a buy now, pay later racket) just yesterday boasted that their AI chat bot handles 2/3rd of all support requests, which let them sack 700 employees.
In the early 2000s I worked tech support for an online tax return service. One of their key performance metrics was how quickly the staff could get rid on incoming calls. It was better for staff stats to have the same customer call back 10 times and get some boilerplate response, than to take a couple of minutes to listen to their question, address their issue, and give them useful advice.
I have no doubt the sacked staff at Klarna had similar stupid KPIs. Why hire a human if management instructs the humans to not use their brains.
This is hardly surprising, remember Air Canada’s unofficial motto, “We’re not satisfied until you’re not satisfied.”
Artificial intelligence isn’t. It’s not thinking. There’s no reason or logic happening, it’s just an illusion. All it can create is either inane, overwrought reddit-post chatter or bad art that all looks the same, like something you’d buy wholesale to hang on the wall in an AirBnB. Absolute turd of a technology, way overhyped and overleveraged.
It could easily create your comment though? Or make it much better probably…
Artificial chicken is not actual chicken. Artificial intelligence is not actual intelligence. What is your point about its not thinking? It’s artificially thinking.
It’s not. As the article points out multiple times, and references sources on, LLM models do not think, and cannot evaluate input or output, and are *designed* that way. Why? Because it turns out that brute forcing the appearance of thought is easier than building the real thing and these tools can be used to make money and fire more employees.
How do the work then? It’s statistics, literally the million monkeys on typewriters analogy.
Yes the monkey analogy. I can assure you have no idea how they work. Current research papers coming out are still discovering new things.
I use RAG in production level applications touching thousands of customers. I built RAG and inference in many apps and things are accelerating.
Hackaday seems to put out very watered down AI articles then people hit the comments with the most regurgitated lame arguments “monkeys on a keyboard” or “just predicts next word” This is an article I would expect maybe day one for a new AI intern who has no prior experience. As in clearly they aren’t adding real world experience. In fact the kinda of thing that separates us from the AI.
You can say this, and you can appeal to your own authority and all that, but LLMs do NOT think (and they cannot), they can NOT generate anything novel,
YES, they do an extremely roided-up version of ‘just predicting next word,’
and honestly you’re not doing the field any favors by spitting random “you don’t know what you’re talking abouts.” It’s uh, pretty well understood how these things work. Anyone who suggests it’s not either actually doesn’t know what they’re talking about, or has a motive to muddy the waters.
The tech press is already doing a great job with breathlessly reporting whatever non-factual AI crap crosses their desk, for clicks. Please stick to the truth.
Ryan, you misunderstood me. I assure him he doesn’t understand because if you read the papers and watch the videos of people leading the field and they don’t completely understand why it works so well.
They have decent theories, much more thoughtful and useful than the contrarian saying it’s just next word. And thing you don’t get is it may be those things you are saying but it sounds so silly and useless to reduce it to that.
Like me saying the mind is just the brain. Sure…but there’s a lot going on in between that we don’t understand and the mind is still pretty useful even though it’s just the brain.
Anytime someone said wow look at what the mind can do, and I just say well you know it’s just the brain doing that?
Same thing when someone Saya
S AI isn’t thinking or just predicting next word. No kidding, its artificially thinking! And artificially thinking in a system one kind of way which is basically regurgitation. You are in a bubble seeing silly AI propaganda videos instead of actual researchers.
I’ve been reading hackaday for many years but the AI thing is funny to watch on here because it’s starts to show everyone’s age. Like someone who loves the typewriter and doesn’t want to see the good in a computer. It’s just a typewriter with internet right?
Again because I now it’ll be said a million more times. No it’s not thinking because it’s not actual biological tissue and a million other reasons but you are totally missing the point. That it is very useful. Not to you because I’m sure you use it with disdain. But to many others including the next generation, it will be.
Did Air Canada build their own, or used a software provider?? And same question for Klarna? Trying to see if there’s less risk on build vs buy!
It seems like we keep having to bolt manual patches onto these AIs to prevent them giving incorrect or dangerous advice, or prevent them saying racist or defamatory things. Gave we reached the point yet where the size of the manual patches exceeds the size of the actual training data?
Air Canada’s switch to a RAG Chatbot shows why it’s better than an LLM for factual accuracy. The RAG model combines retrieval-based responses with generative AI, ensuring up-to-date, reliable information for travelers. It’s a smart choice for improving customer support.