The radio hackers in the audience will be familiar with a spectrogram display, but for the uninitiated, it’s basically a visual representation of how a range of frequencies are changing with time. Usually such a display is used to identify a clear transmission in a sea of noise, but with the right software, it’s possible to generate a signal that shows up as text or an image when viewed as a spectrogram. Musicians even occasionally use the technique to hide images in their songs. Unfortunately, the audio side of such a trick generally sounds like gibberish to human ears.
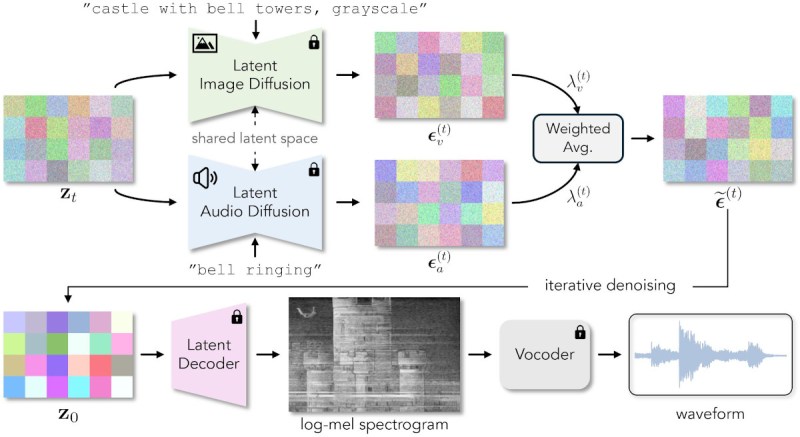
Or at least, it used to. Students from the University of Michigan have found a way to use diffusion models to not only create a spectrogram image for a given prompt, but to do it with audio that actually makes sense given what the image shows. So for example if you asked for a spectrogram of a race car, you might get an audio track that sounds like a revving engine.

The first step of the technique is easy enough — two separate pre-trained models are used, Stable Diffusion to create the image, and Auffusion4 to produce the audio. The results are then combined via weighted average, and enter into an iterative denoising process to refine the end result. Normally the process produces a grayscale image, but as the paper explains, a third model can be kicked in to produce a more visually pleasing result without impacting the audio itself.
Ultimately, neither the visual nor audio component is perfect. But they both get close enough that you get the idea, and that alone is pretty impressive. We won’t hazard to guess what practical applications exist for this technique, but the paper does hint at some potential use for steganography. Perhaps something to keep in mind the next time we try to hide data in an episode of the Hackaday Podcast.














That is quite interesting. But I must disagree with this statement:
” Unfortunately, the audio side of such a trick generally sounds like gibberish to human ears. Or at least, it used to.”
Software inserting visuals into music spectrogram was available in at least late ’90. I remember Richard D. James (Aphex Twin) did that on his track “ΔMi−1 = −αΣn=1NDi[n][Σj∈C[i]Fji[n − 1] + Fexti[n−1]]” (also known as “formula”) where he hid his distorted face image – that was 1999. I know – for some that track “sounds like gibberish” but I swear it’s music ;-) Also he was not the only one.
Aphex Twin loves a spectrogram – the weird sound at the end of Windlowlicker (which is probably the most “mainstream” track of his) is one too and although it’s not exactly musical it’s certainly not gibberish or noise:
https://youtu.be/MGPg713A_LM?t=357
Never let it be said that the Hackaday commenters will allow a little thing like having a point get in the way of them of being argumentative…
This literally sounds like a 56K modem, it’s the definition of gibberish digital noise.
But can it be trained to reverse engineer the shape of an airplane by listening the to sound of its wake?
oooh
I’m imagining setting up a wide spectrographic display with a persistence of a few seconds, and feeding a loop of these sounds into it. Wall art for the über-nerd!
Audio watermarking is going to be a lot more obvious now.