
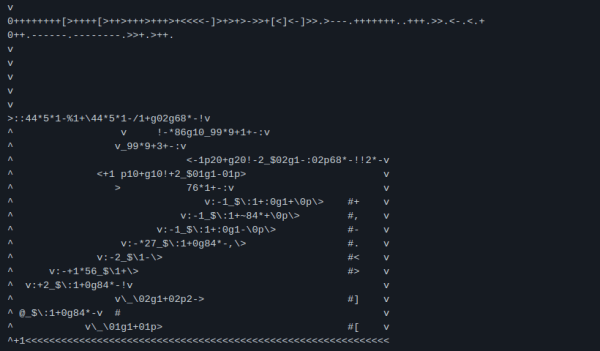
There are many questions that can be asked for software projects, with most of these questions starting with ‘Why…?’. This is true for the challenge of proving that cascading stylesheets are Turing-complete, or that you don’t need all those fancy ISA bits of an ARM processors when you already got the LDM and STM commands in the 32-bit ISA. What originally started off as a bit of a running gag in a group of developers led to [Kellan Clark] implementing a Turing-complete computer and a functioning interpreter using nothing but these two opcodes.

These two opcodes essentially allow the storing or reading of data into memory from any combination of the 16 general-purpose registers (GPRs). This makes them both extremely versatile and also extremely open to ‘abuse’ like in this example. For a straightforward implementation that could prove the concept, [Kellan] decided to pick one of everyone’s favorite esoteric programming languages: Brainf**k, creating the charmingly titled Armf**k that allows anyone to write BF programs for any suitable ARM processor, like the ARM7TDMI in the Game Boy Advance that [Kellan] targeted.
As a proof of concept it’s unquestioningly intriguing, and a great example of how the most powerful parts of any ISA are those that move data around. After all, as anyone who writes ASM and C knows, computers are just machines that can copy bytes around really fast to make stuff happen. Mind-blowing examples like these serve to illustrate that point quite well.
Tip kindly provided by [eeucalyptus].


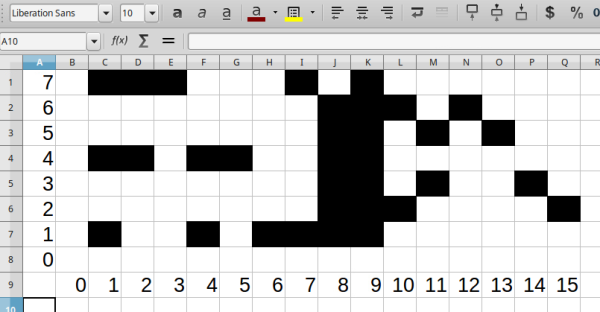
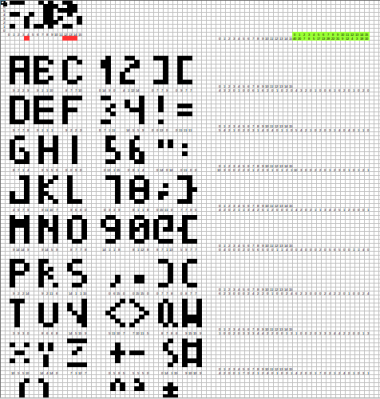 Rather than a pixel-by-pixel representation of the characters, [Jaromir] created a palette of 16 single byte vectors of commonly used patterns. Characters are created by combining these vectors. Each character is 4 x 8 pixels, so 4 vectors are used per character. The hard part was picking commonly used bit patterns for the vectors.
Rather than a pixel-by-pixel representation of the characters, [Jaromir] created a palette of 16 single byte vectors of commonly used patterns. Characters are created by combining these vectors. Each character is 4 x 8 pixels, so 4 vectors are used per character. The hard part was picking commonly used bit patterns for the vectors.









