
One of the practical upsides of improved computer vision systems and machine learning has been the ability of computers to translate text from one language or format to another. [Jchen] used this to develop Braille Vision which can turn inaccessible text into braille on the go.
Using a headless Raspberry Pi 4 or 5 running Tesseract OCR, the device has a microswitch shutter to take a picture of a poster or other object. The device processes any text it finds and gives the user an audible cue when it is finished. A rotary knob on the back of the device then moves the braille display pad through each character. When the end of the message is reached, it then cycles back to the beginning.
Development involved breadboarding an Arduino hooked up to some MOSFETs to drive the solenoids for the braille display until the system worked well enough to solder together with wires and perfboard. Everything is housed in a 3D printed shell that appears similar in size to an old Polaroid instant camera.
We’ve seen a vibrating braille output prototype for smartphones, how blind makers are using 3D printing, and are wondering what ever happened with “tixel” displays? If you’re new to braille, try 3D printing your own trainer out of TPU.
Continue reading “This Polaroid-esque OCR Machine Turns Text To Braille In The Wild”
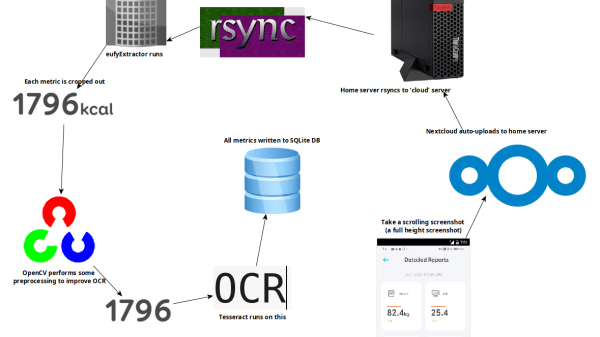
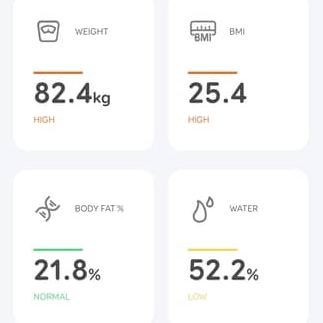 First of all, while OCR can be reliable, it needs the right conditions. One thing that ended up being a big problem was the way the app appends units (kg, %) after the numbers. Not only are they tucked in very close, but they’re about half the height of the numbers themselves. It turns out that mixing and matching character height, in addition to snugging them up against one another, is something tailor-made to give OCR reliability problems.
First of all, while OCR can be reliable, it needs the right conditions. One thing that ended up being a big problem was the way the app appends units (kg, %) after the numbers. Not only are they tucked in very close, but they’re about half the height of the numbers themselves. It turns out that mixing and matching character height, in addition to snugging them up against one another, is something tailor-made to give OCR reliability problems.







