
A factory is a machine. It takes a fixed set of inputs – circuit boards, plastic enclosures, optimism – and produces a fixed set of outputs in the form of assembled products. Sometimes it is comprised of real machines (see any recent video of a Tesla assembly line) but more often it’s a mixture of mechanical machines and meaty humans working together. Regardless of the exact balance the factory machine is conceived of by a production engineer and goes through the same design, iteration, polish cycle that the rest of the product does (in this sense product development is somewhat fractal). Last year [Michael Ossmann] had a surprise production problem which is both a chilling tale of a nasty hardware bug and a great reminder of how fragile manufacturing can be. It’s a natural fit for this year’s theme of going to production.
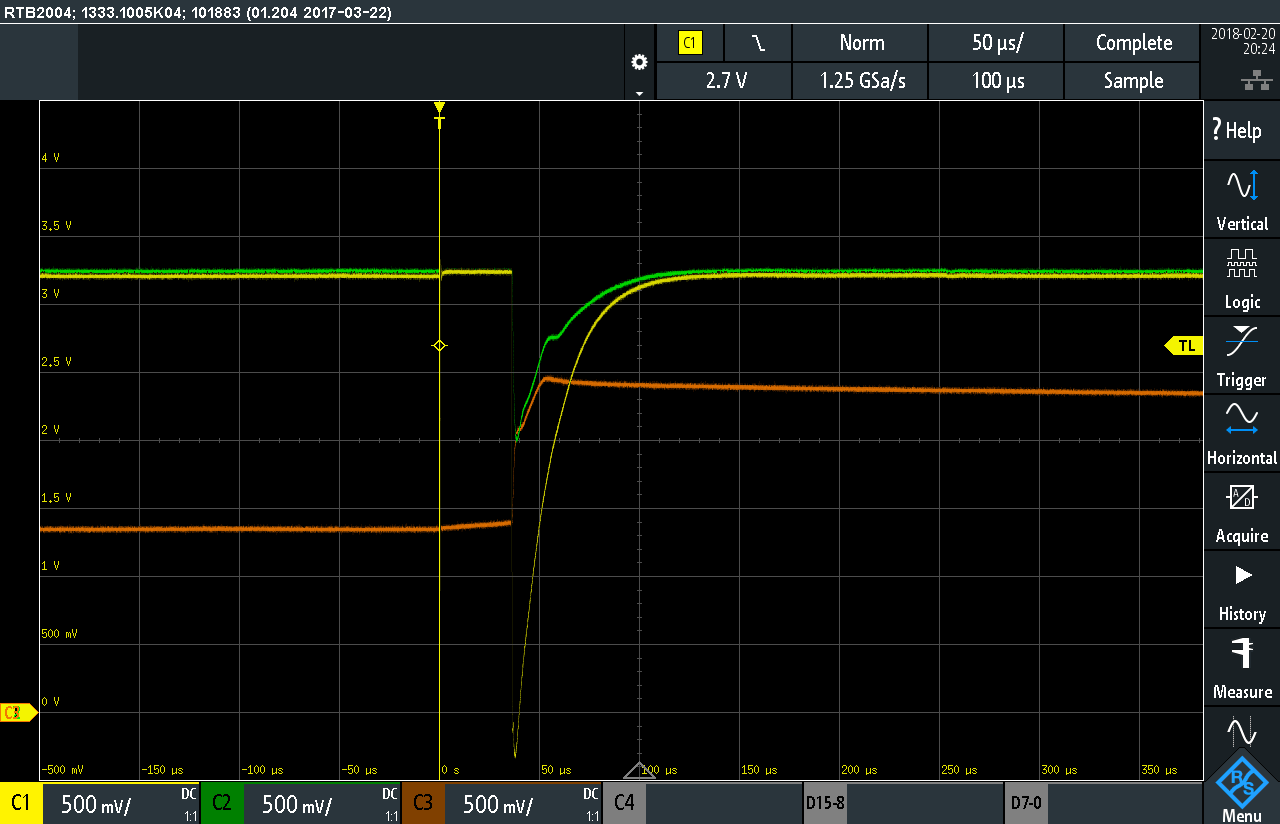
The saga begins with [Michael] receiving an urgent message from the factory that an existing product which had been in production for years was failing at such a high rate that they had stopped the production line. There are few worse notes to get from a factory! The issue was apparently “failure to program” and Great Scott Gadgets immediately requested samples from their manufacturer to debug. What follows is a carefully described and very educational debug session from hell, involving reverse engineering ROMs, probing errant voltage rails, and large sample sizes. [Michael] doesn’t give us a sense for how long it took to isolate but given how minute the root cause was we’d bet that it was a long, long time.
The post stands alone as an exemplar for debugging nasty hardware glitches, but we’d like to call attention to the second root cause buried near the end of the post. What stopped the manufacturer wasn’t the hardware problem so much as a process issue which had been exposed. It turned out the bug had always been reproducible in about 3% of units but the factory had never mentioned it. Why? We’d suspect that [Michael]’s guess is correct. The operators who happened to perform the failing step had discovered a workaround years ago and transparently smoothed the failure over. Then there was a staff change and the new operator started flagging the failure instead of fixing it. Arguably this is what should have been happening the entire time, but in this one tiny corner of the process the manufacturing process had been slightly deviated from. For a little more color check out episode #440.2 of the Amp Hour to hear [Chris Gammell] talk about it with [Michael]. It’s a good reminder that a product is only as reliable as the process that builds it, and that process isn’t always as reliable as it seems.













TLDR version: activating RF power supply put spike on main power. Depending on tolerances, that spike could reset the cpu.
thank you for this
But it’s worth the read if you have the time.
Nothing new. I design automotive hardware, and have to deal with such problems all the time.
When you rapidly switch off a current > 100A, a CPU reset is the least of your problems.
And don’t get me started about manufacturing problems. There’s nothing a fab CAN’T do wrong.
is there a way to activate the rf power supply slowly by maybe ramping up the voltage so instead of being on or off it is like having a light dimmer and turn it up slowly
or even better yet dont enable rf until the chip is programmed
if you would read the post you’ll learn that’s what he did to fix it
So a cap with enough uF to cover the undervolt?
Seems like modular design with sufficient caps/chokes to filter away unwanted RF from DC lines (including generated by digital i/o) , Opto-isolation of modules, etc save so much work and time later. The extra SM components price is below the noise floor vs the price/hr of an EE to fix.
Making the upstream cap C167 bigger than 0.1uF will improve this but the root problem is the cap C105 is probably a ceramic and when powered up will behave like a short until it charges up a little.
I would ensure Q3 the power switching P-channel isn’t switched as fast from off to on. Adding a RC to the gate signal will cause it to spend more time in the linear region of the FET (between fully on and off) when its a higher impedance and thus limits the current and won’t pull down the VCC rail
The right solution is to soft start the supply (which is what he did, essentially) rather than provide more current buffering. Large current transients are bad pretty much no matter what: if you can slow them down, you should. Otherwise even if you avoid problems, you’re still stressing the components. Ceramic caps are great for filtering, but the current surge created when you first connect them is a real problem.
good read and interesting story. always nice to read how others debug and fix issues in their boards
I learnt the importance of microcontroller brown-out detection the hard way, with a device that wiped its own bootloader
https://blog.stevemarple.co.uk/2013/02/the-importance-of-brown-out-detection.html
I now have my firmware output the reason for reset (power applied, watchdog, brown out etc) to the serial debug console.
Is Dave Jones still on The Amp Hour? I want to listen to it, but not if it’s NSFW.
For some reason your article switches fonts in the last paragraph.
When reading the hackaday intro it looked like some epic story behind the scenes.
Alan’s firs post is more of an indication of a rookie mistake.
I learned long ago that resetting a uC is a serious event.
Normally I start each and every uC project with a “Hello World”. It could be a flashing led, a buzzer, a message through Uart, something on a display, Just as it makes clear the uC has been reset.
This has a few goals.
First is, well you have to start somewhere…
If you can blink a led, you can program a uC!
Programming the uC during development happens often, and a “Hello world” gives confidence your toolchain can still program the uC.
And of course it also detects spurious resets, whether from EMI, a bad connector, faulty power supply, brownout or whatever.
Any spurious reset is a serious flaw that needs to be investigated, and having 3% of the devices having random reset issues without it being taken seriously is …
But it starts indeed with being aware of unwanted resets, and hence starting with a startup message.
Had to think back to a recent post on the IBM System/360. They had a “marginal testing” feature, that allowed an operator to slightly vary the power supply voltage up and down, in order to weed out any components that are only “marginally” passing operational testing, but would fail for a supply voltage slightly higher or lower.
You can see the big panel meter prominently on most System/360 front panels, like here on the top left: https://en.wikipedia.org/wiki/IBM_System/360#/media/File:Bundesarchiv_B_145_Bild-F038812-0014,_Wolfsburg,_VW_Autowerk.jpg