Do you use a spell checker? We’ll guess you do. Would you use a button that just said “correct all spelling errors in document?” Hopefully not. Your word processor probably doesn’t even offer that as an option. Why? Because a spellchecker will reject things not in its dictionary (like Hackaday, maybe). It may guess the wrong word as the correct word. Of course, it also may miss things like “too” vs. “two.” So why would you just blindly accept AI code review? You wouldn’t, and that’s [Bill Mill’s] point with his recent tool made to help him do better code reviews.
He points out that he ignores most of the suggestions the tool outputs, but that it has saved him from some errors. Like a spellcheck, sometimes you just hit ignore. But at least you don’t have to check every single word.
Hold onto your hats, everyone — there’s stunning news afoot. It’s hard to believe, but it looks like over-reliance on chatbots to do your homework can turn your brain into pudding. At least that seems to be the conclusion of a preprint paper out of the MIT Media Lab, which looked at 54 adults between the ages of 18 and 39, who were tasked with writing a series of essays. They divided participants into three groups — one that used ChatGPT to help write the essays, one that was limited to using only Google search, and one that had to do everything the old-fashioned way. They recorded the brain activity of writers using EEG, in order to get an idea of brain engagement with the task. The brain-only group had the greatest engagement, which stayed consistently high throughout the series, while the ChatGPT group had the least. More alarmingly, the engagement for the chatbot group went down even further with each essay written. The ChatGPT group produced essays that were very similar between writers and were judged “soulless” by two English teachers. Go figure.
Have you heard that author Andy Weir has a new book coming out? Very exciting, we know, and according to a syndicated reading list for Summer 2025, it’s called The Last Algorithm, and it’s a tale of a programmer who discovers a dark and dangerous secret about artificial intelligence. If that seems a little out of sync with his usual space-hacking fare such as The Martian and Project Hail Mary, that’s because the book doesn’t exist, and neither do most of the other books on the list.
The list was published in a 64-page supplement that ran in major US newspapers like the Chicago Sun-Times and the Philadelphia Inquirer. The feature listed fifteen must-read books, only five of which exist, and it’s no surprise that AI is to behind the muck-up. Writer Marco Buscaglia took the blame, saying that he used an LLM to produce the list without checking the results. Nobody else in the editorial chain appears to have reviewed the list either, resulting in the hallucination getting published. Readers are understandably upset about this, but for our part, we’re just bummed that Andy doesn’t have a new book coming out.
There was a period in the 1990s when it seemed like the personal data assistant (PDA) was going to be the device of the future. If you were lucky you could afford a Psion, a PalmPilot, or even the famous Apple Newton — but to trap the unwary there were a slew of far less capable machines competing for market share.
[Nick Bild] has one of these, branded Rolodex, and in a bid to make using a generative AI less alluring, he’s set it up as the interface to an LLM hosted on a Raspberry Pi 400. This hack is thus mostly a tale of reverse engineering the device’s serial protocol to free it from its Windows application.
Finding the baud rate was simple enough, but the encoding scheme was unexpectedly fiddly. Sadly the device doesn’t come with a terminal because these machines were very much single-purpose, but it does have a memo app that allows transfer of text files. This is the wildly inefficient medium through which the communication with the LLM happens, and it satisfies the requirement of making the process painful.
We see this type of PDA quite regularly in second hand shops, indeed you’ll find nearly identical devices from multiple manufacturers also sporting software such as dictionaries or a thesaurus. Back in the day they always seemed to be advertised in Sunday newspapers and aimed at older people. We’ve never got to the bottom of who the OEM was who manufactured them, or indeed cracked one apart to find the inevitable black epoxy blob processor. If we had to place a bet though, we’d guess there’s an 8051 core in there somewhere.
With only two hundred odd days ’til Christmas, you just know we’re already feeling the season’s magic. Well, maybe not, but [Sean Dubois] has decided to give us a head start with this WebRTC demo built into a Santa stuffie.
The details are a little bit sparse (hopefully he finishes the documentation on GitHub by the time this goes out) but the project is really neat. Hardware-wise, it’s an audio-enabled ESP32-S3 dev board living inside Santa, running the OpenAI’s OpenRealtime Embedded SDK (as implemented by ExpressIf), with some customization by [Sean]. Looks like the audio is going through the newest version of LibPeer and the heavy lifting is all happening in the cloud, as you’d expect with this SDK. (A key is required, but hey! It’s all open source; if you have an AI that can do the job locally-hosted, you can probably figure out how to connect to it instead.)
This speech-to-speech AI doesn’t need to emulate Santa Claus, of course; you can prime the AI with any instructions you’d like. If you want to delight children, though, its hard to beat the Jolly Old Elf, and you certainly have time to get it ready for Christmas. Thanks to [Sean] for sending in the tip.
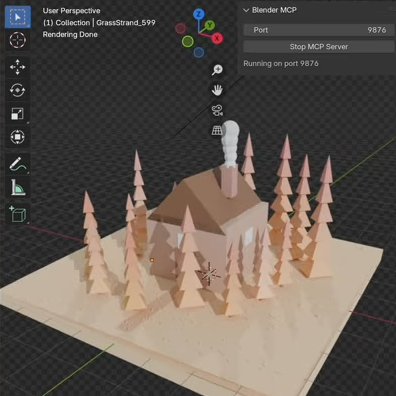
Want to give an AI the ability to do stuff in Blender? The BlenderMCP addon does exactly that, connecting open-source 3D modeling software Blender to Anthropic’s Claude AI via MCP (Model Context Protocol), which means Claude can directly use Blender and its tools in a meaningful way.
MCP is a framework for allowing AI systems like LLMs (Large Language Models) to exchange information in a way that makes it easier to interface with other systems. We’ve seen LLMs tied experimentally into other software (such as with enabling more natural conversations with NPCs) but without a framework like MCP, such exchanges are bespoke and effectively stateless. MCP becomes very useful for letting LLMs use software tools and perform work that involves an iterative approach, better preserving the history and context of the task at hand.
Unlike the beach scene above which used 3D assets, this scene was created from scratch with the help of a reference image.
Using MCP also provides some standardization, which means that while the BlenderMCP project integrates with Claude (or alternately the Cursor AI editor) it could — with the right configuration — be pointed at a suitable locally-hosted LLM instead. It wouldn’t be as capable as the commercial offerings, but it would be entirely private.
Embedded below are three videos that really show what this tool can do. In the first, watch it create a beach scene using assets from a public 3D asset library. In the second, it creates a scene from scratch using a reference image (a ‘low-poly cabin in the woods’), followed by turning that same scene into a 3D environment on a web page, navigable in any web browser.
Back in 2022 we saw Blender connected to an image generator to texture objects, but this is considerably more capable. It’s a fascinating combination, and if you’re thinking of trying it out just make sure you’re aware it relies on allowing arbitrary Python code to be run in Blender, which is powerful but should be deployed with caution.
You’d think a paper from a science team from Carnegie Mellon would be short on fun. But the team behind LegoGPT would prove you wrong. The system allows you to enter prompt text and produce physically stable LEGO models. They’ve done more than just a paper. You can find a GitHub repo and a running demo, too.
The authors note that the automated generation of 3D shapes has been done. However, incorporating real physics constraints and planning the resulting shape in LEGO-sized chunks is the real topic of interest. The actual project is a set of training data that can transform text to shapes. The real work is done using one of the LLaMA models. The training involved converting Lego designs into tokens, just like a chatbot converts words into tokens.
There are a lot of parts involved in the creation of the designs. They convert meshes to LEGO in one step using 1×1, 1×2, 1×4, 1×6, 1×8, 2×2, 2×4, and 2×6 bricks. Then they evaluate the stability of the design. Finally, they render an image and ask GPT-4o to produce captions to go with the image.
The most interesting example is when they feed robot arms the designs and let them make the resulting design. From text to LEGO with no human intervention! Sounds like something from a bad movie.
We wonder if they added the more advanced LEGO sets, if we could ask for our own Turing machine?