
Like most of us, [Peter] had a bit of extra time on his hands during quarantine and decided to take a look back at speech recognition technology in the 1970s. Quickly, he started thinking to himself, “Hmm…I wonder if I could do this with an Arduino Nano?” We’ve all probably had similar thoughts, but [Peter] really put his theory to the test.
The hardware itself is pretty straightforward. There is an Arduino Nano to run the speech recognition algorithm and a MAX9814 microphone amplifier to capture the voice commands. However, the beauty of [Peter’s] approach, lies in his software implementation. [Peter] has a bit of an interplay between a custom PC program he wrote and the Arduino Nano. The learning aspect of his algorithm is done on a PC, but the implementation is done in real-time on the Arduino Nano, a typical approach for really any machine learning algorithm deployed on a microcontroller. To capture sample audio commands, or utterances, [Peter] first had to optimize the Nano’s ADC so he could get sufficient sample rates for speech processing. Doing a bit of low-level programming, he achieved a sample rate of 9ksps, which is plenty fast for audio processing.
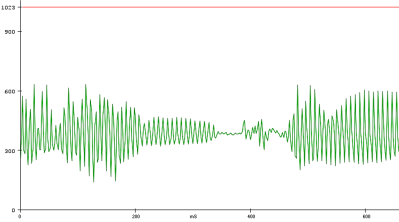
To analyze the utterances, he first divided each sample utterance into 50 ms segments. Think of dividing a single spoken word into its different syllables. Like analyzing the “se-” in “seven” separate from the “-ven.” 50 ms might be too long or too short to capture each syllable cleanly, but hopefully, that gives you a good mental picture of what [Peter’s] program is doing. He then calculated the energy of 5 different frequency bands, for every segment of every utterance. Normally that’s done using a Fourier transform, but the Nano doesn’t have enough processing power to compute the Fourier transform in real-time, so Peter tried a different approach. Instead, he implemented 5 sets of digital bandpass filters, allowing him to more easily compute the energy of the signal in each frequency band.
The energy of each frequency band for every segment is then sent to a PC where a custom-written program creates “templates” based on the sample utterances he generates. The crux of his algorithm is comparing how closely the energy of each frequency band for each utterance (and for each segment) is to the template. The PC program produces a .h file that can be compiled directly on the Nano. He uses the example of being able to recognize the numbers 0-9, but you could change those commands to “start” or “stop,” for example, if you would like to.
[Peter] admits that you can’t implement the type of speech recognition on an Arduino Nano that we’ve come to expect from those covert listening devices, but he mentions small, hands-free devices like a head-mounted multimeter could benefit from a single word or single phrase voice command. And maybe it could put your mind at ease knowing everything you say isn’t immediately getting beamed into the cloud and given to our AI overlords. Or maybe we’re all starting to get used to this. Whatever your position is on the current state of AI, hopefully, you’ve gained some inspiration for your next project.














I judged high school science fairs in the 1980s. One kid showed up with a functional speech recognition system running on a Sinclair ZX-81 with no other hardware other than a microphone. It could recognize numbers and a few other words, and could run a calculator. Amazing.
Now I wonder what that kid is doing now.
I did the same with a TRS-80 model 1 in the late 70’s. Also sound and speech generation using a PWM like technique on the cassette port using the cassette media as a low pass filter.
He went to work at Stanford Research Institute International, then moved on to Google to head up their speech recognition solutions.
There was a rudimentary speech recognition application for the 68k NeXT computer, called Simon Says. You could train it with spoken commands that would trigger macros. “Simon Says, launch Mail” that kind of thing.
It wasn’t really doing any speech processing, so it didn’t really matter what words you used. I think it was just matching the waveform recorded off the microphone to the previously trained waveform. I don’t think it even used the NeXT’s DSP.
Reminds me a lot of the “voice tags” feature of the Nokia 3310… I could “voice dial” any of 10 different numbers _without an Internet connection_ just by momentarily holding the “answer” button for 1 second.
Worked really well, even in somewhat noisy environments.
Admittedly what we have today is a lot more general, but I was a bit disgusted to find that the equivalent today requires an Internet connection and server processing on Apple/Google servers. In doing all the advanced stuff, we sacrificed the basics.
Many different cellphones used to have a voice dial functionality. Some relied on recording your voice tag for each contact, but I think there were some that used simplified voice recognition algorithms. Dragon, currently owned by Nuance, was first released in 1997 for DOS. And it ran without any Internet quite reliably. It required training, but it worked well. So yeah, it can be done, but why bother when “everyone” has Internet access to get newest ads…
Dragon works well close to the centre of the speech recognition bell -curve. The usability dropped rapidly the further you are from that centre . I live with dyslexia and dysgraphia, and was an early adopter of Dragon dictate , even in it’s first shareware guise. As you can probably tell from my spelling I’m British and my accent was too far from the US-English based initial models and the alter UK specific models ( i am an older person with a vaguely RP accent). my output in checked words per minute each time i tried dragon dictate and even with extensive use the accuracy didn’t rise that far. I really appreciate using google assistant , but would really like to do the STT locally , this project seems to point a way forward for my IOT sensors and actuators , not requiring cloud services. Cheers!
I could easily imagine Plasma Mobile getting such a offline voice recognition feature.
I often wonder if this could be run on a slightly more powerful SoC like an ESP32. I used to run Dragon Dictate on a Pentium 1, single core 166Mhz with 16MB RAM. That’s not too far off from one of those.
And it did a wonderful job actually, along with running all of Windows and Office at the same time.
How about a teensy 4.x?
I seem to recall a simple speech recognition algorithm that relied on the signal’s zero-crossings. Wikipedia says that method can be used to capture pitch, which is an intrinsic part of speech recognition. That may have been from an old article in Byte, but that as SOOO long ago.
As for NOT being able to do a Fourier transform on a Nano, that’s rubbish. It depends on how many data points and whether it’s done in float or integer. Clearly, integer is faster (esp. compared to emulated float on a AVR), and if done right, can be interleaved with the data acquisition, which is something I did in my previous life (I’m retired now). My understanding that the main issue on a Nano or Uno, etc., is that of doing anything that is close to a continuous sampled data signal on an AVR. Sample timing is critical for sampling as any sample jitter translates into nasty smearing of the spectrum (worse than even the quantization error of the ADC or integer math operations).
A Fast Fourier transform (FFT) is essentially a lattice FIR that uses the redundancy in the signal. An “in-place” FFT places the output in the same memory as the input samples. I found a good example in Hal Chamberlin’s “Musical Applications of Microprocessors” back in the mid 80s. Another way to do a single frequency Fourier transform is to use its IIR equivalent, the Goertzel transform (see Wikipedia et al.). But like IIRs in general, there may be stability issues. A Goertzel is probably better for continuous sampling and processing, since it uses past samples to come up with an “estimate” of the current bandpass amplitude. Its coefficients can be tailored to a specific bandwidth and sampling rate.
There was definitely a digitizer in the first five years of Byte, a comparator into one of tge ports on the Apple II. I can’t remember if that was just digitizing, or actual voice recognition.
Steve Ciarcia might have had something in his column. I know he did one on voice synthesis, two methods, one was simple, the other comolicated (with better results).
In “Ciarcia’s Circuit Cellar” (Byte Books) Vol V there is an article: “The Lis’ner 1000” (from Byte, Nov 1984), but it uses a special IC: General Instrument SP1000. There may be other articles by Ciarcia about voice recognition.
Best regards,
A/P Daniel F. Larrosa
Montevideo – Uruguay
card images are on a Smithsonian site, Lis’ner 1000 (Rev. 2.0) User & Assembly Manual is on archive. org
an old article from circuit cellar, speech recognizing using zero crossing rate.
https://www.avrfreaks.net/sites/default/files/Stewart-91.pdf
does not require adc, only single analog filter and analog comparator.
Is there a link to the software as well?
i don’t have it. but the basic principle is quite simple, at least the naive one. around 2005 i help my fiend build avr version with 2 filter and 2 analog comparator. using only simple threshold based classification the result good enough for our purpose.
Seems to be a copy here.
I think the keywords were, “… in realtime.” Of course the discrete Fourier transform can be calculated on any processor. I use to do them on a Commodore 64 back in the 80’s. Anyhow, the FT or FFT is inefficient for the application as it generates way more information than necessary. Most realtime speech coding & recognition uses some form of Linear Prediction along with pitch detection via a few calculations of the data’s autocorrelation. Remember the data window is short; 50ms in this case, but 20ms is very common.
Could have… Oh, wait, he did! Now do it on a ‘555.
I have a vague memory of a 555 being used to digitize voice, but it may be a false memory. I’m thinking sometime between 1975 and 80.
I still have a Covox speech recognition adapter for the Commodore 64 up in my bedroom closet (along with the SX-64 it ran on to do my home automation back in the 80s, when I was just out of school…)
For disconnected speech recognition like you use for command words in a voice-control context, it really wasn’t a hell of a lot worse than my last-generation Echo Dot, though it did require training. But it also did NOT require a connection to the cloud! :-)
You can configure the 555 to function as a PWM generator. The PWM signal can be fed to the computer which measures the duty cycle of the PWM signal. The duty cycle is directly related to the amplitude of the input. In other words, you can configure the 555 to act like a simple Analog to Digital Converter. And in order to digitize speech (or any other form of audio) al you need is an ADC with a sample rate that’s twice as high as the highest frequency you desire to capture.
Now this isn’t the best type of ADC you can make but somewhere around the late 70’s early 80’s it was a very cheap way of making an ADC and because it’s based around very commonly available parts anyone should be able to build it.
These days ADC’s are plenty, high res, fast, cheap and even included in most microcontrollers, so there is really no need these days to use the 555 for this purpose, but it can be a fun experiment if you do want to go retro or have no other options.
You’ll be happy to hear that AI/ML is already possible using Espruino on the micro:bit V2. It uses a very similar MCU to the Bangle.js and we (NearForm) worked with Gordon in Espruino last November to get TensorFlow Lite Micro running on the Bangle along with a sample gesture recognition model.