Once the domain of esoteric scientific and business computing, floating point calculations are now practically everywhere. From video games to large language models and kin, it would seem that a processor without floating point capabilities is pretty much a brick at this point. Yet the truth is that integer-based approximations can be good enough to hit the required accuracy. For example, approximating floating point multiplication with integer addition, as [Malte Skarupke] recently had a poke at based on an integer addition-only LLM approach suggested by [Hongyin Luo] and [Wei Sun].
As for the way this works, it does pretty much what it says on the tin: adding the two floating point inputs as integer values, followed by adjusting the exponent. This adjustment factor is what gets you close to the answer, but as the article and comments to it illustrate, there are plenty of issues and edge cases you have to concern yourself with. These include under- and overflow, but also specific floating point inputs.
Unlike in scientific calculations where even minor inaccuracies tend to propagate and cause much larger errors down the line, graphics and LLMs do not care that much about float point precision, so the ~7.5% accuracy of the integer approach is good enough. The question is whether it’s truly more efficient as the paper suggests, rather than a fallback as seen with e.g. integer-only audio decoders for platforms without an FPU.
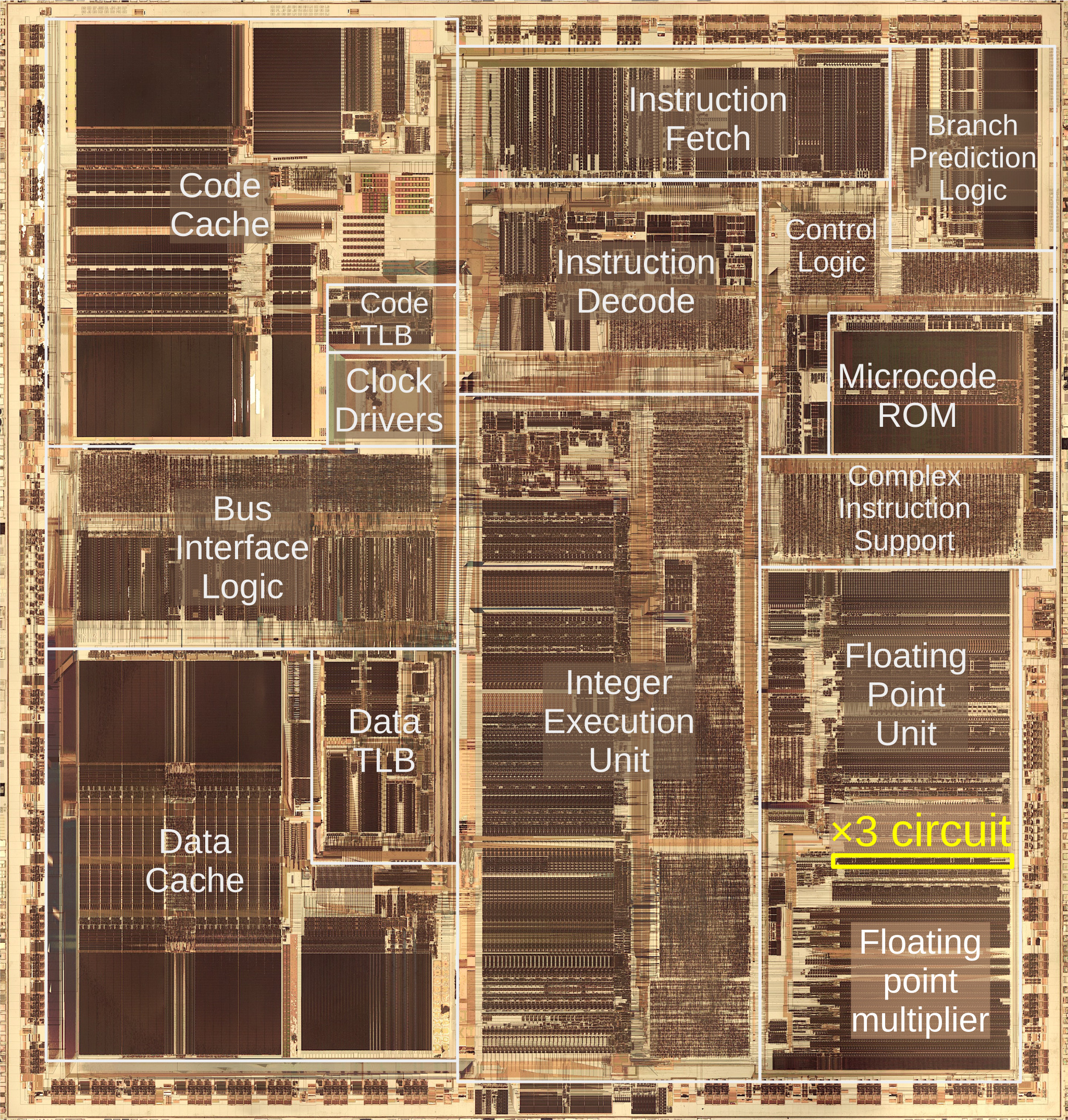
Since one of the nice things about FP-focused vector processors like GPUs and derivatives (tensor, ‘neural’, etc.) is that they can churn through a lot of data quite efficiently, the benefits of shifting this to the ALU of a CPU and expecting (energy) improvements seem quite optimistic.