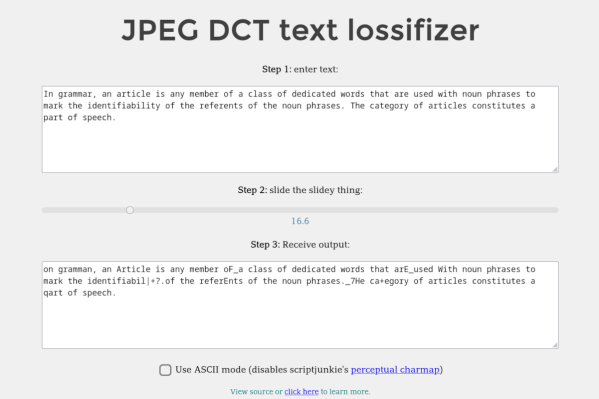
We’ve all been victims of bad memes on the Internet, but they’re not all just bad jokes gone wrong. Some are simply bad as a result of being copies-of-copies, as each reposter adds another layer of compression to an already lossy image format like JPEG. Compression can certainly be a benefit in areas like images and videos, but [Michal] had a bit of a fever dream imagining this process applied to text. Rather than let the idea escape, he built the Lossifizer to add JPEG-like compression to text.
JPEG compression uses a system similar to the fast Fourier transform (FFT) called the discrete cosine transform (DCT) to reduce the amount of data in an image by essentially removing some frequency information. The data lost is often not noticeable to the human eye, at least until it gets out of hand. [Michal]’s system performs the same transform on text instead, with a slider to control the “amount of JPEG” in the output text. The code for this script uses a “perceptual” character map, clustering similarly-looking and similarly-sounding characters next to each other, resembling “leet speak” from days of yore, although at high enough compression this quickly gets out of hand.
One of the quirks that [Michal] discovered is that certain AI chat bots have a much less difficult time interpreting this JPEG-ified text than a human probably would have, which provides a bit of insight into how some of these algorithms might be functioning under the hood. For some more insight into how JPEG actually works on images, we posted about a deep dive into the image format a while back.












