
[Vuong Nguyen] clearly knows his way around artificial intelligence accelerator hardware, creating ztachip: an open source implementation of an accelerator platform for AI and traditional image processing workloads. Ztachip (pronounced “zeta-chip”) contains an array of custom processors, and is not tied to one particular architecture. Ztachip implements a new tensor programming paradigm that [Vuong] has created, which can accelerate TensorFlow tasks, but is not limited to that. In fact it can process TensorFlow in parallel with non-AI tasks, as the video below shows.
A RISC-V core, based on the VexRiscV design, is used as the host processor handling the distribution of the application. VexRiscV itself is quite interesting. Written in SpinalHDL (a Scala variant), it’s super configurable, producing a Verilog core, ready to drop into the design.

From a hardware design perspective the RISC-V core hooks up to an AXI crossbar, with all the AXI-lite busses muxed as is usual for the AMBA AXI ecosystem. The Ztachip core as well as a DDR3 controller are also connected, together with a camera interface and VGA video.
Other than providing an FPGA-specific DDR3 controller and AXI crossbar IP, the rest of the design is generic RTL. This is good news. The demo below deploys onto an Artix-7 based Digilent (Arty-A7) with a VGA PMOD module, but little else needed. Pre-build Xilinx IP is provided, but targeting a different FPGA shouldn’t be a huge task for the experienced FPGA ninja.
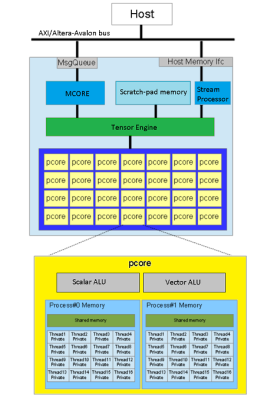
The magic happens in the Ztachip core, which is mostly an array of Pcores. Each Pcore has both vector and scalar processing capability, making it super flexible. The Tensor Engine (internally this is the ‘dataplane processor’) is in charge here, sending instructions from the RISC-V core into the Pcore array together with image data, as well as streaming video data out. That camera is only a 0.3 MP Arducam, and the video is VGA resolution, but give it a bigger FPGA and those limits could be raised.
This domain-specific approach uses a highly modified C-like language (with a custom compiler) to describe the application that is to be distributed across the accelerator array. We couldn’t find any documentation on this, but there are a few example algorithms.
The demo video shows a real-time mix of four algorithms running in parallel; one object classification (Google’s Tensorflow mobilenet-ssd, a pre-trained AI model) canny edge detection, a Harris corner detection, and Optical flow which gives it a predator-like motion vision.
[Vuong] reckons, efficiency wise it is 5.5x more computationally efficient than a Jetson Nano and 37x more than Google’s TPU edge. These are bold claims, to say the least, but who are we to argue with a clearly incredibly talented engineer?
We cover many AI-related topics, like this AI assisted tap-typing gadget, for starters. And not wanting to forget about the original AI hardware, the good old-fashioned neuron, we got that covered as well!
Continue reading “Ztachip Accelerates Tensorflow And Image Workloads”











