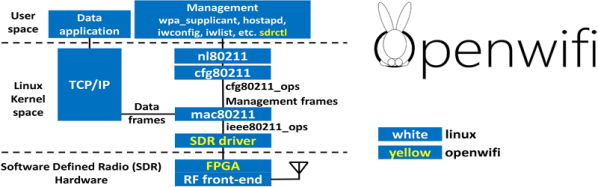
For most people, adding WiFi to a project means grabbing something like an ESP8266 or an ESP32. But if you are developing your own design on an FPGA, that means adding another package. If you are targeting Linux, the OpenWifi project has a good start at providing WiFi in Verilog. There are examples for many development boards and advice for porting to your own target on GitHub. You can also see one of the developers, [Xianjun Jiao], demonstrate the whole thing in the video below.
The demo uses a Xilinx Zynq, so the Linux backend runs on the Arm processor that is on the same chip as the FPGA doing the software-defined radio. We’ll warn you that this project is not for the faint of heart. If you want to understand the code, you’ll have to dig into a lot of WiFi trivia.