AR and VR developer [Skarredghost] got pretty excited about a virtual blue cube, and for a very good reason. It marked a successful prototype of an augmented reality experience in which the logic underlying the cube as a virtual object was changed by AI in response to verbal direction by the user. Saying “make it blue” did indeed turn the cube blue! (After a little thinking time, of course.)
 It didn’t stop there, of course, and the blue cube proof-of-concept led to a number of simple demos. The first shows off a row of cubes changing color from red to green in response to musical volume, then a bundle of cubes change size in response to microphone volume, and cubes even start moving around in space.
It didn’t stop there, of course, and the blue cube proof-of-concept led to a number of simple demos. The first shows off a row of cubes changing color from red to green in response to musical volume, then a bundle of cubes change size in response to microphone volume, and cubes even start moving around in space.
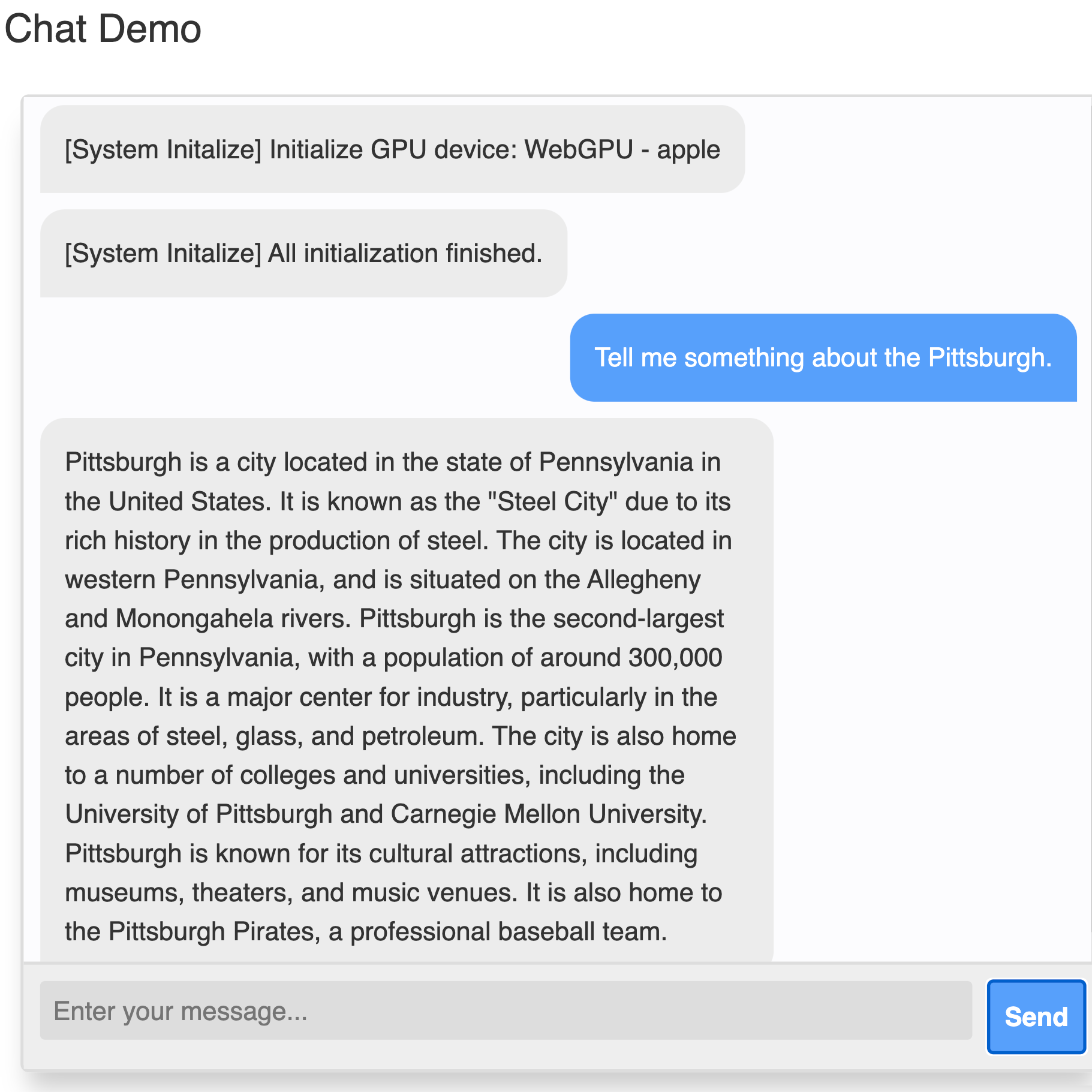
The program accepts spoken input from the user, converts it to text, sends it to a natural language AI model, which then creates the necessary modifications and loads it into the environment to make runtime changes in Unity. The workflow is a bit cumbersome and highlights many of the challenges involved, but it works and that’s pretty nifty.
The GitHub repository is here and a good demonstration video is embedded just under the page break. There’s also a video with a much more in-depth discussion of what’s going on and a frank exploration of the technical challenges.
If you’re interested in this direction, it seems [Skarredghost] has rounded up the relevant details. And should you have a prototype idea that isn’t necessarily AR or VR but would benefit from AI-assisted speech recognition that can run locally? This project has what you need.
Continue reading “Simple Cubes Show Off AI-Driven Runtime Changes In VR”