
Technology frequently looks at nature to make improvements in efficiency, and we may be nearing a new breakthrough in copying how nature stores data. Maybe some day your thumb drive will be your actual thumb. The entire works of Shakespeare could be stored in an infinite number of monkeys. DNA could become a data storage mechanism! With all the sensationalism surrounding this frontier, it seems like a dose of reality is in order.
The Potential for Greatness
The human genome, with 3 billion base pairs can store up to 750MB of data. In reality every cell has two sets of chromosomes, so nearly every human cell has 1.5GB of data shoved inside. You could pack 165 billion cells into the volume of a microSD card, which equates to 165 exobytes, and that’s if you keep all the overhead of the rest of the cell and not just the DNA. That’s without any kind of optimizing for data storage, too.
This kind of data density is far beyond our current digital storage capabilities. Storing nearly infinite data onto extremely small cells could change everything. Beyond the volume, there’s also the promise of longevity and replication, maintaining a permanent record that can’t get lost and is easily transferred (like medical records), and even an element of subterfuge or data transportation, as well as the ability to design self-replicating machines whose purpose is to disseminate information broadly.
So, where is the state of the art in DNA data storage? There’s plenty of promise, but does it actually work?
The Nature of DNA
 We’ve been taught that DNA is the blueprint of life, and that information about how cells are made and interact is encoded in the nucleotides of Adenine, Thymine, Guanine, and Cytosine, held together with their complement in a long chain. When information needs to be gleaned from this database, enzymes pull apart the chain along its length, make a copy of half in RNA, then transfer the RNA to a ribosome where the RNA is mirror copied into the appropriate protein. Think of how powerful that is. Essentially every cell contains the mechanisms needed for reading and writing data.
We’ve been taught that DNA is the blueprint of life, and that information about how cells are made and interact is encoded in the nucleotides of Adenine, Thymine, Guanine, and Cytosine, held together with their complement in a long chain. When information needs to be gleaned from this database, enzymes pull apart the chain along its length, make a copy of half in RNA, then transfer the RNA to a ribosome where the RNA is mirror copied into the appropriate protein. Think of how powerful that is. Essentially every cell contains the mechanisms needed for reading and writing data.
There’s even a mechanism for data integrity. We have multiple chromosomes because if the strands get too long they break in the wrong places, so splitting them up makes sure this doesn’t happen. When the cell divides, the whole chromosomes split in half, and then nucleotides that pair with the half-chain combine with the strand to make two complete copies.
Using DNA Like a Machine
 The way we do it with machines is different. First, the idea that each nucleotide can hold two bits of information doesn’t work. It turns out that some sequences don’t work well and are prone to errors or breaking. In addition, some overhead is required to mark starts and stops and indices. Second, the methods for reading and writing require LOTS of copies. The process involves many amplification steps to generate enough copies of the data that will be pulled apart and analyzed in bulk. The gene science community has made leaps and bounds in the last two decades since the start of the Human Genome Project and the discovery of techniques to rapidly sequence DNA, but it still has a long way to go.
The way we do it with machines is different. First, the idea that each nucleotide can hold two bits of information doesn’t work. It turns out that some sequences don’t work well and are prone to errors or breaking. In addition, some overhead is required to mark starts and stops and indices. Second, the methods for reading and writing require LOTS of copies. The process involves many amplification steps to generate enough copies of the data that will be pulled apart and analyzed in bulk. The gene science community has made leaps and bounds in the last two decades since the start of the Human Genome Project and the discovery of techniques to rapidly sequence DNA, but it still has a long way to go.
The short description of the state of the art is that writing DNA is currently still pretty slow and wet and complicated. Modern biochemistry uses a term called an oligonucleotide, or an oligo, which is a short snippet of DNA or RNA. These oligos are up to a couple hundred bases in length, and usually represent a gene or a set of genes. They are designed and ordered from a few companies (Twist Bioscience and IDT are the big names right now), that essentially take a web form where you upload a text string, and they grow the oligo base by base onto a glass or silicon etched array. A chemical reaction gets the first nucleotide to bind to the substrate, and then there’s a process of heating, exposing to the next base, and cooling to get the next base to bind to the next rung in the ladder. This is repeated until the oligo is complete, which can take some time. This article from Twist is probably the most accessible explanation of the process.
The big advances in the past decade have been in automating this process for ever smaller amounts of liquid, smaller wells, and faster cycles. In 2019 a company called Catalog was able to achieve write speeds of 4 megabits per second using essentially an inkjet printer to deposit bases.
[youtube https://www.youtube.com/watch?v=JG-mrnnD8UY?start=309%5D
Once the oligo generation is done, the scientists have a whole bunch of the same oligo. They typically then perform PCR on it, which is essentially a DNA photocopier machine that rapidly replicates DNA by using an enzyme to convince it to split in half in a juice of bases so that the halves become full strands again, then repeats over and over, a topic we’ve written more deeply on in the past. The other process they do is CRISPR-Cas9, which allows them to take full genomes and cut them in specific locations and splice in the oligos or do other editing.
The good news is that reading this DNA is significantly faster. We used to use the Sanger method of sequencing, which uses fluorescent dyes attached to bases to determine the next base, but the newest hotness is Illumina dye sequencing, which also uses fluorescent dyes, but in parallel instead of serial. Understanding how either of them works broke me, but the gist is that Illumina is way faster and cheaper (relatively speaking) than Sanger. Both are very wet, though, and require lots of chemicals and copies of the strand to be sequenced.
IO Operations and File Structure
It’s shortsighted to think that we’ll always need wet labs and PCR to read and write DNA. The room-sized machines that stored data on magnetic tapes were just as amazing 50 years ago as the room-sized machines that are reading and writing data on DNA now. The problem is that the number of steps and chemical reactions required with DNA operations is significantly higher than magnetic tape. A completely new method of reading and writing will need to be discovered before it can be practical and miniaturized, and when it is and we have the ability to read and write individual molecules at rapid rates, the structure of DNA may not be the best way to do it. All of the advantages of DNA storage are eliminated if the IO requires complicated and expensive machinery.
Understanding and organizing the data is another issue because of the fragility of DNA. One group has come up with a method of storing data called DNA Fountain, which nears the theoretical maximum amount of information. It also takes into account oligo length limits, base pair percentages (can’t have too many GCs to ATs), and long strings of the same base (AAAAAAAAA). The coding structure builds a large number of 38 byte payloads that contain the data, Reed-Solomon error correcting code, and 4 bytes of a random number generator seed that sort of converts into an index, which are turned into oligos. This pile of oligos can then be replicated and sequenced to extract the data and decode it. Current methods of reading and writing DNA aren’t working on full strands and chromosomes; they have tiny little chunks of DNA oligos. Mix two batches of oligos and you may not be able to get your original data back.
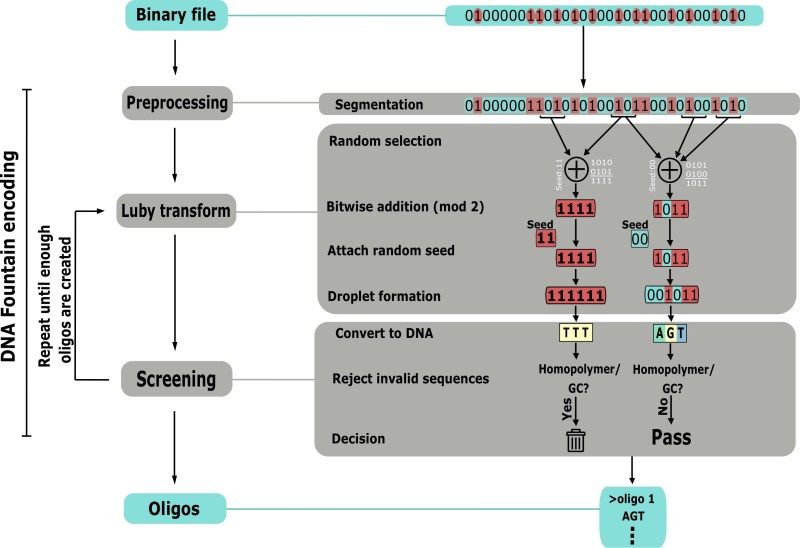
To summarize, building a cell that contains the data you want requires using DNA Fountain to encode the oligos, synthesizing the oligos, using CRISPR-Cas9 to insert the oligos into functional DNA, and then embedding that DNA into a cell. It’s not impossible, but it requires a boatload of expensive equipment.
Backups
Once you’ve settled on DNA as your storage medium, making backups becomes possibly the easiest part of the whole thing, and you can do it right now on the cheap with the PocketPCR thermal cycler. It may make more sense to keep the DNA in cells, though, because they have built in mechanisms for reading and writing the data and making copies, and they protect the DNA. It means some of the DNA must be dedicated to this cell structure, but consider that to be similar to the overhead like you would already have for a filesystem. Having DNA in cells, and specifically in bacteria, means making backups is as easy as not washing your hands after going to the bathroom. In this case, DNA stands for “Dat’s Nasty, Alright?”
Longevity
DNA has been successfully sequenced from a horse that lived roughly 700,000 years ago. With that kind of retention possibility, we can be confident that our backups of the Windows ME ISO could last far beyond a computers’ ability to run it, and our tweet history will baffle anthropologists for millennia. Of course, we don’t know if this kind of longevity can be exceeded using existing technology, but some research has been done to figure out how to make sure the DNA doesn’t break down much sooner than that.
DNA stands for Denatures Near Jalapenos (the J is silent), though, and unravels when things get hot, between 70-100C. That makes it hardly better than regular electronic devices, and it’s got the extra vulnerability to UV light as well. To get around these problems, the DNA can be encased in silica and titanium dioxide. The neat thing is that DNA isn’t really harmed by some organic solvents, so it’s possible to dissolve away the silica and extract the DNA relatively easily. These extra steps make it unsuitable for rapid data access, though, and makes duplication impossible while encapsulated, so for short term storage the DNA still has to be exposed.
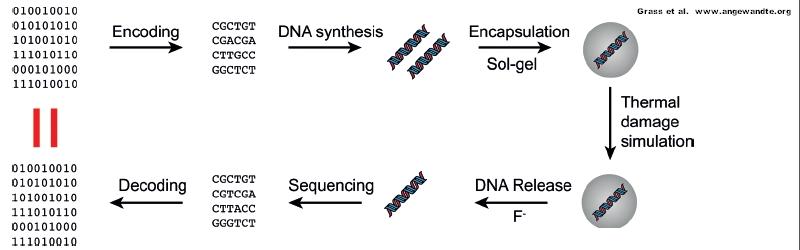
Conclusions
DNA, short for Discovering New Acronyms, is a data storage technique developed over hundreds of millions of years, and it’s very good at what it does. Electronics developed by humans pale in comparison to the capabilities of cells in many ways, but excel in others. Will it be possible to bridge the gap and use aspects of each to create even better machines? Considering the timeline of progress, we’re much closer now to mastering that bridge than we were when the structure of DNA was discovered in 1952 and the transistor was invented in 1947, and we will likely be able to miniaturize and speed up the interface significantly further in the decades ahead, to the point of being commercially viable. We may see a new Moore’s Law emerge with respect to interfacing molecular data storage.
In other words, this could become a real thing. At the moment the process of writing and reading DNA is way too slow and requires too many chemical processes and reactions, but it’s commonplace enough that people are now regularly doing fun things like embedding videos in DNA and embedding the gcode in 3D printed rabbits.
A completely new paradigm of IO is necessary to make it work. It’s possible DNA isn’t the best way to do it in favor of another molecular storage mechanism that’s more silicon friendly. What evidence of our civilization do you think will survive tens of millions of years? The only real evidence left over may just be our fossils and our DNA, which makes me wonder if maybe the common cold is an encoded video of a dinosaur dancing that went viral in more ways than one.














Went to school with a guy that is a ‘computational biophysicist’ (whatever that is). He claims that DNA research is being (unwittingly) held back by principle researchers that do not have the math or chemistry or physics necessary to make the next leap forward.
That’s true in many sciences, having to wait for the tenured professors to retire or die to make any progress.
Max Planck had it figured out long ago…
In reality, it’s the student’s inability to explain why their idea is the next leap forward. And those principle researchers are not about to listen to anything other than hard proof. Which means that the junior researcher just as well does not have the math, chemistry or physics to make the next leap forward, AND doesn’t have the ability to explain himself either.
So neither the principal nor the junior is able to make the next leap forward. Per definition. Because if any of them WAS able to make that next leap forward, it would be made immediately.
So, your guy is only blaming others for his own inabilities. And if he doesn’t see that himself, he will never be the one to make the next leap forward.
And if he does gain the ability see his own inabilities, there is still no guarantee that he will be the guy to make the next leap forward. But at least he would have a chance, which now he doesn’t.
Just a reality check for anyone who believes that he is held back by more senior people: if those senior people are able to successfully hold you back, it means that you’re still lacking skills that they do have.
Perhaps.
But then again… that’s exactly what an old person who is holding progress back would say!
;-)
(Staying out of this debate as I am handicapped by actual knowledge, but this is not really an accurate assessment)
An accurate assessment here?
Good Lord! What rock have you been hiding under…
https://www.irishtimes.com/news/science/monaghan-scientist-involved-in-molecular-computing-breakthrough-1.3832929
Related article on dna computing and using DNA to form gates and algorithms
https://www.nature.com/articles/s41586-019-1014-9
“The human genome, with 3 billion base pairs can store up to 750MB of data. In reality every cell has two pairs of chromosomes, so nearly every human cell has 1.5GB of data shoved inside.”
What?!?!
No.
Humans have 23 chromosomes, not 2. You might be thinking specifically of the sex chromosomes. We have two of those. Regardless, each chromosome contains it’s own subset of those ~3-billion base pairs, not 3-billion each. Chromosomes don’t really factor into the calculation you are making here.
“You could pack 165 billion cells into the volume of a microSD card”
Ok. But you wouldn’t store unique data on individual cells. It would be way too hard to retrieve any specific one. Also, if each cell contained different data you would be constantly losing data as cells die and duplicating it as cells divide. You would start out with your exobytes of unique data and in a short time much of that data would be gone while other parts of it would be duplicated. Most likely you would store a homogeneous culture with every cell containing the same data or perhaps there would be a few chambers with one set of data per chamber.
Also.. it kind of sounds like you are talking about completely using the genome of living cells for storage. Your cells aren’t going to last very long without their necessary genes! That’s why most talk about using DNA for storage and/or computing involves using only DNA, without the cell then duplicating it artificially using PCR.
I’m sorry, I don’t intend to be mean but that was cringy, almost like a Ken Ham video.
https://en.m.wikipedia.org/wiki/Human_genome#Information_content
I stand by my statement about information content of a normal human diploid cell.
There is effort into creating a minimum viable reproducing bacteria cell, and they have accomplished it in only 473 genes. That leaves a lot of room for extra data; enough that the 1.5gb isn’t really affected by it.
Finally, the point of that paragraph is to illustrate the magnitude of data density, which is far beyond our current capability. The rest of the article discusses the realities of trying to use that density and points out exactly some of the things you mention.
“Humans have 23 chromosomes, not 2. ”
Speaking of “cringy” would you like to take another crack at that?
Not sure where you got the impression I said we have two. There are 3 billion base pairs, spread across the 23 chromosomes, totalling 750MB. Multiply by 2 to get the doubled up chromosomes and you have 1.5GB of data stored in the nucleus. The fact that the data is mostly duplicate doesn’t matter; the point of the paragraph was to highlight the density of the data.
I see what happened. I meant 2 sets, not 2 pairs. Also, can we move on from this and talk about the whole rest of the article?
What, after he’s got his pet peeve wet AND fed it after midnight?
23 is still wrong. This is not rocket surgery.
humans have 23 PAIRS of chromosomes so 46 chromosomes in total.
“In reality every cell has two pairs of chromosomes[.]”
It’s interesting to speculate how long it would take the light from “Correct” to reach the above statement. Too bad, now I’ll never know if the rest of the article was as interesting as I had hoped.
Sperm snob!
“In reality every cell has two pairs of chromosomes[.]”
Ooops, just read that again, either a plant wrote this or it’s wrong, sorry.
Wait… 1.6GB is all that defines us? So in a world of ~8G people, there are four of each person?
Um. No.
The number of combinations that can be made from x-bits of information is not x. It’s the number of values possible in each (4 in the case of DNA) to the power of x. That’s a lot of combinations!
Of course, not every combination of C, G, A and T makes a viable organism. No doubt the vast majority do not. But still, I bet the actual possible combinations of human genes is greater than 8 billion.
“The human genome, with 3 billion base pairs can store up to 750MB of data”. Amazing that the whole of a human being can be fit into a USB stick that you can buy in a dollar store.
No, just a human’s genes. You are leaving out every environmental effect that guides a person’s development.
For example, I once read that a person’s unique fingerprint (not even shared by an identical twin) is created by the swirling of fluids around the skin as it first develops in the womb. Think how much information is encoded in just that!
And of course there is the elephant in the room, all the neural connections that make up a person’s thoughts and memories.
Still the entire blueprint for the quintessence of dust in what would be considered poor storage for a cell phone still makes one think.
DNA alone is no real solution. It is the process of constantly duplicating and error checking data while keeping distributed copies, that gives you long term archives, and this requires a constant expenditure of energy, basically you are fighting off entropy and there is no way around that requirement thanks to how this universe works. Those inconvenient laws of physics being what they are…
And even if you work out a long-term self-sustaining archiving system, the next challenge would be preventing your data from mutating and evolving, which would amount to data corruption. This is a problem which hasn’t even been fully solved in nature, as all living things are susceptible to cancer, although a few have mechanisms for quickly arresting cancer growth. In fact in nature DNA copy processes are always imperfect, just usually not imperfect enough to cause a serious problem in a living thing.
” Maybe some day your thumb drive will be your actual thumb. The entire works of Shakespeare could be stored in an infinite number of monkeys. DNA could become a data storage mechanism!”
Sex could be referred to as a…data dump. Shedding skin cells would be the mother of all data leaks.
Wouldnt it be DKA since knowledge is spelled with a k…
Am I crazy or did they NOT show how they go about reading this juice bottle full of data? or even whether or not there is some sort of output? I see the input/write stage, I see the storage stage, I do not however see a feasible way to access this data on the fly…?
Reading would probably have to be done via the current DNA sequencing techniques, which certainly have their limits. As the article concludes, a brand new way of working with DNA is required if this is ever going to be useful.
>We used to use the Sanger method of sequencing, which uses fluorescent dyes attached to bases to determine the next base, but the newest hotness is Illumina dye sequencing, which also uses fluorescent dyes, but in parallel instead of serial. Understanding how either of them works broke me
Sanger is conceptually easy: you mix the DNA with a soup of things which will replicate the DNA, including the nucleotides. A small proportion of each of the nucleotides is a chemically altered version which prevents the DNA being extended any further and fluoresces a different colour (these are called dye-terminators). So there’s a chance that any time a nucleotide is incorporated into a growing DNA chain that the A/T/C/G used is a dye-terminator and that particular chain will not extend any further. The result is millions of copies of the DNA, each one truncated at a particular nucleotide and now fluorescing a colour corresponding to that nucleotide. If you sort these by length (easily done by electrophoresis) and check the fluorescence you can read the order of the colours, which correspond to A, T, G or C.
This relies on getting the proportion of dye terminators just right to generate a dyed version of every nucleotide in the sequence, and having an electrophoresis system which can accurately sort DNA strands with single-basepar differences in length, but that was solved a good while ago.
Illumina is more complex, and reads much shorter lengths of DNA than Sanger but is massively paralell.
I’m surprised you didn’t mention Nanopore, seeing as that is the current hotness and can be done using far, far smaller machines (USB dongle sized: https://nanoporetech.com/products). This reads much longer chunks of DNA than Illumina but has some serious accuracy issues, so it often gets combined with Illumina to make it easier to reconstruct a whole genome from Illumina’s tiny fragments (150-250 base pairs, I think the record for Nanopore is in the millions of base pairs for a single fragment now, but routinely you’d get something in the kilobase range read from a chunk of DNA).
https://www.extremetech.com/extreme/134672-harvard-cracks-dna-storage-crams-700-terabytes-of-data-into-a-single-gram
Interesting and informative. But Data Knowledge Accumulation to DKA…pedantic, yes but accurate.