There are basically two ways to compute data. The first is with a DSP, a chip that performs very specialized functions on a limited set of data. These are very cheap, have amazing performance per watt, but can’t do general computation at all. If you’d like to build a general-purpose computer, you’ll have to go with a superscalar processor – an x86, PowerPC, or any one of the other really beefy CPU architectures out there. Superscalars are great for general purpose computing, but their performance per watt dollar is abysmal in comparison to a DSP.
A lot of people have looked into this problem and have come up with nothing. This may change, though, if [Ivan Godard] of Out-of-the-Box computing is able to produce The Mill – a ground-up rethink of current CPU architectures.
Unlike DSPs, superscalar processors you’d find in your desktop have an enormous amount of registers, and most of these are rename registers, or places where the CPU stores a value temporarily. Combine this with the fact that connecting hundreds of these temporary registers to places where they’ll eventually be used eats up about half the power budget in a CPU, and you’ll see why DSPs are so much more efficient than the x86 sitting in your laptop.
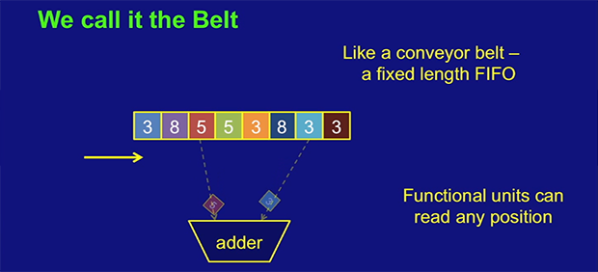
[Ivan]’s solution to this problem is replacing the registers in a CPU with something called a ‘belt’ – basically a weird combination of a stack and a shift register. The CPU can take data from any position on the belt, perform an operation, and places the result at the front of the belt. Any data that isn’t used simply falls off the belt; this isn’t a problem, as most data used in a CPU is used only once.
On paper, it’s a vastly more efficient means of general purpose computation. Unfortunately, [Ivan] doesn’t quite have all the patents in for The Mill, so his talks (two available below) are a little compartmentalized. Still, it’s one of the coolest advances in computer architecture in recent memory and something we’d love to see become a real product.
Continue reading “The Mill CPU Architecture” →