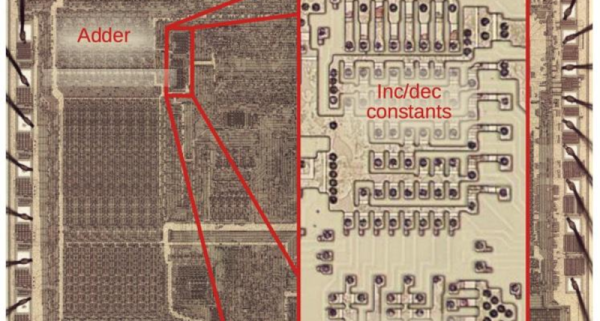
One of the interesting features of the 8086 back in 1978 was the provision for “string” instructions. These took the form of prefixes that would repeat the next instruction a certain number of times. The next instruction was meant to be one of a few string instructions that operated on memory regions and updated pointers to the memory region with each repeated operation. [Ken Shirriff] examines the 8086 die up close and personal to explain how the 8086 microcode pulled this off and it is a great read, as usual.
In general, the string instructions wanted memory pointers in the SI and DI registers and a count in CX. The flags also have a direction bit that determines if the SI and DI registers will increase or decrease on each execution. The repeat prefix could also have conditions on it. In other words, a REP prefix will execute the following string instruction until CX is zero. The REPZ and REPNZ prefixes would do the same but also stop early if the zero flag was set (REPZ) or not set (REPNZ) after each operation. The instructions can work on 8-bit data or 16-bit data and oddly, as [Ken] points out — the microcode is the same either way.
[Ken] does a great job of explaining it all, so we won’t try to repeat it here. But it is more complicated than you’d initially expect. Partially this is because the instruction can be interrupted after any operation. Also, changing the SI and DI registers not only have to account for increment or decrement, but also needs to understand the byte or word size in play. Worse still, an unaligned word had to be broken up into two different accesses. A lot of logic to put in a relatively small amount of silicon.
Even if you never design a microcoded CPU, the discussion is fascinating, and the microphotography is fun to look at, too. We always enjoy [Ken’s] posts on little CPUs and big computers.