
Speaking is much faster than typing, and while it’s an increasingly convenient way to interact with computers, it’s hardly private. Providing speech privacy in a way we haven’t seen before is this prototype tongue-reading system that uses machine learning and ultrasound to read tongue movements and turn them into decoded speech. Not only can a user speak without emitting a sound, since it doesn’t read sound waves it’s completely immune to noisy environments.
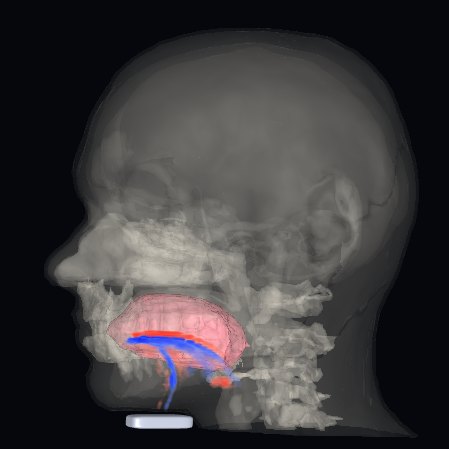
It turns out that tongue movements are a very rich source of information about speech, and an ultrasound probe under the chin takes very clear video of a tongue. With a dataset consisting of only around 50 hours of training data, the system has a 15.6% error rate and generalizes across different speakers (as long as they speak with similar accents).
That error rate may seem high at first glance, but keep in mind this is for a prototype system built in a month around a relatively small training dataset. All indications are that better results are just a matter of better training.
Probably the biggest drawback at the moment is the size of the ultrasound probe and the way it must be held under one’s chin like a contact microphone, but at the moment the probe is an off-the-shelf model that is hardly optimized for either size, weight, or wearability. If the system seems promising enough, a probe resembling an adhesive patch might even be possible.
It’s certainly a different approach from others we’ve seen in the past, including whispering while inhaling and reading lip and mouth movements.














