
Nvidia is back at it again with another awesome demo of applied machine learning: artificially transforming standard video into slow motion – they’re so good at showing off what AI can do that anyone would think they were trying to sell hardware for it.
Though most modern phones and cameras have an option to record in slow motion, it often comes at the expense of resolution, and always at the expense of storage space. For really high frame rates you’ll need a specialist camera, and you often don’t know that you should be filming in slow motion until after an event has occurred. Wouldn’t it be nice if we could just convert standard video to slow motion after it was recorded?
That’s just what Nvidia has done, all nicely documented in a paper. At its heart, the algorithm must take two frames, and artificially create one or more frames in between. This is not a manual algorithm that interpolates frames, this is a fully fledged deep-learning system. The Convolutional Neural Network (CNN) was trained on over a thousand videos – roughly 300k individual frames.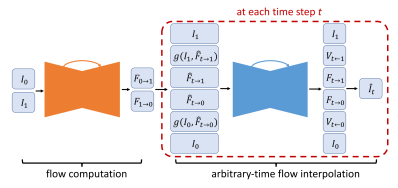
Since none of the parameters of the CNN are time-dependent, it’s possible to generate as many intermediate frames as required, something which sets this solution apart from previous approaches. In some of the shots in their demo video, 30fps video is converted to 240fps; this requires the creation of 7 additional frames for every pair of consecutive frames.
The video after the break is seriously impressive, though if you look carefully you can see the odd imperfection, like the hockey player’s skate or dancer’s arm. Deep learning is as much an art as a science, and if you understood all of the research paper then you’re doing pretty darn well. For the rest of us, get up to speed by wrapping your head around neural networks, and trying out the simplest Tensorflow example.














This is cool for making cool demos, but not useful for anything where slow motion is actually useful. It can’t add information that isn’t there, so for answering questions like, Who won the race? or, Was the bar grounded before the wicket was broken, this is literally just making it up. It won’t stop people trying to use it to “prove” their team should have won, though.
Slow motion is useful for dramatic effect. And in those cases, accuracy is not terribly important.
That’s right, you KNOW that this sort of technology WILL be used for determining who won the race.
Sorry to be the “slippery slope” guy, but it’s bad enough that CG is at the point where it takes serious analysis to determine whether or not something is real, and this just adds to the problem. Congratulations Nvidia, we can officially no longer believe anything we see.
Nah i dont think so.
For things like race winning you already have polynomial interpolation (AKA taylor series expansion) rather than linear interpolation. And this is frequently used for determining such things, simply by looking at position+velocity+acceleration (+jerk if needed & accurate enough) profiles rather than just position profiles.
So I really don’t think this will substitute that, instead what i just described will be used in this algorithm to improve the slomo effect- such that for instance that skate will no longer have an insane acceleration at one point.
My point wasn’t that this would be a good tool for that. My point was that even though this is a completely unsuitable tool and there are better tools, it will be on people’s phones, and that’s what will get used.
The information is there to some extent though. Things like velocity and acceleration of an object can be determined, which will determine which thing will happen first.
For it to even look right most of this physics “knowledge” must be there.
Sure, if the *only* reason you can think of for doing slomo is for formal scientific research.
I don’t know if what the Slo-Mo guys are doing counts as anywhere near that.
Also, if you speed it back up you can also use it for better high-framerate results than the current kinda-shitty algorithms that modern TV’s use to interpolate broadcast content up to 100Hz.
“it can’t add information that isn’t there” is exactly what it does. To take your example of a race: With traditional methods one would have to call it a draw, which in some cases is an acceptable outcome. Using this method however it will use the data that is there to make up a statistically probable outcome based on what is known. In many cases this would be preferable to a draw.
It’s not adding any information which isn’t there. In the race example, all it’s doing is interpreting the existing information. With the race, you could use the existing frames to determine average velocities and accelerations, and then determine who was most likely to have crossed the line first. That’s all this is doing, but in a visual way. It’s still very impressive, though, and will be useful for the purpose of cinematography – where you care about how it looks, but not about how accurate it really is.
extrapolating existing frames into subframes. your brains do the exact same thing.
Determining the winner of a contest represents a very tiny portion of how slow-motion footage is used.
I sure hope I get to throw this into AE some day so I don’t have to keep relying on pixel motion’s janky shenanigans every time I need to time-remap something because a client can’t be bothered to time things correctly on set.
Yah interpolated data would be useless for any thing other than making slow motion for dramatic effects and even there it may not cut the mustard.
Is ‘Deep Learning” like going to university, then working in industry for some time or more like standardised extrapolation using a cost effective set of ‘rules’. The special effect is fun but the marketing speak is atrocious.
I think this is deeply disturbing.
Let me explain. We’re seeing this kind of approach already applied in photography: the tiny sensors in smartphones aren’t up to the task of taking good photos. Plus, the photographers are folks like you and me, and not highly trained experts. So taken face-value, the results, as-is would be horribly mushy things. You can’t sell a premium smartphone like that.
But those smartphones have processing power…
That’s all that “…taken with an iPhone 6” thing. There’s already a lot of canned models generated with machine learning in those things.
Half in jest I tell to my friends: actually the smartphone doesn’t need a camera sensor at all. Just its geocoordinates and current attitude (accelerometer + compass), a bit of Google Street View, a dash of video surveillance data (enough cameras with open ports, ask Shodan), and Da Goog knows how the scene should look like.
Now to the disturbing part: those things aren’t showing us “what’s there”, but “what the model ‘thinks’ is there”, without us suck^H^H^H^H end-users having much insight in, let alone control over that model (heck, the device manufacturer itself doesn’t probably know what’s exactly in those models).
How is that going to influence our perception of the world?
I don’t like that idea very much.
You don’t see what’s actually there either. If you did optical illusions wouldn’t work.
And even what you see changes what you hear (“The McGurk Effect”). https://www.youtube.com/watch?v=G-lN8vWm3m0
Maybe it´s just because of my problem with understanding speech properly, but I don´t perceive any change whatever he does with his mouth. In real world scenario, I wouldn´t understand whether he said “baa”, “paa” or “daa” or whatever he is saying and I would decide later depending on the context of what he says (yes, it causes me some serious problems in communication with people who do not articulate well or speak too silently). And I don´t know what sound should those movements of his mouth make. Maybe that´s why it doesn work on me.
That’s right, and I thought of that too.
Actually it is a good analogy to what is happening. Our vision system, starting from the several layers in the retina and passing through the visual cortex is already a complex system with tons of quirks to help us understand what we “see”, and which has its big share of quirky, sometimes funny failure modes.
The difference is that the natural vison “is there”, and can be (and is) investigated, and we have a solid body of research on it.
“We” (that is, our conscience, our judgement) have co-evolved with it for… uh… ages.
This new “perception filters”, if you allow the term, are emerging so quickly that we’re bound to see “interesting” effects.
“Interesting” in the sense of the (reportedly apocryphal) Chinese curse.
Yes. It’s another example of “Humans need not apply.”
That’s exactly how a normal brain works.
We don’t see (perceive) what is actually there, but just a rough draft, or model, of the reality. Then the brain completes the image with details and ‘stuff’ added from our own individual past experiences of similar circumstances. This happens at all the time scales, from the range of ms to the range of long term memories and history.
Right now, we are on the path of externalizing our own “brains’ main job” to an AI. Controlled by just a few.
It won’t happen over night, but it’s just a matter of time.
This will be disruptive in many, many ways.
Your concerns are fully entitled.
Welcome to THE HIVE!!!
:o)
What you said is true, but less applicable to the human vision system than it is to memory.
What twixtor does for decades now. And not even better.
This concept could have a bit further usefulness than an aftereffects plugin.
Push all the Jupiter footage through it!! :D
There is already software that can do this, e.g. http://slowmovideo.granjow.net/
So the main difference is that this is now done with machine learning. Would have been nice for them to have a comparison against existing state-of-the-art interpolation programs.
The biggest gotcha is that to get good results, you need to have a source video with global shutter camera and short exposure time. A typical mobile phone video will have way too much motion blur and distortion to yield anything except a blurry object moving across the screen.
Ah, the actual paper has a comparison.
Most of my work is in mograph, and in all my experience the existing “pixel motion” slo-mo algorithms can be useful for little changes, but they need a lot of hand-holding and sometimes do extremely strange things. They would never be able to do a 1:7 frame ratio, that’s insane.
I can’t wait until I can get my hands on this tech myself. Hopefully it actually sees the light of day; I’m sure nvidia will license it somehow. Or provide it free with their AI hardware?? :-)
The ultimate, end earliest, slo-mo was an artist trying to depict a galloping animal. For centuries skilled artists all over the world studied the movements of the legs and tried to work out how they could be depicted. No one succeeded although everyone recognized that the image signified a galloping animal. The real movement of the galloping legs was finally known after a series of still photographs were obtained showing the movement with sufficient clarity and with a sufficiently short time interval between each photograph.
I don’t think any form of ‘deep learning’ is going to change the problem for Nvidia, blurry images at a low frame rate will not show what really happened, no matter how pleasing the special effect is.
As mentioned above, hopefully this leads to better motion interpolation in TVs. The garbage algorithm in every 120 Hz set I’ve seen is unwatchable for me. The “soap-opera effect” is so pronounced that I’ve taken to disabling it on friends’ TVs.
Also, I wonder if this could lead to nicer de-interlacing techniques…
Im pretty sure that’s what the real end game is here.
The frame rate itself is to blame for the soap opera effect. It doesn’t matter if it’s captured in a proper 60 or 120 FPS camera or interpolated from 29.97, all live-action footage at a high frame rate causes a soap opera atmosphere because that’s where you’re used to seeing it. It will go away as we start getting used to more content being presented at that speed.
Same with how 24 FPS looks cinematic compared TV’s 29.97. That effect is all in the frame rate itself and your preconceptions and memories.
NTSC is a 60Hz format, not a 30Hz format. It simultaneously displays 480 lines (although poorly) and updates the picture every 1/60th of a second. (Visually, 480i is closer to 240p60 than 480p30—too high of a vertical resolution will visibly flicker)
The difference between 24frame-per-second film and 30Hz isn’t so huge that we’d notice an obvious difference. But the difference between 24fps and 60Hz is.
rnjacobs: Incorrect. NTSC updates only 240 lines (actually 241.5, but not everybody implements it that way), 60 times a second. The odd-numbered lines, then 1/60 second later, the even-numbered lines. That’s what’s meant by “interlaced”.
I think we’re enthusiastically agreeing.
(my “simultaneously” was describing the format as a whole, not each individual field)
Okay.
If it can be done on low cost hardware that could be a good use for it.
Another use would be doing a better conversion between 24 frames per second and 30 or 60 fps or doing conversion of interlaced to non interlaced.
I want AI, actually a motion stabilizer algorithm to stop the “caffeinated cameraman handheld crap’ that permeated network TV when it became possible. The degree of shaking on TV’s digital soaps is like in a classic film, a scene on a boat in storm or earthquake! I have to look away from a big screen of it.
Sports and documentaries will benefit from high frame rate and definition, for all the fake holeywood stuff a foggy view is just you want to believe in. High frame rate sans MPEG won’t look right next to movies yet alone soaps.
We are really just tossing that AI term around now aren’t we? How are yesterdays’ analytical algorithms versus today’s analytical algorithms now ‘intelligence’? It is no more independent than before … in fact is requires even more to accomplish it … we are letting the term be repackaged by marketeers.
Welcome to the second AI bubble. Neural network training really can be thought of as the computer learning and thinking for itself a bit in the hidden layer, as opposed to a strict interpretation of human input as with traditional algorithms programmed by humans.
Are you perhaps mistaking AI for AGI? Most people do that.
I appreciate that you are using the specific terms of the ‘AI’ field, I am not arguing with that and certainly not arguing with what you are saying. My argument is with the plain language versions of the words, in plain English artificial intelligence means science fantasy stuff like Robbie the robot, or robots themseves, and Robbie the robot etc is very far in the future and probably never because other solutions will be more useful.
My opinion is that ‘Garbage in, garbage out” is a reality and that “Garbage in, neatly polished, almost cute garbage out” is what is being promised by the marketing guys.
Only works with short exposures. In conditions where light is limiting it doesn’t work, obviously. Probably a nice effect for smartphone cameras that will flood social media in the future.
Marketing stuff again from HaD.